|
|






 Arabic
Arabic Bengali
Bengali Chinese
Chinese English
English French
French German
German Hebrew
Hebrew Hindi
Hindi Italian
Italian Japanese
Japanese Korean
Korean Malay
Malay Polish
Polish Portuguese
Portuguese Spanish
Spanish Turkish
Turkish Ukrainian
Ukrainian Vietnamese
Vietnamese|
강의 요약, 유아용 침대
통계. 치트 시트: 간략하게, 가장 중요한
차례
통계의 일반 이론 주제 1. 과학으로서의 통계 1.1. 사회과학으로서의 통계학의 주제와 방법 인간의 본성에는 지식의 특별한 분야인 과학의 연구와 개발에서 표현되는 세계에 대한 지식에 대한 열망이 있습니다. 각 과학은 현실 세계의 현상에 시선을 돌리면서 한 과학을 다른 과학과 구별하는 특정 기능을 개발합니다. 모든 과학의 본질은 지식의 대상과 주제에 있으며, 다른 과학은 하나의 지식 대상을 가질 수 있지만 다른 주제를 가질 수 있습니다. 과학의 대상은 과학이 지식을 확장하는 현실 세계의 현상입니다. 과학의 주제는 현상의 일부 또는 대상의 일부 영역과 관련된 연구 대상에 관한 특정 범위의 질문입니다. 과학의 주제를 명확히 할 때 주어진 과학이 무엇을 연구하고 있는지에 대한 질문이 해결됩니다. 과학 주제를 연구하는 원칙과 방법은 방법론을 구성합니다. 통계학은 사회 생활의 필요에서 나온 자체 주제와 연구 방법을 가진 독립적 인 사회 과학입니다. "통계"라는 용어는 "위치, 순서"를 의미하는 라틴어 "status"에서 유래했습니다. 그것은 독일 과학자 G. Achenwal(1719-1772)에 의해 처음 사용되었습니다. 현재 "통계"라는 용어는 세 가지 의미로 사용됩니다. - 국가, 지역, 경제 또는 기업의 개별 부문을 특징짓는 데이터를 수집, 처리 및 분석하는 것을 목표로 하는 사람들의 실질적인 활동의 특별 부문 - 통계적 실천에 사용되는 이론적 규정 및 방법의 개발을 다루는 과학; - 기업, 경제 부문의 보고에 제시된 통계 데이터 및 컬렉션, 다양한 디렉토리, 게시판 등에 게시된 데이터 통계의 대상은 사람들의 사회 경제적 관계를 반영하고 표현하는 사회 사회 경제적 생활의 현상과 과정입니다. 연구 대상에 따라 과학으로서의 통계는 여러 블록으로 나뉩니다(그림 1). 
산업통계 그림. 1.1. 통계학의 구조 통계 일반 이론은 모든 부문별 통계의 핵심인 방법론적 기초이며, 사회 현상에 대한 통계 연구의 일반 원리와 방법을 개발하며 통계의 가장 일반적인 범주입니다. 경제 통계의 임무는 국가 경제의 상태, 산업의 관계, 생산력 분포의 특성, 물질, 노동 및 재정 자원의 가용성을 반영하는 종합 지표의 개발 및 분석입니다. 사회 통계는 인구의 생활 방식과 사회적 관계의 다양한 측면을 특성화하는 지표 시스템을 형성합니다. 일반적으로 통계는 성격이 다른 정보의 수집, 그 정렬, 비교, 분석 및 해석(설명)에 종사하며 다음과 같은 특징을 가지고 있습니다. 첫째, 통계학은 사회현상의 양적 측면인 크기, 크기, 부피를 연구하며 수치적 가치를 갖는다. 둘째, 통계는 현상의 질적 측면, 즉 특정 현상, 즉 한 현상을 다른 현상과 구별하는 내부 특징을 탐구합니다. 현상의 질적 측면과 양적 측면은 항상 함께 존재하여 통일성을 형성합니다. 모든 사회 현상과 사건은 시간과 공간에서 발생하며, 그 중 어느 것과 관련하여 언제 발생했으며 어디에서 발생했는지 항상 설정할 수 있습니다. 따라서 통계는 장소와 시간의 특정 조건에서 현상을 연구합니다. 통계로 연구되는 사회생활의 현상과 과정은 끊임없이 변화하고 발전하고 있다. 연구된 현상 및 과정의 변화에 대한 대량 데이터의 수집, 처리 및 분석을 기반으로 통계적 패턴을 드러냅니다. 통계적 규칙성은 사회에서 사회 경제적 관계의 존재와 발전을 결정하는 사회 법칙의 행동을 나타냅니다. 통계의 주제는 사회 현상, 그 발전의 역학 및 방향에 대한 연구입니다. 이 과학은 통계적 지표의 도움으로 사회 현상의 양적 측면을 결정하고 주어진 사회 현상의 예를 사용하여 양에서 질로의 전환 패턴을 관찰하고 이러한 관찰을 기반으로 특정 조건에서 얻은 데이터를 분석합니다 장소와 시간의. 통계는 거대한 사회 경제적 현상과 과정을 탐구하고 그것을 결정하는 많은 요인을 연구합니다. 대부분의 사회 과학은 통계를 사용하여 이론 법칙을 도출하고 확인합니다. 통계 연구에 기반한 결론은 경제학, 역사학, 사회학, 정치학 및 기타 많은 인문학에서 사용됩니다. 통계는 사회 과학이 이론적 근거를 확인하는 데 필요할 뿐만 아니라 실제적인 역할도 크다. 하나의 대기업이나 진지한 생산이 대상의 경제 및 사회 발전 전략을 개발할 때 분석 없이는 할 수 없습니다. 통계 데이터. 이를 위해 기업은이 분야에서 전문 교육을받은 전문가를 유치하는 특수 분석 부서 및 서비스를 만듭니다. 모든 과학과 마찬가지로 통계에는 해당 주제를 연구하기 위한 특정 방법론이 있습니다. 위에서 언급했듯이 그녀는 주로 현상의 발전과 사회 생활의 다른 현상과의 관계에 관심이 있으므로 연구하는 현상과 특정 연구 주제에 따라 통계 방법이 선택됩니다. 통계학에서는 사회 현상을 연구하기 위한 구체적인 방법과 기법이 개발되고 적용되어 통계 방법을 형성합니다. 여기에는 관찰, 데이터 요약 및 그룹화, 특수 방법(평균 지수 방법 등)에 기반한 일반화 지표 계산이 포함됩니다. 위의 내용에 따라 통계 데이터 작업에는 세 단계가 있습니다. - 수집; - 그룹화 및 요약 - 처리 및 분석. 데이터 수집은 연구 중인 현상의 개별 사실(단위)에 대한 기본 정보를 얻는 과학적으로 조직된 대량 관찰로 이해됩니다. 연구 중인 현상을 구성하는 많은 수 또는 모든 단위에 대한 이러한 통계적 설명은 연구 중인 현상 또는 프로세스에 대한 결론을 도출하기 위한 통계 일반화를 위한 정보 기반입니다. 데이터의 그룹화 및 요약은 일련의 사실(단위)을 동종 그룹 및 하위 그룹으로 배포하고, 각 그룹 및 하위 그룹에 대한 결과를 계산하고, 결과를 통계 테이블 형식으로 표시하는 것으로 이해됩니다. 통계 분석은 통계 연구의 마지막 단계입니다. 여기에는 요약 중에 얻은 통계 데이터의 처리, 연구 중인 현상의 상태 및 발달 패턴에 대한 객관적인 결론을 얻기 위해 얻은 결과의 해석이 포함됩니다. 통계 분석 과정에서는 사회 현상과 과정의 구조, 역학 및 상호 연결을 연구합니다. 통계 분석의 주요 단계는 다음과 같습니다. - 사실과 그 평가의 확립; - 현상의 특징적인 특징과 원인의 식별; - 비교의 근거로 삼은 규범적, 계획적 및 기타 현상과 현상의 비교; - 결론, 예측, 가정 및 가설의 공식화 - 제안된 가설의 통계적 테스트. 1.2. 통계의 이론적 기초 및 기본 개념 한편으로 통계의 주요 조항은 사회 현상의 발전 패턴을 고려하고 사회 생활에 대한 중요성, 원인 및 결과를 결정하기 때문에 사회 및 경제 이론의 법칙을 기반으로합니다. 반면에 많은 사회과학의 법칙은 통계분석을 통해 결정된 통계와 패턴을 기반으로 구축된다. 따라서 통계는 사회 과학의 법칙을 결정하고 차례로 통계 조항을 수정합니다. 통계의 이론적 기초는 수학과 밀접한 관련이 있습니다. 정량적 특성을 측정, 비교 및 분석하려면 수학적 지표, 법칙 및 방법을 적용해야합니다. 현상의 역학을 연구하고 사용하지 않고 다른 현상과의 관계를 연구하는 것은 불가능합니다. 더 높은 수학 및 수학적 분석. 종종 통계 연구는 현상에 대한 개발된 수학적 모델을 기반으로 합니다. 그런 모- del은 이론적으로 연구 중인 현상의 양적 비율을 반영합니다. 따라서 예를 들어 기업의 재무 상태를 평가할 때 A. Altman의 채점 모델이 자주 사용됩니다. Z 다음 공식을 사용하여 계산됩니다. Z = 1,2x1 + 1,4x2 + 3,3x3 + 0,6x4 + 10,0x5. 알트만에 따르면, Z ‹2,675 회사가 파산 위기에 처해 있습니다. Z › 2,675 회사의 재무 상태는 두려움을 불러일으키지 않습니다. 이 추정치를 얻으려면 미지수 ?1을 대입해야 합니다., ?2, ?3, 균형 라인의 특정 지표인 ?4 및 ?5. 통계 과학에서 특히 널리 퍼진 것은 확률 이론 및 수학적 통계와 같은 수학 분야입니다. 대수의 법칙, 변이 계열의 분석, 현상의 전개 예측을 외삽법을 사용하여 표현하는 많은 정리가 널리 사용됩니다. 현상과 과정의 인과관계는 상관분석과 회귀분석을 이용하여 설정합니다. 마지막으로 통계 과학은 전체성, 변이, 기호, 규칙성과 같은 가장 중요한 범주 및 개념에 대한 수학적 통계에 빚을 지고 있습니다. 통계 집계는 통계의 주요 범주를 말하며 통계 연구의 대상으로, 공공 생활의 사회 경제적 현상에 대한 정보를 체계적이고 과학적으로 수집하고 얻은 데이터를 분석하는 것으로 이해됩니다. 통계 연구를 수행하기 위해서는 과학적으로 기반을 둔 정보 기반이 필요합니다. 이는 통계적 집합 - 사회 경제적 대상 또는 사회 생활 현상의 집합으로 질적 기반, 공통 연결로 결합되지만 서로 다릅니다. 개별 기능(예: 가계, 가족, 회사 등) 통계 방법론의 관점에서 통계 모집단은 질량 특성, 균일성, 특정 무결성, 개별 단위 상태의 상호 의존성 및 변동의 존재와 같은 특성을 갖는 단위 집합입니다. 전체의 단위는 대상, 사실, 사람, 프로세스 등이 될 수 있습니다. 전체의 단위는 주요 요소이자 주요 기능의 전달자입니다. 통계 연구에 필요한 데이터가 수집되는 모집단의 요소를 관찰 단위라고 합니다. 인구의 단위 수를 인구의 크기라고 합니다. 통계 인구는 인구 조사, 기업, 도시, 회사 직원이 될 수 있습니다. 통계적 모집단과 그 단위의 선택은 연구 중인 사회경제적 현상이나 과정의 특정 조건과 성격에 따라 달라집니다. 인구 단위의 질량 특성은 인구의 완전성과 밀접한 관련이 있으며, 이는 연구 중인 통계 인구 단위의 적용 범위에 의해 보장됩니다. 예를 들어, 연구원은 은행의 발전에 대한 결론을 도출해야 합니다. 따라서 그는 해당 지역에서 운영되는 모든 은행에 대한 정보를 수집해야 합니다. 모든 세트는 다소 복잡한 특성을 갖기 때문에 완전성은 연구 중인 현상을 안정적이고 본질적으로 설명하는 세트의 가장 다양한 기능 세트의 적용 범위로 이해되어야 합니다. 예를 들어 은행을 모니터링하는 과정에서 재무 결과가 고려되지 않으면 은행 시스템 개발에 대한 최종 결론을 도출하는 것이 불가능합니다. 또한 완전성은 가능한 가장 긴 기간 동안 인구 단위의 특성에 대한 연구를 포함합니다. 충분히 완전한 데이터는 일반적으로 방대하고 철저합니다. 실제로 연구되는 사회경제적 현상은 매우 다양하기 때문에 모든 현상을 포괄하는 것은 어렵고 때로는 불가능합니다. 연구자는 통계 모집단의 일부만 연구하고 전체 모집단에 대한 결론을 도출해야 합니다. 이러한 상황에서 가장 중요한 요구 사항은 특성이 연구되는 모집단의 해당 부분을 합리적으로 선택하는 것입니다. 이 부분은 현상의 주요 특성을 반영해야 하며 전형적이어야 합니다. 실제로 여러 세트가 연구 중인 현상과 프로세스에서 상호 작용할 수 있습니다. 이러한 상황에서 연구 대상 집단은 연구 대상에서 명확하게 구별되어야 합니다. 모집단 단위의 기호는 관찰 및 측정할 수 있는 특징적인 특징, 특징, 특정 속성, 품질입니다. 시간이나 공간에서 연구된 인구는 비교할 수 있어야 합니다. 이를 위해 예를 들어 균일 비용 추정치를 사용할 필요가 있습니다. 전체성을 질적으로 조사하기 위해 가장 중요하거나 상호 관련된 특징을 연구합니다. 인구 단위를 특성화하는 기능의 수는 데이터 수집 및 결과 처리를 복잡하게 하기 때문에 과도하지 않아야 합니다. 통계적 모집단의 단위 특성은 서로 보완하고 상호의존성을 갖도록 결합되어야 합니다. 통계 모집단의 동질성 요구 사항은 하나 또는 다른 단위가 연구 대상 모집단에 속하는 기준의 선택을 의미합니다. 예를 들어, 젊은 유권자의 활동을 연구하면 기성 세대의 사람들을 제외하기 위해 그러한 유권자의 연령 제한을 결정할 필요가 있습니다. 그러한 인구를 농촌 지역의 대표자 또는 예를 들어 학생으로 제한하는 것이 가능합니다. 모집단 단위에 변동이 있다는 것은 특성이 다른 값이나 수정을 취할 수 있음을 의미합니다. 이러한 기호를 가변이라고 하며 개별 값 또는 수정을 변형이라고 합니다. 기호는 속성과 양으로 나뉩니다. 기호는 예를 들어 사람의 성별이나 특정 사회 집단에 속하는 것과 같은 의미 개념으로 표현되는 경우 속성 또는 질적이라고 합니다. 내부적으로는 명목과 서수로 나뉩니다. 속성을 숫자로 표현하면 정량적이라고 합니다. 변이의 성질에 따라 양적 기호는 불연속 기호와 연속 기호로 나뉩니다. 이산 기능은 일반적으로 가족 수와 같은 정수로 표현됩니다. 연속 기능에는 예를 들어 연령, 급여, 근속 기간 등이 포함됩니다. 측정 방법에 따라 기호는 XNUMX차(계산)와 XNUMX차(계산)로 나뉩니다. 기본(설명된)은 전체 인구의 단위, 즉 절대값을 나타냅니다. XNUMX차(계산)은 직접 측정하지 않고 계산(비용, 생산성)합니다. XNUMX차 특징은 통계 모집단의 관찰의 기초가 되며, XNUMX차 특징은 데이터 처리 및 분석 과정에서 결정되며 XNUMX차 특징의 비율을 나타냅니다. 특성화 된 대상과 관련하여 기호는 직접 및 간접으로 나뉩니다. 직접 기호는 특징적인 대상(생산량, 사람의 나이)에 직접적으로 고유한 속성입니다. 간접 기호는 객체 자체에 고유한 것이 아니라 객체와 관련되거나 객체에 포함된 다른 집합에 있는 속성입니다. 시간과 관련하여 순간 및 간격 기호가 구별됩니다. 순간 기호는 통계 연구 계획에 의해 설정된 특정 시점에서 연구 대상을 특성화합니다. 간격 기호는 프로세스 결과를 특성화합니다. 그들의 값은 특정 기간 동안만 발생할 수 있습니다. 징후 외에도 연구 대상 또는 통계 인구의 상태는 지표로 특징 지어집니다. 지표 - 사회 경제적 현상 및 프로세스에 대한 일반화된 정량적 평가를 나타내는 통계의 기본 개념 중 하나입니다. 통계지표는 대상 기능에 따라 회계와 평가, 분석으로 나뉜다. 회계 및 평가 지표는 공간에서 현상의 분포량이나 특정 시간에 도달 한 수준을 반영하여 특정 장소와 시간 조건에서 사회 경제적 현상의 크기에 대한 통계적 특성입니다. 분석 지표는 연구 된 통계 인구의 데이터를 분석하고 연구 된 현상의 발전 특징을 특성화하는 데 사용됩니다. 통계의 분석 지표로는 상대값, 평균값, 변동 지표 및 역학 지표, 커뮤니케이션 지표가 사용됩니다. 현상 사이에 존재하는 관계를 반영하는 일련의 통계 지표는 통계 지표 시스템을 형성합니다. 일반적으로 지표와 기호는 통계 인구를 완전히 특성화하고 철저하게 설명하므로 연구자는 통계 과학의 목표 중 하나인 인간 사회 생활의 현상과 과정에 대한 포괄적인 연구를 수행할 수 있습니다. 통계의 가장 중요한 범주는 통계적 규칙성입니다. 규칙성은 일반적으로 현상, 현상을 특징짓는 개별 기능의 순서 및 반복 사이의 감지 가능한 인과 관계로 이해됩니다. 통계에서 규칙성은 객관적인 법칙의 작용으로 인한 대중 현상과 사회 생활의 과정의 공간과 시간 변화의 양적 규칙성으로 이해됩니다. 결과적으로 통계적 규칙성은 인구의 개별 단위가 아니라 전체 인구의 특징이며 충분히 많은 수의 관찰에서만 나타납니다. 따라서 통계적 규칙 성은 한 방향 또는 다른 방향으로 기호 값의 개별 편차를 상호 취소 할 때 평균, 사회적, 대량 규칙으로 나타납니다. 통계적 규칙성의 표현은 현상의 일반적인 그림을 제시하고 무작위의 개별 편차를 제외하고 현상의 경향을 연구하는 것을 가능하게 합니다. 1.3. 러시아 연방 통계의 현대 조직 통계는 국가의 경제 및 사회 발전을 관리하는 데 중요한 역할을 합니다. 모든 관리 결정의 정확성은 결정된 정보에 따라 크게 좌우되기 때문입니다. 높은 수준의 관리에서는 정확하고 신뢰할 수 있으며 올바르게 분석된 데이터만 고려해야 합니다. 국가, 개별 지역, 산업, 기업, 기업의 경제 및 사회 발전에 대한 연구는 통계 서비스를 구성하는 특별히 만들어진 기관에서 수행합니다. 러시아 연방에서 통계 서비스의 기능은 국가 통계 기관과 부서별 통계 기관에서 수행합니다. 우리나라의 통계 관리를위한 최고 기관은 09.03.2004 년 314 월 XNUMX 일 러시아 연방 대통령령 No. XNUMX "연방 행정 기관의 구조"에 따라 설립 된 연방 통계청 (FSGS)입니다. 연방 통계청은 국가의 사회, 경제, 인구 통계 및 환경 상황에 대한 공식 통계 정보를 생성하는 기능과 국가 통계 활동 분야의 통제 및 감독 기능을 수행하는 연방 집행 기관입니다. 러시아 연방의 영토. 연방 통계청은 러시아 연방 경제 개발 무역부의 관할 하에 있습니다. 07.04.2004년 188월 XNUMX일 러시아 연방 정부 법령 No. XNUMX에 따르면 연방 통계청의 주요 기능은 다음과 같습니다. - 확립된 절차에 따라 러시아 연방 대통령, 러시아 연방 정부, 러시아 연방 의회, 주 당국, 언론, 조직 및 시민, 국제 기구에 통계 정보 제공 - 통계적 관찰을 수행하고 통계적 지표를 생성하기 위한 과학 기반 공식 통계 방법론의 개발 및 개선, 이 방법론이 국제 표준을 준수함을 보장합니다. - 경제 및 사회 영역의 상태를 특징 짓는 통계 지표 시스템의 개발 및 개선; - 통계 보고의 수집 및 이를 기반으로 하는 공식 통계 정보의 구성 - 국가 통계 분야의 러시아 연방 법률인 법인을 구성하지 않고 기업 활동에 참여하는 조직 및 시민의 구현에 대한 통제 - 국가 통계 정보 시스템의 개발, 다른 국가 정보 시스템과의 호환성 및 상호 작용 보장 - 국가 정보 자원의 저장과 기밀 및 기밀 통계 정보의 보호를 보장합니다. - 국제기구의 회원 자격 및 국제 조약 참여, 통계 분야의 국제 협력 이행으로 인한 러시아 연방의 의무 이행. 통계 지표의 방법론, 통계 데이터 수집 및 처리 방법은 연방 통계청에서 제정한 러시아 연방의 공식 통계 표준입니다. 주요 활동에서 FSGS는 연방 행정부 및 입법부, 러시아 연방 구성 기관의 주 당국, 과학 및 기타 조직의 제안을 고려하여 형성되고 승인 된 연방 통계 프로그램에 의해 안내됩니다. 러시아 연방 정부와 합의한 FSGS. 국가 통계 당국의 주요 임무는 일반 (개별이 아닌) 정보의 홍보 및 접근성을 보장하고 고려한 데이터의 신뢰성, 정확성 및 진실성을 보장하는 것입니다. 또한 FSGS의 작업은 다음과 같습니다. - 러시아 연방 대통령, 러시아 연방 정부, 러시아 연방 의회, 연방 집행 기관, 대중 및 국제 기구에 공식 통계 정보 제공 - 연방 집행 기관 및 러시아 연방 구성 기관의 집행 기관의 통계 활동 조정, 부문별(부서) 통계 관찰을 수행할 때 이들 기관의 공식 통계 표준 사용 조건 제공 - 경제 및 통계 정보의 개발, 분석, 국민 계정 편집, 필요한 잔액 계산 - 모든 공식 통계 정보의 완전성과 과학적 타당성을 보장합니다. - 러시아 연방, 러시아 연방 구성 기관, 산업 및 경제 부문에 대한 공식 보고서 배포, 통계 수집 및 기타 통계 자료 발행을 통해 모든 사용자에게 공개 통계 정보에 대한 평등한 액세스를 제공합니다. 러시아 연방 경제 개혁의 결과로 통계 기관의 구조도 변경되었습니다. 지역통계등록부가 폐지되고 지역통계기관의 대표기관인 지역통계과가 신설되었다. 러시아의 통계 기관 조직은 현재 개혁 단계에 있습니다. 무화과에. 1.2는 2004년 러시아 연방 통계 기관의 도표를 보여줍니다. 
그림. 1.2. 2004 년 러시아 연방 통계 기관 계획 현재 개혁이 이루어져야 하는 주요 영역은 다음과 같습니다. - 통계 회계의 기본법 준수 - 개별 지표(영업 비밀)의 기밀성을 유지하면서 정보의 공개 및 가용성; -통계의 방법론적 및 조직적 기초 개혁: 경제 관리의 일반 임무와 원칙을 변경하면 과학의 이론적 규정이 변경됩니다. - 자격, 등록부(레지스트리), 인구 조사 등의 관찰 형식을 도입하여 정보 수집 및 처리 시스템을 개선합니다. - 국제 표준, 통계 회계에 대한 외국 경험을 고려하여 러시아 경제 상태를 특징짓는 일부 통계 지표 계산 방법론 변경(개선), 모든 지표를 체계화하고 시대의 문제와 요구 사항을 충족하는 순서로 가져오기, 국민 계정 시스템(SNA) 고려 ; - 국가의 공공 생활 발전 수준을 특징 짓는 통계 지표의 관계를 보장합니다. - 전산화 추세를 고려합니다. 통계 과학을 개혁하는 과정에서 국가 통계 조직의 계층 사다리의 하위 수준에있는 모든 통계 기관의 정보 기반을 포함하는 통일 된 정보 기반 (시스템)을 만들어야합니다. 현재 통계 기관의 업무를 조직화하기 위해 많은 작업이 수행되었지만 아직 완료되지 않았으며 국가에 매우 중요한이 정보 기관의 개선에 많은주의를 기울여야합니다. 국가 통계 서비스와 함께 경제의 다양한 부문에서 부처, 부서, 기업, 협회 및 기업에서 유지 관리되는 부서별 통계가 있습니다. 부서별 통계는 기업 또는 기관의 경영, 경영 의사 결정, 활동 계획에 필요한 통계 정보의 수집, 처리 및 분석에 종사합니다. 소기업에서이 작업은 원칙적으로 수석 회계사가하거나 직접 머리가 수행합니다. 자체적으로 분기된 지역 구조나 인원이 많은 대기업에서는 통계 정보의 분석을 처리하는 전체 부서 또는 부서가 구성됩니다. 이 작업에는 통계, 수학, 회계 및 경제 분석 분야의 전문가, 관리자 및 기술자가 포함됩니다. 통계 이론이 제안한 방법론과 현대적인 분석 방법을 사용하여 현대 컴퓨터 기술로 무장한 이러한 "팀"은 효과적인 비즈니스 개발 전략을 수립하고 공공 기관의 활동을 효과적으로 조직하는 데 도움이 됩니다. 신속하고 완전하며 신뢰할 수 있는 통계 정보 없이 복잡한 사회 및 경제 시스템을 관리하는 것은 불가능합니다. 따라서 국가 및 부서 통계 기관은 경제 발전을위한 현대 조건에 해당하고 회계 및 통계 시스템의 합리화에 기여할 통계 정보의 양과 구성에 대한 이론적 입증이라는 매우 중요한 작업에 직면 해 있습니다. 이 기능을 수행하는 비용을 최소화합니다. 주제 2. 통계적 관찰 2.1. 통계적 관찰의 개념, 구현 단계 모든 경제적 또는 사회적 과정에 대한 심층적이고 포괄적인 연구는 양적 측면을 측정하고 사회적 관계의 일반 시스템에서 질적 본질, 위치, 역할 및 관계를 특성화하는 것을 포함합니다. 사회 생활의 현상과 과정을 연구하기 위해 통계적 방법을 사용하기 전에 연구 대상을 완전하고 안정적으로 설명하는 철저한 정보 기반이 필요합니다. 통계 연구 프로세스에는 다음 단계가 포함됩니다. - 통계정보 수집(통계관측) 및 XNUMX차 처리 - 요약 및 그룹화를 기반으로 통계적 관찰의 결과로 얻은 데이터의 체계화 및 추가 처리 - 통계 자료 처리 결과의 일반화 및 분석, 전체 통계 연구 결과를 기반으로 한 결론 및 권장 사항의 공식화. 통계적 관찰 - 과학적 기반에 체계적이고 체계적으로 구성된 통계 연구의 첫 번째 및 초기 단계로서 사회 및 경제 생활의 다양한 현상에 대한 기본 데이터를 수집하는 프로세스입니다. 통계 관찰의 규칙성은 통계 정보를 수집하는 조직 및 기술, 품질 및 신뢰성 관리, 최종 자료 제시와 관련된 문제를 포함하는 특별히 개발된 계획에 따라 수행된다는 사실에 있습니다. 통계적 관찰의 질량 특성은 연구 중인 현상 또는 과정의 모든 징후의 모든 경우를 가장 완벽하게 포함함으로써 보장됩니다. 즉, 통계적 관찰 과정에서 인구의 개별 단위가 아닌 양적 및 질적 특성이 측정되고 기록됩니다. 연구 중이지만 인구 단위의 전체 질량에 의해. 통계적 관찰의 체계적 특성은 무작위, 즉 자발적으로 수행되어서는 안 되며, 지속적으로 또는 일정한 간격으로 규칙적으로 수행되어야 함을 의미합니다. 통계적 관찰의 과정은 그림 2.1에 나와 있습니다. XNUMX. 
쌀. 2.1. 통계적 관찰 방식 통계적 관찰을 준비하는 과정에는 관찰의 목적과 대상, 기록할 특징의 구성, 관찰 단위의 선택이 포함됩니다. 또한 데이터 수집을 위한 문서 형식을 개발하고 데이터를 수집하는 수단과 방법을 선택해야 합니다. 따라서 통계적 관찰은 자격을 갖춘 인력, 포괄적으로 고려된 조직, 계획, 준비 및 구현의 참여를 요구하는 노동 집약적이고 힘든 작업입니다. 2.2. 통계적 관찰의 종류와 방법 일반통계이론의 과제는 통계적 관찰의 형태, 유형 및 방법을 결정하여 어디에, 언제, 어떤 관찰 방법을 적용할지 결정하는 것입니다. 아래 그림은 통계적 관찰 유형의 분류를 보여줍니다(그림 2.2). 
그림. 2.2. 통계적 관찰 유형의 분류 통계적 관찰은 그룹으로 나눌 수 있습니다. - 인구 단위의 적용 범위에 의해; - 사실 등록 시간. 연구 대상 인구의 적용 범위에 따라 통계적 관찰은 연속 및 비연속의 두 가지 유형으로 나뉩니다. 지속적인(전체) 관찰을 통해 연구된 모집단의 모든 단위가 포함됩니다. 지속적인 관찰은 연구된 현상과 과정에 대한 정보의 완전성을 제공합니다. 이러한 유형의 관찰은 필요한 정보의 전체 양을 수집하고 처리하는 데 많은 시간이 걸리기 때문에 높은 노동 및 재료 자원 비용과 관련이 있습니다. 예를 들어 조사된 인구가 너무 많거나 인구의 모든 단위에 대한 정보를 얻을 수 없는 경우와 같이 지속적인 관찰이 전혀 불가능한 경우가 많습니다. 이러한 이유로 비연속적인 관찰이 수행됩니다. 비연속 관찰의 경우 연구 대상 인구의 특정 부분만 포함되지만 연구 대상 인구의 어느 부분이 관찰 대상인지, 어떤 기준이 표본의 기초로 사용될 것인지 미리 결정하는 것이 중요합니다. . 비연속적 관찰을 수행하는 것의 장점은 짧은 시간에 수행되고 더 낮은 인건비 및 자재 비용과 관련되며 얻은 정보가 운영적 성격을 띤다는 것입니다. 비연속적 관찰에는 몇 가지 유형이 있습니다. 선택적 관찰, 기본 배열 관찰, 단행본. 선택적은 무작위 선택에 의해 선택된 연구 모집단 단위의 일부에 대한 관찰입니다. 올바른 조직으로 선택적 관찰은 전체 모집단에 특정 확률로 적용할 수 있는 충분히 정확한 결과를 제공합니다. 표본 관찰이 연구 중인 모집단의 단위 선택(공간 샘플링)뿐만 아니라 기호 등록이 수행되는 시점(시간 샘플링)을 포함하는 경우 이러한 관찰을 다음 방법이라고 합니다. 순간적인 관찰. 주요 배열의 관찰은 인구 단위의 연구 특성의 중요성 측면에서 가장 중요한 특정 조사를 포함합니다. 이 관찰에서는 인구의 가장 큰 단위를 고려하고 본 연구의 가장 중요한 특징을 기록합니다. 예를 들어, 대형 신용 기관의 15-20%를 조사하면서 투자 포트폴리오의 내용을 기록합니다. 단행본 관찰은 몇 가지 특별한 특성을 가지고 있거나 몇 가지 새로운 현상을 나타내는 인구의 개별 단위에 대해서만 포괄적이고 심도 있는 연구를 특징으로 합니다. 그러한 관찰의 목적은 주어진 과정이나 현상의 발전에 있어 기존의 경향이나 새로운 경향만을 식별하는 것입니다. 단행본 설문조사에서 인구의 개별 단위는 상세한 연구를 거치므로 다른 덜 상세한 관찰에서는 감지할 수 없는 매우 중요한 종속성과 비율을 수정할 수 있습니다. 통계 단행본 조사는 의학에서, 가계 등을 조사할 때 자주 사용됩니다. 단행본 조사는 지속적이고 선택적인 조사와 밀접한 관련이 있다는 점에 유의하는 것이 중요합니다. 첫째, 비연속 및 단행관측을 위한 인구단위 선정 기준을 선정하기 위해서는 대량조사 자료가 필요하다. 둘째, 단행본 관찰을 통해 연구 대상의 특징적인 특징과 필수 특징을 식별하고 연구 인구의 구조를 명확히 할 수 있습니다. 결과는 새로운 대량 조사를 조직하는 기초로 사용될 수 있습니다. 사실의 등록 시점에 따라 관찰은 연속적일 수도 있고 불연속적일 수도 있습니다. 불연속은 차례로 주기적 및 일회성을 포함합니다. 지속적인 (현재) 관찰은 사실이 발생하는대로 계속 등록하여 수행됩니다. 이러한 관찰을 통해 연구 중인 프로세스 또는 현상의 모든 변화를 추적하여 역학을 모니터링할 수 있습니다. 예를 들어, 시민 등록 사무소(ZAGS)에 의한 사망, 출생, 결혼 등록이 지속적으로 수행됩니다. 기업은 현재 생산 기록, 창고에서 자재 반출 등을 유지합니다. 간헐적 관찰은 일정한 간격으로 규칙적으로 수행하거나(주기적 관찰) 필요에 따라 비정기적으로 한 번(일회성 관찰) 수행합니다. 정기적인 관찰은 일반적으로 유사한 프로그램과 도구를 기반으로 하므로 그러한 조사의 결과를 비교할 수 있습니다. 주기적인 관찰의 예로는 충분히 긴 간격으로 수행되는 인구 조사와 월별, 분기별, 반기별, 연간 등의 모든 형태의 통계적 관찰이 있습니다. 일회성 관찰은 사실이 발생한 것과 관련하여 기록되는 것이 아니라 특정 시점 또는 일정 기간 동안의 상태 또는 존재에 따라 기록된다는 사실이 특징입니다. 현상이나 과정의 징후에 대한 정량적 측정은 조사 시점에 이루어지며, 징후의 재등록이 전혀 이루어지지 않거나 시행 시기가 미리 정해져 있지 않을 수 있습니다. 일회성 관찰의 예로 2000년에 실시된 주택건설실태에 대한 일회성 조사를 들 수 있다. 통계학 일반이론은 통계적 관찰의 유형과 함께 통계적 정보를 얻기 위한 방법을 고려하는데, 그 중 가장 중요한 것은 기록관찰, 직접관찰, 조사 등이다. 문서 관찰은 회계 장부와 같은 다양한 문서의 데이터를 정보 소스로 사용하는 것을 기반으로 합니다. 일반적으로 그러한 문서를 작성하는 데 높은 요구 사항이 부과된다는 점을 고려할 때 문서에 반영된 데이터는 가장 신뢰할 수 있는 특성을 가지며 분석을 위한 고품질 소스 자료가 될 수 있습니다. 직접 관찰은 조사, 측정 및 조사 중인 현상의 징후를 집계한 결과 레지스트라가 개인적으로 확립한 사실을 등록함으로써 수행됩니다. 이러한 방식으로 상품 및 서비스의 가격이 기록되고, 근무 시간이 측정되고, 재고 잔고 목록이 작성됩니다. 설문조사는 응답자(설문조사 참가자)로부터 얻은 데이터를 기반으로 합니다. 조사는 다른 방법으로 관찰할 수 없는 경우에 사용합니다. 이러한 유형의 관찰은 다양한 사회학적 조사 및 여론 조사를 수행하는 데 일반적입니다. 통계 정보는 탐사, 특파원, 설문 조사, 비공개와 같은 다양한 유형의 설문 조사를 통해 얻을 수 있습니다. 원정(구두) 설문조사는 특별히 훈련된 작업자(등록자)가 수행하며, 관찰 형식으로 응답자의 답변을 기록합니다. 양식은 답변 필드를 채워야 하는 문서 형식입니다. 특파원 설문조사에서는 자발적으로 응답자 직원이 모니터링 기관에 직접 정보를 보고한다고 가정합니다. 이 방법의 단점은 수신된 정보의 정확성을 검증하기 어렵다는 점이다. 설문 조사에서 응답자는 자발적으로 대부분 익명으로 설문지(설문지)를 작성합니다. 이 정보 획득 방법은 신뢰할 수 없기 때문에 결과의 높은 정확도가 요구되지 않는 연구에서 사용됩니다. 어떤 상황에서는 추세만을 포착하고 새로운 사실과 현상의 출현을 기록하는 대략적인 결과가 충분합니다. 대면 조사는 대면 방식으로 모니터링을 수행하는 기관에 정보를 제출하는 것을 포함합니다. 이러한 방식으로 결혼, 이혼, 사망, 출생 등 시민권 행위가 등록됩니다. 통계적 관찰의 유형과 방법 외에도 통계 이론은 보고, 특별히 조직된 통계적 관찰, 기록부와 같은 통계적 관찰의 형태도 고려합니다. 통계 보고는 통계 관찰의 주요 형태로, 통계 당국은 연구 중인 현상에 대한 정보를 기업 및 조직이 특정 기간 내에 규정된 형식으로 제출한 특별 문서 형태로 수신한다는 사실을 특징으로 합니다. 통계 보고 형식 자체, 통계 데이터 수집 및 처리 방법, 연방 통계청이 수립한 통계 지표 방법론은 러시아 연방의 공식 통계 표준이며 모든 홍보 주제에 필수입니다. 통계보고는 전문과 표준으로 나뉩니다. 표준보고 지표의 구성은 모든 기업 및 조직에 대해 동일하지만 전문보고 지표의 구성은 경제 및 영역의 개별 부문에 따라 다릅니다. 활동. 제출 시기에 따라 통계 보고는 일간, 주간, XNUMX일, XNUMX주, 월간, 분기, 반기 및 연간입니다. 통계 보고는 전화, 통신 채널, 전자 매체를 통해 전송될 수 있으며 책임자의 서명으로 인증된 종이에 의무적으로 후속 제출해야 합니다. 특별히 조직된 통계관측은 보고에서 다루지 않는 현상을 연구하거나 보고자료를 보다 심층적으로 연구하고 검증하고 정제하기 위해 통계당국이 조직한 정보의 집합체이다. 다양한 종류의 인구 조사, 일회성 조사는 특별히 조직된 관찰입니다. 레지스터는 인구의 개별 단위 상태에 대한 사실이 지속적으로 기록되는 관찰의 한 형태입니다. 인구의 단위를 관찰하면 거기에서 발생하는 프로세스가 시작, 장기 지속 및 끝이 있다고 가정합니다. 레지스터에서 각 관찰 단위는 일련의 지표로 특징 지어집니다. 모든 표시기는 관찰 단위가 레지스터에 있고 그 존재가 끝나지 않을 때까지 저장됩니다. 일부 지표는 관찰 단위가 레지스터에 있는 한 동일하게 유지되고 다른 지표는 수시로 변경될 수 있습니다. 이러한 등록의 예로 USRE(Unified State Register of Enterprises and Organizations)가 있습니다. 유지 보수에 대한 모든 작업은 FSGS에서 수행합니다. 따라서 통계적 관찰의 유형, 방법 및 형태의 선택은 관찰의 목표와 목적, 관찰된 대상의 특성, 결과 제시의 긴급성, 훈련된 인력의 가용성 등 여러 요인에 따라 달라집니다. , 데이터를 수집하고 처리하는 기술적 수단을 사용할 가능성. 2.3. 통계적 관찰의 프로그램 및 방법론적 문제 통계적 관찰을 작성할 때 해결해야 하는 가장 중요한 작업 중 하나는 관찰의 목적, 대상 및 단위의 정의입니다. 거의 모든 통계적 관찰의 목표는 요인의 상호 관계를 식별하고 현상의 규모와 발달 패턴을 평가하기 위해 사회 생활의 현상과 과정에 대한 신뢰할 수 있는 정보를 얻는 것입니다. 관찰 작업에 따라 프로그램과 조직 형태가 결정됩니다. 목표 외에도 관찰 대상을 설정하는 것, 즉 정확히 관찰할 대상을 결정하는 것이 필요합니다. 관찰의 대상은 연구할 사회 현상이나 과정의 총체이다. 관찰 대상은 일련의 기관(학점, 교육 등), 인구, 물리적 대상(건물, 운송, 장비)이 될 수 있습니다. 관찰 대상을 설정할 때 연구 대상 인구의 경계를 엄격하고 정확하게 결정하는 것이 중요합니다. 이를 위해서는 집합체에 어떤 객체를 포함할지 여부를 결정짓는 본질적인 특징을 명확하게 설정하는 것이 필요하다. 예를 들어, 현대 장비를 제공하기 위해 의료 기관에 대한 조사를 수행하기 전에 조사할 진료소의 범주, 부서 및 영토 소속을 결정해야 합니다. 관찰 대상을 정의할 때 관찰 단위와 모집단 단위를 지정할 필요가 있습니다. 관찰 단위는 정보의 출처인 관찰 대상의 구성 요소입니다. 즉, 관찰 단위는 등록할 기호의 운반자입니다. 통계 관찰의 특정 작업에 따라 학생, 농업 기업 또는 공장과 같은 가정 또는 개인이 될 수 있습니다. 관찰 단위는 통계 당국에 통계 보고서를 제출하는 경우 보고 단위라고 합니다. 모집단 단위는 관찰 대상의 구성 요소로, 관찰 단위에 대한 정보가 수신됩니다. 관찰의. 예를 들어, 산림 조림지의 인구 조사에서 인구의 단위는 등록 대상이되는 특성 (나이, 종 구성 등)을 가지고 있기 때문에 나무가 될 것이며 조사가 수행되는 임업 자체는 , 관찰 단위 역할을 합니다. 사회생활의 각각의 현상이나 과정은 많은 특징을 가지고 있지만, 모든 것에 대한 정보를 얻는 것은 불가능하고, 그들 모두가 연구자에게 관심이 있는 것은 아니므로 관찰을 준비할 때 어떤 특징이 관찰의 목적과 목적에 따라 등록해야 합니다. 등록된 특징의 구성을 결정하기 위해 관찰 프로그램이 개발됩니다. 통계 관찰 프로그램을 일련의 질문이라고하며 관찰 과정에서 통계 정보를 형성해야 하는 답변입니다. 관찰 프로그램의 개발은 매우 중요하고 책임 있는 작업이며 관찰의 성공 여부는 관찰을 얼마나 정확하게 수행하느냐에 달려 있습니다. 관찰 프로그램을 개발할 때 고려해야 할 몇 가지 요구 사항이 있습니다. - 가능한 경우 프로그램에는 필요한 기능과 해당 값이 추가 분석 또는 제어 목적으로 사용되는 기능만 포함되어야 합니다. 양성 자료의 수신을 보장하는 정보를 완성하기 위한 노력으로, 분석을 위한 신뢰할 수 있는 자료를 얻기 위해 수집되는 정보의 양을 제한할 필요가 있습니다. - 프로그램의 질문은 잘못된 해석을 배제하고 수집되는 정보의 의미 왜곡을 방지하기 위해 명확하게 공식화되어야 합니다. - 관찰 프로그램을 개발할 때 논리적인 질문 순서를 만드는 것이 바람직합니다. 현상의 한 측면을 특징 짓는 동일한 유형 또는 기호의 질문은 한 섹션으로 결합되어야 합니다. - 모니터링 프로그램에는 기록된 정보를 확인하고 수정하기 위한 제어 질문이 포함되어야 합니다. 관찰을 수행하려면 양식과 지침과 같은 특정 도구가 필요합니다. 통계 양식 - 프로그램 질문에 대한 답변을 기록하는 단일 샘플의 특수 문서. 수행되는 관찰의 구체적인 내용에 따라 그 형식은 통계 보고의 한 형태, 인구 조사 또는 설문지, 지도, 카드, 설문지 또는 양식이라고 부를 수 있습니다. 양식에는 카드와 목록의 두 가지 유형이 있습니다. 카드 양식 또는 개별 양식은 통계 모집단의 한 단위에 대한 정보를 반영하도록 설계되었으며 목록 양식에는 인구의 여러 단위에 대한 정보가 포함됩니다. 통계 양식의 필수 및 필수 요소는 제목, 주소 및 내용 부분입니다. 제목 부분은 통계적 관찰의 이름과 이 양식을 승인한 기관, 양식 제출 조건 및 기타 정보를 나타냅니다. 주소 부분에는 보고하는 관찰 단위의 세부 정보가 포함됩니다. 양식의 주요 내용 부분은 일반적으로 지표의 이름, 코드 및 값을 포함하는 테이블처럼 보입니다. 통계 양식은 지침에 따라 작성됩니다. 지침에는 관찰 수행 절차, 방법론 지침 및 양식 작성에 대한 설명이 포함되어 있습니다. 감시 프로그램의 복잡성에 따라 지침은 브로셔로 발행되거나 양식 뒷면에 배치됩니다. 또한 필요한 설명을 위해 관찰을 수행하는 전문가, 관찰을 수행하는 기관에 문의할 수 있습니다. 통계적 관찰을 조직 할 때 관찰 시간과 수행 장소 문제를 해결할 필요가 있습니다. 관찰 장소의 선택은 관찰 목적에 따라 다릅니다. 관찰 시간의 선택은 중요한 순간(날짜) 또는 시간 간격의 결정 및 관찰 기간(기간)의 결정과 관련이 있습니다. 통계적 관찰의 결정적 순간은 관찰 과정에서 기록된 정보가 타이밍이 되는 시점이다. 관찰 기간은 연구 중인 현상에 대한 정보 등록이 수행되어야 하는 기간, 즉 양식이 작성되는 시간 간격을 결정합니다. 일반적으로 관찰 기간은 그 순간의 물체의 상태를 재현하기 위해 관찰의 임계 순간에서 너무 멀지 않아야합니다. 2.4. 통계적 관찰의 조직적 지원, 준비 및 수행 문제 통계적 관찰의 성공적인 준비와 수행을 위해서는 조직적 지원의 문제가 해결되어야 한다. 이를 위해 관찰의 목표와 목적, 관찰의 대상, 장소, 시간, 관찰 시간, 관찰을 수행하는 책임자의 범위를 반영하는 관찰의 조직적 계획이 작성됩니다. 조직 계획의 필수 요소는 모니터링 기관의 표시입니다. 모니터링을 지원하도록 설계된 조직의 범위도 결정되며 여기에는 내무부, 세무 조사관, 부문 부처, 공공 조직, 개인, 자원 봉사자 등이 포함될 수 있습니다. 준비 활동에는 다음이 포함됩니다. - 통계적 관찰 형태의 개발, 설문 조사 자체의 문서 복제; - 관찰 결과의 분석 및 제시를 위한 방법론적 장치의 개발; - 데이터 처리를 위한 소프트웨어 개발, 컴퓨터 및 사무 기기 구매; - 사무용품을 포함한 필요한 자재 구매; - 자격을 갖춘 인력의 교육, 인력의 교육, 다양한 종류의 브리핑 수행 등 - 관찰에 참여하는 인구와 참가자들 사이에서 대규모 설명 작업 수행 (강의, 대화, 언론 연설, 라디오 및 텔레비전) - 공동 행동에 관련된 모든 서비스 및 조직의 활동 조정 - 데이터 수집 및 처리 장소의 장비 - 정보 전송 채널 및 통신 수단 준비 - 통계적 관찰 자금 조달과 관련된 문제의 해결. 따라서 모니터링 계획에는 필요한 정보 기록 작업을 성공적으로 완료하기 위한 여러 가지 조치가 포함됩니다. 2.5. 관찰 정확도 및 데이터 검증 방법 관찰 과정에서 수행되는 데이터 크기의 각 특정 측정은 일반적으로이 크기의 실제 값과 어느 정도 다른 현상 크기의 대략적인 값을 제공합니다. 관찰 자료에서 얻은 지표 또는 특징의 실제 값과 일치하는 정도를 통계적 관찰의 정확도라고합니다. 관찰 결과와 관찰된 현상의 크기의 실제 값 사이의 불일치를 관찰 오류라고 합니다. 관찰오차는 발생의 성격, 단계, 원인에 따라 몇 가지 유형으로 구분된다(표 2.1). 표 2.1 관측오차 분류 
본질적으로 오류는 무작위 및 체계적으로 나뉩니다. 무작위 오류는 오류라고 하며, 무작위 요인의 작용으로 인해 발생합니다. 여기에는 인터뷰 대상자의 예약 및 인쇄 오류가 포함됩니다. 그것들은 속성의 값을 감소시키거나 증가시키는 방향으로 지시될 수 있으며, 일반적으로 관찰 결과의 요약 처리 중에 서로 상쇄되기 때문에 최종 결과에 반영되지 않습니다. 체계적 오류는 속성 지표의 값을 감소시키거나 증가시키는 경향이 있습니다. 이것은 예를 들어 측정이 잘못된 측정기로 이루어지거나 오류가 관찰 프로그램 등의 문제를 부정확하게 공식화한 결과이기 때문입니다. 시스템 오류는 크게 왜곡되기 때문에 큰 위험이 있습니다. 관찰 결과. 발생 단계에 따라 등록 오류가 구별됩니다. 기계 처리를 위해 데이터를 준비하는 동안 발생하는 오류; 컴퓨터 기술에서 처리하는 동안 나타나는 오류. 등록오류에는 통계적 형식(기본문서, 서식, 보고서, 인구조사 서식)으로 데이터를 기록할 때 발생하는 부정확성 또는 컴퓨터 기술에 데이터를 입력할 때 발생하는 부정확성, 통신선(전화, 이메일)을 통해 전송될 때 데이터 왜곡이 포함됩니다. 종종 양식 형식을 준수하지 않아 등록 오류가 발생합니다. 즉, 문서의 잘못된 줄이나 열에 항목이 입력되었습니다. 개별 지표의 가치를 의도적으로 왜곡하는 것도 있습니다. 기계 처리를 위한 데이터 준비 또는 처리 자체 과정에서 오류가 컴퓨터 센터 또는 데이터 준비 센터에서 발생합니다. 이러한 오류의 발생은 형식의 데이터를 부주의하고 부정확하며 흐릿하게 채우기, 데이터 매체의 물리적 결함, 정보 기반 저장 기술을 준수하지 않아 데이터의 일부가 손실되는 것과 관련이 있습니다. 장비 고장에 의해 결정됩니다. 관찰 오류의 종류와 원인을 알면 이러한 정보 왜곡의 비율을 크게 줄일 수 있습니다. 다음과 같은 유형의 오류가 있습니다. 사회 생활의 현상과 과정에 대한 단일 통계적 관찰 중에 발생하는 특정 오류와 관련된 측정 오류; 비연속적 관찰에서 발생하고 표본 자체가 대표성이 아니며 이를 기반으로 얻은 결과를 전체 모집단으로 확장할 수 없다는 사실과 관련된 대표성 오류; 관찰 대상의 실제 상태를 꾸미거나 반대로 대상의 불만족스러운 상태를 보여주고자 하는 등 다양한 목적으로 데이터를 고의적으로 왜곡하여 발생하는 고의적 오류(이러한 정보 왜곡은 법률 위반입니다) ; 일반적으로 우연한 성격의 의도하지 않은 오류로 직원의 낮은 자격, 부주의 또는 과실과 관련됩니다. 종종 그러한 오류는 주관적인 요인과 관련이 있습니다. 사람들이 나이, 결혼 여부, 교육, 사회 집단 구성원 등에 대한 잘못된 정보를 제공하거나 단순히 일부 사실을 잊어버리고 방금 발생한 등록 정보를 말하는 경우입니다. 관찰 오류를 예방, 식별 및 수정하는 데 도움이 되는 몇 가지 활동을 수행하는 것이 바람직합니다. 여기에는 다음이 포함됩니다. - 자격을 갖춘 직원의 선택 및 감시 수행과 관련된 직원의 고품질 교육 - 연속적 또는 선택적인 방법으로 문서 작성의 정확성에 대한 통제 점검 조직 - 관찰 자료 수집 완료 후 수신 데이터의 산술 및 논리 제어. 데이터 신뢰성 제어의 주요 유형은 구문, 논리 및 산술입니다(표 2.2). 표 2.2 통제의 종류와 내용 
구문 제어는 문서 구조의 정확성, 필수 및 필수 세부 사항의 존재, 설정된 규칙에 따라 양식 라인 작성의 완전성을 확인하는 것을 의미합니다. 구문 제어의 중요성과 필요성은 양식 작성 규칙 준수에 대한 엄격한 요구 사항을 부과하는 데이터 처리용 스캐너, 컴퓨터 기술의 사용으로 설명됩니다. 논리적 제어는 코드 작성의 정확성, 표시기의 이름 및 값 준수를 확인합니다. 지표 간의 필요한 관계를 확인하고 다양한 질문에 대한 답변을 비교하며 호환되지 않는 조합을 식별합니다. 논리적 통제 중에 발견된 오류를 수정하기 위해 원본 문서로 돌아가 수정합니다. 산술 제어 중에 얻은 합계는 행과 열에 대해 미리 계산된 체크섬과 비교됩니다. 종종 산술 제어는 하나의 지표가 두 개 이상의 다른 지표에 의존하는 것을 기반으로 합니다. 예를 들어 다른 지표의 산물입니다. 최종 지표의 산술 제어에서 이러한 의존성이 관찰되지 않는 것으로 밝혀지면 데이터의 부정확성을 나타냅니다. 따라서 통계정보의 신뢰성 관리는 XNUMX차 정보의 수집부터 결과를 얻는 단계까지 통계적 관찰의 모든 단계에서 이루어지고 있다. 주제 3. 통계 요약 및 그룹화 3.1. 요약 작업 및 내용 기존에 개발된 프로그램에 따라 통계적 관찰 자료를 과학적으로 조직화하여 처리하는 것 외에 자료 관리, 체계화, 자료 그룹화, 도표화, 결과 도출 및 도출 지표(평균 및 상대값) 등이 포함됩니다. 통계 과정에서 수집된 자료 관찰은 연구 중인 현상의 개별 단위에 대한 이질적인 기본 정보입니다. 이 형식에서 재료는 아직 현상 전체를 특성화하지 않습니다. 현상의 크기(수)나 구성, 특징적인 특징의 크기 또는 대략적인 정보를 제공하지 않습니다. 이 현상과 다른 현상 간의 연결의 본질 등. 통계 데이터의 특수 처리-관찰 자료 요약이 필요합니다. 관찰 자료의 요약은 전체적으로 연구 중인 현상에 고유한 전형적인 특징과 패턴을 감지하기 위해 집합을 형성하는 특정 단일 데이터를 일반화하는 일련의 순차적 작업입니다. 좁은 의미의 통계 요약(simple summary)은 관측 단위 집합에 대한 전체 요약(summary) 데이터를 계산하는 연산이다. 넓은 의미의 통계 요약(복잡한 요약)에는 관찰 데이터 그룹화, 일반 및 그룹 총계 계산, 상호 관련된 지표 시스템 획득, 그룹화 및 요약 결과를 통계 테이블 형태로 표시합니다. 예비 심층 이론적 분석을 기반으로 한 정확하고 과학적으로 구성된 요약을 통해 연구 대상의 가장 중요하고 특징적인 특징을 반영하는 모든 통계적 결과를 얻고 다양한 요인이 결과에 미치는 영향을 측정하고 이 모든 것을 수행할 수 있습니다. 현재 및 장기 계획을 세울 때 실제 작업에서 고려합니다. 요약의 임무는 통계 지표 시스템의 도움으로 연구 대상을 특성화하고 이러한 방식으로 필수 기능과 특징을 식별하고 측정하는 것입니다. 이 작업은 세 단계로 해결됩니다. - 그룹 및 하위 그룹의 정의 - 지표 시스템의 정의; - 테이블 유형의 정의. 첫 번째 단계에서는 관찰 중에 수집된 자료를 체계화하고 그룹화합니다. 두 번째 단계에서는 계획에서 제공하는 지표 시스템이 지정되어 연구 대상의 특성과 특징을 정량적으로 특성화합니다. 세 번째 단계에서는 지표 자체를 계산하고 일반화된 데이터를 표, 통계 시리즈, 그래프 및 다이어그램으로 표시하여 명확성과 편의를 제공합니다. 구현이 시작되기 전에도 요약의 나열된 단계는 특별히 컴파일 된 프로그램에 반영됩니다. 통계 요약 프로그램에는 그룹화 특성에 따라 인구, 경계를 나누는 것이 권장되는 그룹 목록이 포함되어 있습니다. 전체를 특징 짓는 지표 시스템 및 계산 방법; 계산 결과가 표시되는 개발 테이블 레이아웃 시스템. 프로그램과 함께 조직에 제공되는 요약 계획이 있습니다. 요약 수행 계획에는 개별 부분의 구현 순서와 시기, 구현 책임자, 결과 발표 절차에 대한 지침이 포함되어야 하며, 관련된 모든 조직의 작업 조정도 제공해야 합니다. 구현. 3.2. 주요 업무 및 그룹 유형 통계 연구의 주제 - 사회 생활의 대중 현상과 과정 -은 많은 특징과 속성을 가지고 있습니다. 데이터 처리의 특정 과학적 원칙 없이는 통계 데이터를 일반화하고 가장 중요한 특징, 전체 및 개별 구성 요소의 발전 형태를 드러내는 것이 불가능합니다. 통계적 관찰 대상의 개별적 다양성을 극복하지 못한 채, 현상이나 과정 전체의 발전 패턴은 각각의 대상을 서로 구분하는 세부 사항과 하찮은 부분에서 소실되고, 궁극적인 일반화는 왜곡된 관념을 수반한다. 현실. 단위 집합을 동일한 유형의 그룹으로 분리하기 위해 통계는 그룹화 방법을 사용합니다. 통계 그룹화는 통계 요약의 첫 번째 단계로, 초기 통계 자료의 질량에서 질적 및 양적 측면에서 일반적으로 유사한 단위의 균질한 그룹을 골라낼 수 있습니다. 그룹화는 인구를 부분으로 나누는 주관적인 기술이 아니라 특정 속성에 따라 인구 단위 집합을 나누는 과학적 기반 프로세스임을 이해하는 것이 중요합니다. 그룹화 방법을 적용하는 기본 원칙은 연구 중인 현상의 본질과 본질에 대한 포괄적이고 심층적인 분석으로, 이를 통해 해당 현상의 전형적인 특성과 내부 차이점을 결정할 수 있습니다. 모든 일반 컬렉션은 특정 컬렉션의 복합체이며, 각 컬렉션은 특정 유형의 현상을 특정 측면에서 동일한 품질로 결합합니다. 각 유형(그룹)에는 해당 수준의 양적 값이 있는 특정 기능 시스템이 있습니다. 그룹화를 수행해야 하는 필수 기능에 대한 정확하고 명확한 정의에 기초하여 일반 인구의 그룹화된 단위가 어떤 유형, 특정 인구에 속하는지 결정합니다. 이것은 과학 기반 그룹화의 두 번째 중요한 요구 사항입니다. 세 번째 그룹화 요구 사항은 형성된 그룹이 인구의 동종 요소를 통합해야 하고 그룹 자체(다른 하나와 관련하여)가 크게 달라야 한다는 전제 하에 그룹 경계의 객관적이고 합리적인 설정을 기반으로 합니다. 그렇지 않으면 그룹화는 의미가 없습니다. 따라서 그룹화 방법의 적용을 기반으로 인구 단위의 유사성과 차이의 원칙에 따라 그룹이 결정됩니다. 유사성은 특정 한계(그룹) 내에서 단위의 동질성입니다. 차이점은 그룹에서 상당한 차이가 있다는 것입니다. 따라서 그룹화는 하나 이상의 필수 특성에 따라 단위의 총 인구를 질적 및 양적으로 다른 동질적인 그룹으로 나누고 사회 경제적 유형을 선택하거나 인구 구조를 연구하거나 간의 관계를 분석할 수 있도록 합니다. 개별 특성. 다양한 사회 현상과 연구 목표로 인해 많은 통계적 현상 그룹을 사용하고 이를 기반으로 다양한 특정 문제를 해결할 수 있습니다. 통계에서 그룹화의 도움으로 해결되는 주요 작업은 다음과 같습니다. - 사회 경제적 유형의 연구 현상 전체에서 선택; - 사회 현상의 구조 연구; - 사회 현상 간의 연결 및 종속성 식별. 사회 경제적 유형의 연구 현상 전체에서 할당과 관련된 모든 그룹은 통계에서 중심적인 위치를 차지합니다. 이 작업은 사회적 지위, 성별, 연령, 교육 수준에 따라 인구를 그룹화하고 소유 형태, 업계 소속에 따라 기업 및 조직을 그룹화하는 것과 같이 공적 생활의 가장 중요하고 결정적인 측면과 관련이 있습니다. 장기간에 걸쳐 이러한 그룹을 구성하면 사회 경제적 관계의 발전 과정을 추적 할 수 있습니다. 사회 현상의 전체를 사회 경제적 유형에 따라 나누는 작업은 유형 학적 그룹을 구성하여 해결됩니다. 따라서 유형 학적 그룹화는 질적으로 이질적인 연구 인구를 사회 경제적 유형에 따라 동질적인 단위 그룹으로 나누는 것입니다. 유형 학적 그룹화의 예는 다음과 같은 주요 관계 그룹으로 나눌 수 있는 지역 중 하나에서 혁신 활동에 참여하는 주제 유형에 따른 그룹화입니다(표 3.1). 표 3.1 혁신 활동 주제 그룹화 
사회 현상의 구조 연구, 즉 특정 유형의 현상 구성 차이 연구(현상의 구성 요소 간의 상관 관계, 특정 기간에 대한 이러한 비율의 변화에 대한 연구)가 매우 중요합니다. ). 따라서 구조적 그룹화는 균질한 인구가 몇 가지 다양한 기능에 따라 구조를 특징짓는 그룹으로 나누어지는 그룹화입니다. 구조적 그룹화에는 성별, 연령, 교육 수준에 따른 인구 그룹화, 직원 수에 따른 기업 그룹화, 임금 수준, 작업량 등이 포함됩니다. 사회 현상의 구조 변화는 가장 중요한 것을 반영합니다. 그들의 발달 패턴. 예를 들어, 테이블의 그룹화. 그림 3.2는 1959년과 1994년 사이에 도시 인구는 꾸준히 증가했지만 농촌 인구는 감소했지만 1994년과 2002년 사이에 이들 인구 그룹의 비율은 변하지 않았음을 보여줍니다. 표 3.2 1959-2002년 거주지별 러시아 인구 그룹화 
구조적 그룹화를 사용하면 인구 구조를 밝힐 수 있을 뿐만 아니라 연구 중인 프로세스, 강도, 공간 변화 및 여러 기간에 걸쳐 취해진 구조적 그룹화를 분석할 수 있습니다. 시간에 따른 인구 구성. 구조적 그룹은 속성 또는 양적 기능을 기반으로 할 수 있습니다. 그들의 선택은 특정 연구의 목적과 연구 대상 인구의 특성에 따라 결정됩니다. 표에 주어진 그룹화. 3.2, 속성 기반으로 구축. 양적 속성에 따른 구조적 그룹핑의 경우 그룹의 수와 경계를 결정해야 합니다. 이 문제는 연구의 목적에 따라 해결됩니다. 하나의 동일한 통계 자료를 연구의 목적과 목적에 따라 다른 방식으로 그룹으로 나눌 수 있습니다. 가장 중요한 것은 그룹화 과정에서 연구 중인 현상의 특징이 명확하게 반영되어야 하고 특정 결론 및 권장 사항을 위한 전제 조건이 생성되어야 한다는 것입니다. 테이블에서. 3.3은 정량적 속성에 따른 구조적 그룹화를 나타낸다. 표 3.3 1996인당 평균 소득으로 상트페테르부르크 거주자 가족 그룹화(XNUMX년 XNUMX월 - XNUMX월 데이터에 따름) 
이 표에서 그룹의 간격은 크기가 같습니다. 등간격을 사용하는 경우 해당 값은 공식에 따라 계산됩니다. 
여기서 h는 간격의 값, xmax 및 xmin은 모집단 특성의 최대값과 최소값, k는 그룹 수입니다. 등간격을 다루는 것이 기술적으로 더 편리하지만 연구되는 현상과 특징의 특성으로 인해 항상 가능한 것은 아니라는 점에 유의해야 합니다. 경제에서는 경제 현상의 본질 때문에 불평등하고 점진적으로 증가하는 간격을 적용하는 것이 더 자주 필요합니다. 같지 않은 간격의 사용은 주로 같은 값에 의한 그룹화 특성의 절대 변화가 특성의 크고 작은 값을 가진 그룹에 대한 동일한 값과 거리가 멀다는 사실에 기인합니다. 예를 들어, 직원이 300명 이하인 두 기업 사이에서 직원 100명의 차이는 직원이 10명 이상인 기업보다 더 중요합니다. 그룹 간격은 하한 및 상한이 지정되면 닫히고 그룹 경계 중 하나만 지정되면 열 수 있습니다. 개방 간격은 극단 그룹에만 적용됩니다. 동일하지 않은 간격으로 그룹화하는 경우 닫힌 간격으로 그룹을 형성하는 것이 바람직합니다. 이것은 통계 계산의 정확성에 기여합니다. 통계적 관찰의 목표 중 하나는 사회 현상 간의 연결과 종속성을 식별하는 것입니다. 동일한 질적 모집단 내에서 유형학적 그룹화를 기반으로 수행되는 통계 분석의 중요한 작업은 개별 기능 간의 관계를 연구하고 측정하는 작업입니다. 분석적 그룹화는 그러한 연결의 존재를 확립하는 것을 가능하게 합니다. 분석적 그룹화는 기능의 일반화된 값을 그룹별로 병렬 비교하여 발견되는 관계에 대한 통계적 연구의 일반적인 방법입니다. 종속 기호가 있으며, 그 값은 다른 기호의 영향으로 변경되며 일반적으로 통계에서 효과적이라고하며 다른 기호에 영향을 미치는 요인입니다. 일반적으로 분석 그룹화의 기초는 부호 요인이며 유효 부호에 따라 그룹 평균이 계산되며 값의 변화는 부호 사이의 관계의 존재를 결정합니다. 따라서 이러한 그룹화를 분석적이라고 할 수 있으므로 동일한 유형의 인구 단위의 생산 특성과 요인 특성 간의 관계를 설정하고 연구할 수 있습니다. 분석적 그룹화의 중요한 문제는 그룹 수를 올바르게 선택하고 경계를 결정하여 연결 특성의 객관성을 보장하는 것입니다. 분석은 단일 정성 집계로 수행되기 때문에 특정 유형을 분할할 이론적 근거가 없으므로 특정 분석에 대한 특정 요구 사항 및 조건을 충족하는 여러 그룹으로 인구를 분할하는 것이 허용됩니다. 분석적 그룹화 과정에서 일반적인 그룹화 규칙을 준수해야 합니다. 즉, 형성된 그룹의 단위는 크게 달라야 하고 그룹의 단위 수는 신뢰할 수 있는 통계적 특성을 계산하기에 충분해야 합니다. 또한 그룹 평균은 일정한 패턴을 따라야 합니다. 지속적으로 증가하거나 감소합니다. 통계적 관찰 데이터의 직접 그룹화는 기본 그룹화입니다. XNUMX차 그룹화 - 이전에 그룹화된 데이터를 재그룹화합니다. XNUMX차 그룹화의 필요성은 두 가지 경우에 발생합니다. - 이전에 생성된 그룹화는 그룹 수와 관련하여 연구 목적을 충족하지 않습니다. - 다른 그룹화 특성에 따라 또는 다른 간격으로 기본 그룹화가 수행된 경우 다른 기간 또는 다른 영역과 관련된 데이터를 비교합니다. XNUMX차 그룹화에는 두 가지 방법이 있습니다. - 작은 그룹을 더 큰 그룹으로 통합 - 특정 비율의 인구 단위 선택. 과학적으로 입증 된 사회 현상 그룹화에서는 현상의 상호 의존성과 현상의 점진적인 양적 변화가 근본적인 질적 변화로 전환 될 가능성을 고려해야합니다. 그룹화는 그룹화의 인지적 목표가 결정될 뿐만 아니라 그룹화의 기초인 그룹화 속성이 올바르게 선택되어야만 과학적일 수 있습니다. 그룹핑이 어떤 속성에 따라 동질적인 그룹으로의 분포 또는 인구의 개별 단위를 어떤 속성에 따라 동질적인 그룹으로 연결하는 것이라면, 그룹화 속성은 인구의 개별 단위가 개별적으로 결합되는 기호입니다. 여러 떼. 그룹화 속성을 선택할 때 중요한 것은 속성을 표현하는 방식이 아니라 연구 중인 현상에 대한 중요성입니다. 이러한 관점에서 그룹화를 위해서는 연구 중인 현상의 가장 특징적인 특징을 표현하는 본질적인 특징을 취해야 한다. 가장 간단한 그룹화는 분포 계열입니다. 분포 계열은이 현상에 대한 통계 데이터를 그룹화 한 후 현상의 구성 또는 구조를 특성화하는 일련의 숫자 (숫자)입니다. 즉, 하나의 지표가 그룹을 특성화하는 데 사용되는 그룹화, 즉 그룹의 크기입니다. 분포 계열을 사용하는 예는 표에 나와 있습니다. 3.4. 표 3.4 유통 시리즈의 적용 
위의 배포 시리즈에는 세 가지 요소가 포함되어 있습니다. 속성 유형(남성, 여성); 분포 계열의 빈도라고 하는 각 그룹의 단위 수. 주파수라고 하는 총 단위 수의 몫(백분율)으로 표시되는 그룹 수. 빈도의 합은 1의 분수로 표시하면 100이고 백분율로 표시하면 XNUMX%입니다. 속성 기반으로 작성된 행을 속성이라고 합니다. 정량적 기반으로 구축된 분포 계열을 변이 계열이라고 합니다. 변이 분포 계열에서 양적 속성의 수치 값을 변종이라고 하며 특정 순서로 배열됩니다. 변형은 양수와 음수, 절대 및 상대적으로 표현할 수 있습니다. 변이 계열은 이산 계열과 간격 계열로 나뉩니다. 이산 변이 계열은 이산(불연속) 속성, 즉 정수 값을 취하는 속성에 따라 모집단 단위의 분포를 특성화합니다. 특징의 불연속적 변형으로 분포 시리즈를 구성할 때 모든 변형은 값의 오름차순으로 작성되며 변형의 동일한 값(예: 빈도)이 반복되는 횟수를 계산하여 한 줄에 기록합니다. 변형의 해당 값, 예를 들어 자녀 수에 따른 가족 분포(표 3.5). 속성 계열뿐만 아니라 이산 변형 계열의 주파수는 주파수로 대체될 수 있습니다. 표 3.5 이산 분포 시리즈의 적용 
지속적인 변동의 경우 속성 값은 소득 수준에 따른 회사 직원 분포와 같이 특정 간격의 모든 값을 취할 수 있습니다(표 3.6). 표 3.6 연속변동의 경우 
구간 변이 계열을 구성할 때 최적의 그룹 수(특징의 구간)를 선택하고 구간의 길이를 설정해야 합니다. 최적의 그룹 수는 모집단의 특성 값의 다양성을 반영하도록 선택됩니다. 대부분의 경우 그룹 수는 공식에 의해 결정됩니다. k = 1 + 3,32lg N = 1,44ln N + 1, 여기서 k는 그룹의 수입니다. N - 인구 규모. 예를 들어, 곡물 수확량에 따라 변형된 일련의 농업 기업을 구축해야 합니다. 농업 기업 수 - 143. 그룹 수를 결정하는 방법은 무엇입니까? k = 1 + 3,32lg N = 1 + 3,32lg143 = 8,16. 그룹 수는 정수만 가능하며 이 경우 8 또는 9입니다. 예시. 최소 생산량은 30q/ha, 최대값은 70q/ha, 대상 그룹 수는 10입니다. 간격 값은 공식 (3.1)을 사용하여 계산할 수 있습니다. 
결과 그룹화가 분석 요구 사항을 충족하지 않으면 다시 그룹화할 수 있습니다. 그러한 그룹화에서 그룹 간의 차이가 종종 사라지기 때문에 매우 많은 수의 그룹에 대해 노력해서는 안됩니다. 또한 인구의 여러 단위를 포함하여 너무 작은 그룹의 형성을 피할 필요가 있습니다. 그러한 그룹에서는 큰 수의 법칙이 작동하지 않고 임의성이 가능하기 때문입니다. 가능한 그룹을 즉시 식별할 수 없는 경우 수집된 자료를 먼저 상당한 수의 그룹으로 나눈 다음 확대하여 그룹 수를 줄이고 질적으로 균질한 그룹을 만듭니다. 따라서 모든 경우의 그룹화는 그 안에 형성된 그룹이 현실과 최대한 일치하고 그룹 간의 차이점이 가시적이며 서로 크게 다른 현상이 하나의 그룹으로 결합되지 않는 방식으로 구성되어야 합니다. 3.3. 통계표 통계적 관찰 데이터를 수집하고 그룹화한 후에도 시각적인 체계화 없이는 인식하고 분석하기가 어렵습니다. 통계 요약 및 그룹화 결과는 통계 테이블 형식으로 제공됩니다. 통계 테이블은 통계 모집단에 대한 정량적 설명을 제공하며 결과 통계 요약 및 숫자(숫자) 데이터 그룹화를 시각적으로 표시한 형태입니다. 외관상 테이블은 수직 및 수평 행의 조합입니다. 공통 측면 및 상단 제목이 있어야 합니다. 통계표의 또 다른 특징은 주제(통계 모집단의 특성)와 술어(인구를 특징짓는 지표)의 존재입니다. 통계표는 요약 또는 그룹화의 결과를 표시하는 가장 합리적인 형식입니다. 표의 주제는 표에 언급된 통계적 모집단, 즉 모집단 또는 그 그룹의 개인 또는 모든 단위의 목록을 나타냅니다. 대부분의 경우 주제는 테이블의 왼쪽에 배치되고 문자열 목록을 포함합니다. 표의 술어는 표에 표시된 현상의 특성이 제공되는 지표입니다. 표의 주어와 술어는 다양한 방식으로 배열될 수 있으며, 가장 중요한 것은 표가 읽기 쉽고 간결하며 이해하기 쉽다는 것입니다. 통계 실습 및 연구 작업에서는 다양한 복잡성의 테이블이 사용됩니다. 연구 대상 인구의 특성, 사용 가능한 정보의 양, 분석 작업에 따라 다릅니다. 표의 주제에 객체 또는 영토 단위의 간단한 목록이 포함되어 있으면 표를 단순이라고 합니다. 단순 테이블의 주제에는 통계 데이터 그룹이 포함되어 있지 않습니다. 이 테이블은 인구, 평균 급여 등의 측면에서 러시아 연방 도시의 특성과 같이 통계 관행에서 가장 광범위하게 적용됩니다. , 자치구, 공화국 등 그러한 테이블을 영토라고합니다. 간단한 테이블에는 설명 정보만 포함되며 분석 기능이 제한됩니다. 연구 인구에 대한 심층 분석, 표시의 관계에는 그룹 및 조합과 같은 더 복잡한 테이블의 구성이 포함됩니다. 그룹 테이블은 단순한 테이블과 달리 관찰 대상의 단순한 목록이 아니라 하나의 필수 속성에 따른 그룹화를 주제에 포함합니다. 가장 간단한 유형의 그룹 테이블은 분포 계열이 표시되는 테이블입니다(표 3.6 참조). 술어에 각 그룹의 단위 수뿐만 아니라 주제 그룹을 양적 및 질적으로 특성화하는 기타 여러 중요한 지표가 포함된 경우 그룹 테이블이 더 복잡할 수 있습니다. 이러한 표는 그룹 간에 요약 지표를 비교하는 데 자주 사용되며, 이를 통해 특정 실용적인 결론을 도출할 수 있습니다. 조합표는 더 넓은 분석 가능성을 가지고 있습니다. 조합 테이블은 하나의 속성에 따라 형성된 단위 그룹이 하나 이상의 속성에 따라 하위 그룹으로 분할되는 주제에서 통계 테이블이라고 합니다. 단순 및 그룹 테이블과 달리 조합 테이블을 사용하면 주제에서 조합 그룹화의 기초를 형성한 여러 기능에 대한 술어 표시기의 종속성을 추적할 수 있습니다. 위에 나열된 표와 함께 분할표 또는 빈도표가 통계 실습에 사용됩니다. 이러한 테이블의 구성은 수준이라고 하는 두 가지 이상의 특성에 따라 인구 단위를 그룹화하는 것을 기반으로 합니다. 예를 들어, 인구는 성별(남성, 여성) 등으로 나뉩니다. 따라서 기능 A에는 A1, A2, An(이 예에서는 n = 2)과 같은 n 등급(또는 수준)이 있습니다. 다음으로, 특징 A와 다른 특징 B의 상호 작용을 연구하며, 이는 m 계조(인자) B1, B2, ..., Bm으로 세분화됩니다. 이 예에서 속성 B는 직업에 속하고 B1, B2, Bm은 특정 값(의사, 운전사, 교사, 건축업자 등)을 취합니다. 두 개 이상의 기능으로 그룹화하면 기능 A와 B 간의 관계를 평가하는 데 사용됩니다. 관찰 결과는 n개의 행과 m개의 열로 구성된 분할표로 나타낼 수 있으며, 그 셀의 셀에는 이벤트 빈도 nij, 즉 수준 Aj와 Bj가 결합된 샘플 개체의 수가 포함됩니다.. 변수 A와 B 사이에 일대일 직접 또는 피드백 기능 관계가 있는 경우 모든 주파수 nij는 테이블의 대각선 중 하나를 따라 집중됩니다. 그다지 강력하지 않은 연결로 인해 특정 수의 관측값도 비대각선 요소에 해당합니다. 이러한 조건에서 연구자는 다른 값에서 한 특성의 값을 얼마나 정확하게 예측할 수 있는지 알아내야 하는 과제에 직면해 있습니다. 빈도표는 단 하나의 변수만 표로 만들어지면 XNUMX차원이라고 합니다. 두 개의 특성(요인)으로 표로 작성된 두 개의 특성(수준)에 의한 그룹화를 기반으로 하는 테이블을 두 개의 입력이 있는 테이블이라고 합니다. 두 개 이상의 기능 값이 표로 작성된 빈도 표를 분할표라고 합니다. 모든 유형의 통계표 중에서 단순표가 가장 널리 사용되며, 그룹 및 특히 조합 통계표는 덜 자주 사용되며, 분할표는 특수한 유형의 분석을 위해 작성됩니다. 통계표는 대중 사회 현상을 표현하고 연구하는 중요한 방법 중 하나이지만 올바르게 구성되어야합니다. 통계표의 형식은 그것이 표현하는 현상의 본질과 연구 목적에 가장 잘 맞아야 합니다. 이것은 표의 주제와 술어를 적절하게 개발함으로써 달성됩니다. 외부적으로 테이블은 작고 컴팩트해야 하며 제목, 측정 단위 표시, 정보와 관련된 시간 및 장소가 있어야 합니다. 표의 행 머리글과 열은 간략하지만 명확하게 제공됩니다. 디지털 데이터가 포함된 테이블이 너무 복잡하고 조잡한 디자인으로 인해 테이블을 읽고 분석하기가 어렵습니다. 통계 테이블을 구성하는 기본 규칙을 나열합니다. - 테이블은 간결해야 하며 정적 및 역학에서 연구 중인 사회경제적 현상을 직접적으로 반영하는 초기 데이터만 반영해야 합니다. - 표의 제목, 열과 행의 이름은 명확하고 간결하며 간결해야 합니다. 제목은 이벤트의 대상, 기호, 시간 및 장소를 반영해야 합니다. - 열과 줄에 번호를 매겨야 합니다. - 열과 줄에는 일반적으로 허용되는 약어가 있는 측정 단위가 포함되어야 합니다. - 분석 중 비교되는 정보는 인접한 열(또는 다른 열 아래)에 가장 잘 배치됩니다. 이렇게 하면 비교 프로세스가 더 쉬워집니다. - 읽기와 작업을 쉽게 하기 위해 통계표의 숫자는 열 중앙에 위치해야 합니다. - 동일한 정확도로 숫자를 반올림하는 것이 좋습니다(최대 전체 부호, 최대 XNUMX분의 XNUMX까지). - 데이터의 부재는 곱셈 기호(x)로 표시되고, 이 위치가 채워지지 않을 경우 정보 부재는 줄임표(...) 또는 "n.d." 또는 "n.s."로 표시됩니다. 현상이 없으면 대시가 표시됩니다(-). - 매우 작은 숫자를 표시하려면 0.0 또는 0.00을 사용하십시오. - 조건부 계산을 기반으로 숫자를 얻은 경우 괄호로 묶고 의심스러운 숫자에는 물음표가, 예비 숫자에는 기호(*)가 표시됩니다. 추가 정보가 필요한 경우 통계 표에는 각주와 함께 특정 지표의 특성, 적용된 방법론 등을 설명하는 참고가 있습니다. 각주는 표를 읽을 때 고려해야 하는 제한된 상황을 나타내는 데 사용됩니다. 이러한 규칙이 준수되면 통계 테이블은 연구된 사회 경제적 현상의 상태 및 발전에 대한 통계 정보를 제시, 처리 및 요약하는 주요 수단이 됩니다. 3.4. 통계 정보의 그래픽 표현 전체적으로 요약 또는 통계 분석의 결과로 얻은 수치 지표는 표 형식뿐만 아니라 그래픽 형식으로 표시될 수 있습니다. 통계 정보를 표시하기 위해 그래프를 사용하면 통계 데이터에 시각화 및 표현력을 부여하고 인식을 용이하게 하며 많은 경우 분석을 수행할 수 있습니다. 통계 지표의 다양한 그래픽 표현은 현상이나 과정을 가장 표현적으로 보여줄 수 있는 좋은 기회를 제공합니다. 통계의 그래프는 점, 선, 평평한 그림 등 다양한 기하학적 이미지의 형태로 수치 값과 비율의 조건부 표현입니다. 통계 그래프를 사용하면 연구 중인 현상의 특성을 즉시 평가할 수 있습니다. 고유한 패턴 및 기능, 개발 동향, 지표를 특징짓는 관계 . 각 그래프는 그래픽 이미지와 보조 요소로 구성됩니다. 그래픽 이미지는 통계 데이터를 나타내는 데 사용되는 점, 선 및 그림의 모음입니다. 그래프의 보조 요소에는 그래프의 공통 이름, 좌표축, 눈금, 숫자 그리드 및 표시된 표시기를 보완하고 구체화하는 숫자 데이터가 포함됩니다. 보조 요소는 그래프의 읽기와 해석을 용이하게 합니다. 차트의 제목은 내용을 간략하고 정확하게 설명해야 합니다. 설명 텍스트는 그래픽 이미지 내부 또는 옆에 위치하거나 외부에 위치할 수 있습니다. 눈금이 인쇄된 좌표축과 숫자 그리드는 플롯하고 사용하는 데 필요합니다. 비늘은 직선 또는 곡선(원형), 균일(선형) 및 고르지 않을 수 있습니다. 때로는 하나 또는 두 개의 평행선에 구축된 소위 켤레 스케일을 사용하는 것이 좋습니다. 가장 자주 켤레 척도 중 하나는 절대 값을 읽는 데 사용되며 두 번째는 해당 상대 값을 읽는 데 사용됩니다. 저울의 숫자는 균등하게 내려 놓고 마지막 숫자는이 저울에서 측정되는 표시기의 최대 레벨을 초과해야합니다. 일반적으로 숫자 그리드에는 기준선이 있어야 하며 그 역할은 일반적으로 x축에서 수행됩니다. 통계 그래프는 그래픽 이미지의 목적(내용), 구성 방법 및 특성과 같은 다양한 기준에 따라 분류할 수 있습니다. 내용 또는 목적에 따라 다음을 구별할 수 있습니다.
그래픽을 구성하는 방법에 따라 차트와 통계 맵으로 나눌 수 있습니다. 차트는 그래픽 표현의 가장 일반적인 방법입니다. 이것은 양적 관계의 그래프입니다. 건설의 유형과 방법은 다양합니다. 다이어그램은 영역, 인구 등 서로 독립적인 값의 다양한 측면(공간적, 시간적 등)에서 시각적 비교에 사용됩니다. 이 경우 연구된 인구의 비교는 몇 가지 중요한 변화에 따라 수행됩니다. 기인하다. 통계 지도 - 표면에 대한 정량적 분포 그래프. 주요 목적에서 그들은 다이어그램에 밀접하게 인접하고 등고선 지리적지도에서 통계 데이터의 조건부 표현을 나타내기 때문에 구체적입니다. 즉, 통계 데이터의 공간 분포 또는 공간 분포를 보여줍니다. 그래픽 이미지의 특성에 따라 점, 선, 평면(기둥, 스트립, 정사각형, 원형, 부채꼴, 곱슬) 및 체적 그래픽이 있습니다. 산점도를 구성할 때 점 집합을 그래픽 이미지로 사용하고 선형 다이어그램을 구성할 때 선을 사용합니다. 모든 평면도를 구성하는 기본 원리는 통계량을 기하 도형으로 표현하는 것입니다. 그래픽적으로 통계 지도는 지도와 지도로 나뉩니다. 해결해야 할 작업의 범위에 따라 비교 다이어그램, 구조 다이어그램 및 역학 다이어그램이 구별됩니다. 가장 일반적인 비교 차트는 막대 차트이며, 그 구성 원칙은 수직으로 배치된 직사각형(막대) 형태로 통계 지표를 표시하는 것입니다. 각 막대는 연구된 통계 계열의 개별 수준 값을 나타냅니다. 따라서 모든 비교 지표가 하나의 측정 단위로 표현되기 때문에 통계 지표의 비교가 가능합니다. 막대 차트를 작성할 때 선 체계를 그릴 필요가 있습니다. 열이 위치한 각도 좌표. 기둥의 기단은 가로축에 위치하며, 기단의 크기는 임의로 정하지만 모든 사람에게 동일하게 설정됩니다. 기둥의 높이를 결정하는 축척은 세로축을 따라 위치합니다. 각 막대의 세로 크기는 차트에 표시되는 통계의 크기에 해당합니다. 따라서 차트를 구성하는 모든 막대에 대해 하나의 차원만 변수입니다. 그래프 필드의 열 배치는 다음과 같이 다를 수 있습니다. 서로 같은 거리에; 서로 가까이; 부분적으로 겹칩니다. 막대 차트를 구성하는 규칙을 사용하면 동일한 수평 축에 여러 지표의 이미지를 동시에 배치할 수 있습니다. 이 경우 열은 그룹으로 배열되며 각각에 대해 다양한 기능의 다른 차원을 취할 수 있습니다. 막대 차트의 종류는 소위 스트립 및 스트립 차트입니다. 그들의 차이점은 스케일이 상단에 수평으로 위치하고 길이를 따라 스트립의 크기를 결정한다는 사실에 있습니다. 막대 차트와 스트립 차트의 범위는 구성 규칙이 동일하기 때문에 동일합니다. 표시된 통계 지표의 XNUMX차원성 및 다양한 열 및 밴드에 대한 XNUMX척도는 비례(열 - 높이, 줄무늬 - 길이) 및 표시된 값에 대한 비례 준수라는 단일 조항의 이행을 필요로 합니다. 이 요구 사항을 충족하려면 먼저 열(밴드)의 크기가 설정되는 척도가 XNUMX부터 시작해야 합니다. 둘째, 이 척도는 연속적이어야 합니다. 즉, 주어진 통계 계열의 모든 숫자를 포함해야 합니다. 스케일의 중단 및 그에 따른 열(밴드)은 허용되지 않습니다. 이러한 규칙을 준수하지 않으면 분석된 통계 자료의 그래픽 표현이 왜곡됩니다. 통계 데이터의 그래픽 표현 방법인 막대 및 막대 차트는 서로 바꿔 사용할 수 있습니다. 즉, 고려되는 통계 지표는 막대와 막대로 동등하게 표시될 수 있습니다. 두 경우 모두 현상의 크기를 나타내기 위해 각 직사각형의 한 측정값(기둥의 높이 또는 스트립의 길이)이 사용되므로 이 두 다이어그램의 범위는 기본적으로 동일합니다. 다양한 막대 및 스트립 차트는 방향 차트입니다. 그들은 기둥이나 줄무늬의 일반적인 양면 배열과 다르며 중간에 눈금 원점이 있습니다. 일반적으로 이러한 다이어그램은 반대 질적 값의 값을 표시하는 데 사용됩니다. 다른 방향으로 향한 기둥이나 스트립 사이의 비교는 같은 방향으로 나란히 위치한 것보다 덜 효과적입니다. 그럼에도 불구하고 방향 다이어그램을 분석하면 특별한 배열이 그래프에 밝은 이미지를 제공하기 때문에 의미 있는 결론을 도출할 수 있습니다. 양측 그룹에는 순수 편차의 다이어그램이 포함됩니다. 그들에서 줄무늬는 수직 제로 라인에서 양방향으로 지향됩니다. 오른쪽 - 성장, 왼쪽 - 감소. 이러한 다이어그램의 도움으로 계획과의 편차 또는 비교 기준으로 취한 일정 수준을 설명하는 것이 편리합니다. 고려 중인 다이어그램의 중요한 이점은 연구된 통계적 특성의 변동 범위를 볼 수 있다는 것입니다. 이는 그 자체로 분석에 매우 중요합니다. 서로 독립적인 지표의 간단한 비교를 위해 다이어그램을 사용할 수도 있습니다. 그 구성 원칙은 비교 값이 해당 영역이 이 수치가 표시하는 숫자입니다. 즉, 이 도표는 묘사된 현상의 크기를 면적의 크기로 표현한 것입니다. 해당 유형의 다이어그램을 얻으려면 정사각형, 원, 덜 자주 직사각형과 같은 다양한 기하학적 모양이 사용됩니다. 정사각형의 면적은 한 변의 제곱과 같고, 원의 면적은 반지름의 제곱에 비례하여 결정되므로 다이어그램을 작성하려면 먼저 정사각형을 추출해야 합니다. 비교 값에서 루트. 그런 다음 얻은 결과를 기반으로 허용 된 척도에 따라 정사각형의 측면 또는 원의 반경을 각각 결정해야합니다. 가장 표현하기 쉽고 인지하기 쉬운 것은 도형기호의 형태로 비교도를 구성하는 방법이다. 이때 통계적 집합체는 기하학적 수치가 아닌 기호나 기호로 표현되어 통계자료의 외적 이미지를 어느 정도 재현한다. 이 그래픽 표현 방법의 장점은 비교된 모집단의 내용을 반영하는 유사한 디스플레이를 얻을 수 있다는 점에서 높은 수준의 명확성에 있습니다. 모든 다이어그램의 가장 중요한 기능은 스케일이므로 곱슬 다이어그램을 올바르게 작성하려면 계정 단위를 결정해야 합니다. 후자에는 조건부로 특정 숫자 값이 할당되는 별도의 그림 (기호)이 사용됩니다. 그리고 연구 중인 통계적 값은 그림에 순차적으로 위치한 동일한 크기의 별도 숫자로 표시됩니다. 그러나 대부분의 경우 전체 숫자로 통계를 묘사하는 것은 불가능합니다. 스케일 측면에서 한 문자는 측정 단위가 너무 크기 때문에 마지막 문자는 부분으로 나누어야 합니다. 일반적으로이 부분은 눈으로 결정됩니다. 그것을 정확히 결정하기 어렵다는 것이 중괄호 다이어그램의 단점입니다. 그러나 통계 데이터 표시의 정확성을 높이는 것은 추구하지 않으며 결과는 상당히 만족스럽습니다. 일반적으로 그림 차트는 통계 및 광고를 대중화하는 데 널리 사용됩니다. 구조 다이어그램의 주요 구조는 각 집계의 서로 다른 부분의 비율로 특징지어지는 통계 집계의 구성을 그래픽으로 표현한 것입니다. 통계 모집단의 구성은 절대 및 상대 지표를 모두 사용하여 그래픽으로 나타낼 수 있습니다. 전자의 경우 부분의 크기뿐만 아니라 그래프 전체의 크기도 통계적 값에 의해 결정되며 후자의 변화에 따라 변화한다. 두 번째에서는 전체 그래프의 크기가 변경되지 않고(모든 집합의 모든 부분의 합이 100%이기 때문에) 개별 부분의 크기만 변경됩니다. 절대 및 상대적 지표 측면에서 인구 구성의 그래픽 표현은 심층 분석에 기여하고 사회 경제적 현상의 국제 비교 및 비교를 허용합니다. 통계적 모집단의 구조를 그래픽으로 표현하는 가장 일반적인 방법은 원형 차트이며, 이 목적을 위한 차트의 주요 형식으로 간주됩니다. 이는 전체의 개념이 전체를 반영하는 원으로 잘 표현되어 있기 때문이다. 원형 차트에서 모집단의 각 부분의 비중은 중심각(원의 반지름 사이의 각도) 값으로 특성화됩니다. 360°와 같은 원의 모든 각도의 합은 100%와 같으므로 1%는 3,6°와 같습니다. 원형 차트를 사용하면 인구 구조와 그 변화를 그래픽으로 묘사할 수 있을 뿐만 아니라 이 인구 규모의 역학을 보여줄 수 있습니다. 이를 위해 연구중인 특성의 양에 비례하는 원이 만들어진 다음 개별 부분이 섹터로 구별됩니다. 고려된 인구 구조의 그래픽 표현 방법에는 장점과 단점이 있습니다. 따라서 원형 차트는 소수의 인구 부분에서만 가시성과 표현력을 유지합니다. 그렇지 않으면 사용이 효과적이지 않습니다. 또한 원형 차트의 가시성은 묘사된 모집단의 구조가 약간 변경되면 감소합니다. 비교 구조의 차이가 더 중요하면 더 높아집니다. 원형 차트에 비해 막대 및 스트립 구조 차트의 장점은 용량이 크고 유용한 정보를 더 많이 반영할 수 있다는 것입니다. 그러나 이러한 차트는 연구 인구 구조의 작은 차이에 더 효과적입니다. 동적 다이어그램은 시간에 따른 현상의 발전을 묘사하고 판단하기 위해 만들어졌습니다. 일련의 역학에서 현상의 시각적 표현을 위해 막대, 스트립, 정사각형, 원형, 선형, 방사형 등의 다이어그램이 사용됩니다. 다이어그램 유형의 선택은 주로 초기 데이터의 특성, 목적 연구. 예를 들어, 시간적으로 여러 수준이 다른 일련의 역학이 있는 경우(1914, 1949, 1980, 1985, 1996, 2003) 명확성을 위해 막대, 정사각형 또는 원형 차트가 자주 사용됩니다. 시각적으로 인상적이고 잘 기억되지만 번거롭기 때문에 많은 수준을 표시하는 데 적합하지 않습니다. 일련의 역학에서 수준의 수가 많을 때 연속 파선의 형태로 개발 프로세스의 연속성을 재현하는 선 다이어그램을 사용하는 것이 좋습니다. 또한 꺾은선형 차트는 다음과 같은 경우에 사용하기 편리합니다. - 연구의 목적은 현상 발전의 일반적인 경향과 성격을 묘사하는 것입니다. - 하나의 그래프에서 비교하기 위해 여러 개의 동적 시리즈를 묘사해야 합니다. - 가장 중요한 것은 수준이 아닌 성장률의 비교입니다. 선 그래프를 작성하기 위해 직사각형 좌표 시스템이 사용됩니다. 일반적으로 시간은 가로축(년, 월 등)을 따라 표시되고 세로축(표시된 현상 또는 프로세스의 차원)을 따라 표시됩니다. 배율은 y축에 적용됩니다. 그래프의 일반적인 모양이 이것에 달려 있기 때문에 선택에 특별한주의를 기울여야합니다. 이 그래프에서는 좌표축 간의 불균형이 현상의 전개에 대한 잘못된 이미지를 제공하기 때문에 좌표축 간의 균형, 비례를 유지해야 합니다. 가로축의 눈금의 눈금이 y축의 눈금에 비해 크게 늘어나면 현상의 역동성의 변동이 거의 눈에 띄지 않고, 그 반대의 경우도 y축의 눈금의 증가가 y축의 눈금에 비해 크게 나타난다. 횡좌표의 눈금은 급격한 변동을 제공합니다. 동일한 기간 및 수준 크기는 동일한 규모 세그먼트에 해당해야 합니다. 통계적 실무에서는 균일한 축척의 그래픽 이미지가 가장 많이 사용됩니다. 가로 좌표를 따라 기간 수에 비례하고 세로 좌표를 따라 수준 자체에 비례하여 취합니다. 균일 스케일의 스케일은 단위로 취한 세그먼트의 길이가 됩니다. 종종 하나의 꺾은선형 차트에는 다양한 지표 또는 동일한 지표의 역학 관계에 대한 비교 설명을 제공하는 여러 곡선이 포함되어 있습니다. 그러나 하나의 그래프에 XNUMX~XNUMX개 이상의 곡선을 배치해서는 안 됩니다. 곡선이 많으면 필연적으로 도면이 복잡해지고 선형 다이어그램의 가시성이 떨어지기 때문입니다. 어떤 경우에는 하나의 그래프에 두 개의 곡선을 그리면 첫 번째 두 지표의 차이인 경우 세 번째 지표의 역학을 동시에 묘사할 수 있습니다. 예를 들어, 출산율과 사망률의 역학을 묘사할 때 두 곡선 사이의 면적은 인구의 자연적 증가 또는 자연적 감소의 양을 나타냅니다. 때로는 그래프에서 측정 단위가 다른 두 지표의 역학을 비교할 필요가 있습니다. 이러한 경우에는 하나가 아닌 두 개의 저울이 필요합니다. 그 중 하나는 오른쪽에, 다른 하나는 왼쪽에 배치됩니다. 그러나 이러한 곡선의 비교는 척도가 임의적이기 때문에 이러한 지표의 역학에 대한 충분히 완전한 그림을 제공하지 못하므로 두 가지 이질적인 지표 수준의 역학 비교는 다음을 기반으로 수행되어야 합니다. 절대값을 상대값으로 변환한 후 하나의 척도를 사용합니다. 선형 척도가 있는 선형 차트에는 인지 가치가 감소하는 한 가지 단점이 있습니다. 균일 척도를 사용하면 연구 기간 동안 다이어그램에 반영된 지표의 절대 증가 또는 감소만을 측정하고 비교할 수 있습니다. 그러나 역학을 연구할 때 연구 지표의 달성 수준 또는 변화 속도와 비교하여 상대적인 변화를 아는 것이 중요합니다. 역학의 경제 지표가 균일 한 수직 스케일의 좌표 다이어그램에 표시 될 때 왜곡되는 것은 상대적인 변화입니다. 또한, 기존의 좌표에서는 일반적으로 장기간에 걸쳐 시계열로 발생하는 급격한 수준 변화로 시계열을 묘사하는 것이 모든 명확성을 상실하고 심지어 불가능하게 되었습니다. 이러한 경우 균일 척도를 포기하고 그래프는 반대수 시스템을 기반으로 합니다. 반 로그 시스템의 기본 아이디어! 동일한 선형 세그먼트가 숫자 로그의 동일한 값에 해당한다는 사실로 구성됩니다. 이 접근 방식은 대수 등가를 통해 큰 수의 크기를 줄일 수 있다는 장점이 있습니다. 그러나 로그 형태의 스케일 스케일을 사용하면 그래프를 이해하기 어렵습니다. 스케일 스케일에 표시된 로그 옆에 표시된 로그 수에 해당하는 표시된 역학 시리즈의 수준을 특성화하여 숫자 자체를 적어야합니다. 이러한 종류의 그래프를 반대수 그리드의 그래프라고 합니다. semilogarithmic grid는 한 축에 선형 눈금이 표시되고 다른 축에 로그 눈금이 표시되는 그리드입니다. 역학은 극좌표로 구성된 방사형 다이어그램으로도 묘사됩니다. 방사형 다이어그램은 시간의 특정 리드미컬한 움직임을 시각적으로 표현하는 것을 목표로 합니다. 대부분의 경우 이러한 차트는 계절적 변동을 설명하는 데 사용됩니다. 방사형 다이어그램은 폐쇄형과 나선형으로 구분됩니다. 구성 기술에 따르면 방사형 다이어그램은 기준점으로 간주되는 항목(원의 중심 또는 원)에 따라 서로 다릅니다. 닫힌 다이어그램은 12년의 역학 관계의 연간 주기를 반영합니다. 나선형 차트! 몇 년 동안 역학의 연간 주기를 보여줍니다. 닫힌 다이어그램의 구성은 다음과 같이 축소됩니다. 원이 그려지고 월별 평균이 이 원의 반지름과 같습니다. 그런 다음 전체 원을 반지름과 동일한 1개 부분으로 나누고 그래프에 가는 선으로 표시합니다. 각 반지름은 월을 나타내며 월의 위치는 시계판과 유사합니다. 2월 - 시계가 XNUMX인 곳, XNUMX월 - XNUMX인 곳 등 해당 월의 데이터를 기준으로 척도에. 데이터가 연간 평균을 초과하는 경우 반지름 확장에 원 외부에 표시됩니다. 그런 다음 다른 달의 표시가 세그먼트로 연결됩니다. 그러나 원의 중심이 아니라 원을 보고서의 기준으로 삼는 경우 이러한 다이어그램을 나선형 다이어그램이라고 합니다. 나선형 차트의 구성은 한 해의 XNUMX월이 같은 해의 XNUMX월이 아니라 다음 해의 XNUMX월과 연결된다는 점에서 닫힌 차트와 다릅니다. 이것은 나선형의 형태로 전체 역학 시리즈를 묘사하는 것을 가능하게 합니다. 이러한 도표는 계절적 변화와 함께 해마다 꾸준한 증가가 있을 때 특히 예시적입니다. 통계 지도1는 특정 지역에서 특정 현상의 분포 수준 또는 정도를 특성화하는 개략적인 지리적 지도에 통계 데이터를 그래픽으로 표현한 유형입니다. 영토 분포를 묘사하는 수단은 해칭, 배경 채색 또는 기하학적 모양입니다. 카토그램과 카토그램이 있습니다. Cartograms는 다양한 밀도, 점 또는 채도의 채색의 해칭이 지도에 표시된 영토 분할의 각 단위 내 지표의 비교 강도를 나타내는 개략적인 지리적 지도입니다(예: 지역 또는 공화국별 인구 밀도 , 곡물 수확량 작물에 의한 지역 분포 등). 지도는 배경과 점으로 나뉩니다. 배경 지도(Background Cartogram) - 다양한 밀도의 음영이나 특정 채도의 채색이 영역 단위 내에서 지표의 강도를 나타내는 지도 그래프의 한 유형입니다. 도트 카토그램 - 선택한 현상의 수준을 도트로 표시하는 일종의 카토그램입니다. 점은 특정 기능이 나타나는 밀도 또는 빈도를 지리적 지도에 표시하는 집합체 또는 그 중 특정 수의 한 단위를 나타냅니다. 배경 지도는 일반적으로 평균 또는 상대 지표, 점 지도 그래프를 나타내는 데 사용됩니다. - 용적(정량적) 지표(인구, 가축 등) 두 번째 큰 통계 맵 그룹은 차트 다이어그램으로, 다이어그램과 지리적 맵의 조합입니다. 차트 그림(막대, 사각형, 원, 그림, 줄무늬)은 지도의 등고선에 배치되는 지도 문자의 비유적 기호로 사용됩니다. 카토그램을 사용하면 카토그램보다 지리적으로 더 복잡한 통계 및 지리적 구성을 반영할 수 있습니다. cartodigram 중에서 단순 비교의 cartodiacs, 공간 변위 그래프, isolines를 선별하는 것이 필요합니다. 단순 비교의 카토그램에서는 일반 차트와 달리 연구 중인 지표의 값을 나타내는 차트 그림이 일반 차트와 같이 일렬로 배열되지 않고 지역에 따라 맵 전체에 퍼져 있습니다. , 그들이 대표하는 지역 또는 국가. 가장 단순한 지도 제작 다이어그램의 요소는 정치 지도에서 찾을 수 있으며, 여기서 도시는 주민 수에 따라 다양한 기하학적 모양으로 구분됩니다. 등각선은 표면, 특히 지리적 지도 또는 그래프의 분포에서 수량의 동일한 값을 갖는 선입니다. 등각선은 다른 두 변수에 따라 연구량의 지속적인 변화를 반영하며 자연 및 사회 경제적 현상을 매핑하는 데 사용됩니다. 아이소라인은 연구된 양의 정량적 특성을 얻고 이들 사이의 상관관계를 분석하는 데 사용됩니다. 주제 4. 통계적 가치와 지표 4.1. 통계 지표 및 값의 목적 및 유형 통계지표의 성격과 내용은 이를 반영하는 경제·사회적 현상과 과정에 해당한다. 모든 경제 및 사회 범주 또는 개념은 본질적으로 추상적이며 가장 중요한 특징, 현상의 일반적인 상호 연결을 반영합니다. 그리고 현상이나 과정의 크기와 상관관계, 즉 적절한 양적 특성을 부여하기 위해 각 범주(개념)에 해당하는 경제·사회적 지표를 개발한다. 경제 및 사회 현상 및 과정의 양적 및 질적 특성의 통일성을 보장하는 것은 경제 범주의 본질에 대한 지표의 일치입니다. 사회의 경제 및 사회 발전 지표에는 계획(예측)과 보고(통계)의 두 가지 유형이 있습니다. 계획된 지표는 지표의 특정 특정 값이며, 그 달성은 미래 기간에 예측됩니다. 보고 지표 (통계)는 경제 및 사회 발전의 실제 조건을 특성화하며 특정 기간 동안 실제로 달성 된 수준입니다. 그것은 장소와 시간의 특정 조건 하에서 질적 확실성에서 사회 현상이나 과정의 객관적인 양적 특성 (측정)입니다. 각 통계 지표에는 질적 사회경제적 내용과 관련 측정 방법론이 있습니다. 통계 지표는 또한 하나 또는 다른 통계 형식(구조)을 가지며 다음을 표현할 수 있습니다. - 인구 단위의 총 수; - 이러한 단위의 양적 속성 값의 총합 - 부호의 평균값; - 다른 등의 값과 관련된 이 속성의 값 통계 지표에는 특정 정량적 가치도 있습니다. 특정 측정 단위로 표시되는 통계적 지표의 이 수치를 지표의 값이라고 합니다. 표시기의 값은 일반적으로 공간에 따라 변하고 시간에 따라 변동합니다. 따라서 통계 지표의 필수 속성은 영역과 순간 또는 기간의 표시이기도합니다. 통계 지표는 조건부로 XNUMX 차 (체적, 양적, 확장) 및 XNUMX 차 (파생, 정성, 집중)로 나눌 수 있습니다. 기본 지표는 총 인구 단위 수 또는 해당 속성 값의 합계를 나타냅니다. 역학, 시간 경과에 따른 변화를 고려하면 경제 전체 또는 특정 경우에 특정 기업의 광범위한 발전 경로를 특징으로 합니다. 통계 형식에 따르면 이러한 지표는 총 통계 값입니다. XNUMX 차 지표는 일반적으로 평균 및 상대 값으로 표현되며 역학에서 일반적으로 집중 개발 경로를 특성화합니다. 복잡한 사회경제적 현상과 과정의 규모를 특징짓는 지표를 흔히 합성(국내총생산(GDP), 국민소득, 사회적 노동 생산성, 소비자 바구니 등)이라고 합니다. 사용되는 측정 단위에 따라 표시기는 종류, 비용 및 노동력(인시, 표준 시간)으로 구분됩니다. 지역에 따라 응용 프로그램은 지역, 부문별 수준 등에서 계산된 지표를 구별합니다. 반영된 현상의 정확도에 따라 지표의 예상, 예비 및 최종 값이 구별됩니다. 통계 연구 대상의 양과 내용에 따라 개별(인구의 개별 단위를 특성화) 및 요약(일반화) 지표가 구별됩니다. 따라서 질량 또는 단위 집합을 특성화하는 통계 값을 일반화 통계 지표(값)라고 합니다. 요약 지표는 다음과 같은 특징으로 인해 통계 연구에서 매우 중요한 역할을 합니다. 연구 된 사회 현상의 단위 집합체에 대한 요약 (집중) 설명을 제공하십시오. 현상 사이에 존재하는 연결과 종속성을 표현하여 현상에 대한 상호 연결된 연구를 제공합니다. 현상에서 발생하는 변화, 발전의 새로운 패턴 등을 특성화합니다. 즉, 일반화 된 양 자체를 구성 요소, 요소로 분해하는 것을 기반으로 하여 고려 중인 현상에 대한 경제적 및 통계적 분석을 수행합니다. 등을 결정합니다. 복잡한 경제 및 사회 범주에 대한 객관적이고 신뢰할 수있는 연구는 통일성과 상호 연결로 국가의 다양한 측면과 측면과 이러한 범주의 발전 역학을 특성화하는 통계 지표 시스템을 기반으로 만 가능합니다. 경제 및 사회 현상과 과정의 통일성과 상호 관계를 객관적으로 반영하는 통계 지표는 단번에 확립된 억지스럽고 자의적으로 구성된 도그마가 아닙니다. 반대로 사회, 과학, 컴퓨터 기술의 역동적인 발전, 통계 방법론의 발전으로 인해 가치를 상실한 구식 지표가 변화하거나 사라지고 현재 상황을 객관적이고 안정적으로 반영하는 새롭고 더 발전된 지표가 등장한다는 사실 사회 발전의. 따라서 통계 지표의 구성 및 개선은 다음 두 가지 기본 원칙을 준수해야 합니다. - 객관성과 현실성(지표는 관련 경제 및 사회 범주(개념)의 본질을 진실하고 적절하게 반영해야 함) - 포괄적인 이론 및 방법론적 타당성(지표의 가치 결정, 역학에서의 측정 가능성 및 비교 가능성은 과학적으로 추론되고 명확하고 쉽게 공식화되고 균일한 해석으로 모호하지 않게 적용 가능해야 함). 또한 지표의 값은 해당 경제 또는 사회 현상(산업 및 지역 수준, 개별 기업 또는 직원 등)의 상태 또는 발전의 수준, 규모 및 질적 징후를 고려하여 올바르게 정량화되어야 합니다. ). 동시에 지표의 구성은 관련 지표를 요약할 수 있을 뿐만 아니라 그룹 및 집합체에서 질적 균질성을 보장할 수 있는 횡단적 성격이어야 합니다. 보다 복잡한 범주 또는 현상의 양과 구조를 특징짓습니다. 마지막으로, 통계 지표의 구성, 그 구조 및 본질은 연구 중인 현상이나 과정을 종합적으로 분석하고, 발전의 특징을 특성화하고, 그것에 영향을 미치는 요인을 결정할 가능성을 제공해야 합니다. 통계 값의 계산 및 연구 중인 현상에 대한 데이터 분석은 통계 연구의 세 번째이자 마지막 단계입니다. 통계에서는 절대값, 상대값 및 평균값과 같은 여러 유형의 통계량이 고려됩니다. 통계 지표의 일반화에는 시계열, 지수 등의 분석 지표도 포함됩니다. 4.2. 절대 통계 통계적 관찰은 범위와 목표에 관계없이 항상 절대 지표의 형태로 특정 사회 경제 현상 및 프로세스에 대한 정보, 즉 질적 확실성의 조건에서 사회 경제 현상 및 프로세스의 양적 특성인 지표를 제공합니다. 절대 지표의 질적 확실성은 그것이 연구되는 현상이나 과정의 특정 내용, 본질과 직접적으로 관련되어 있다는 사실에 있습니다. 이와 관련하여 절대 지표와 절대 값은 그 본질(내용)을 가장 완전하고 정확하게 반영하는 특정 측정 단위를 가져야 합니다. 절대 지표는 통계 현상의 징후를 정량적으로 표현한 것입니다. 예를 들어, 높이는 특징이고 그 값은 성장의 척도입니다. 절대 지표는 주어진 장소에서 연구되는 현상이나 과정의 크기를 특성화해야 하며 주어진 시간에 어떤 대상이나 영역에 "연결"되어야 하고 인구의 별도 단위(별도의 대상)를 특성화할 수 있습니다. - 통계 인구의 일부 또는 전체 통계 인구(예: 해당 국가의 인구 등)를 나타내는 기업, 근로자 또는 단위 그룹. 첫 번째 경우, 우리는 개인에 대해 이야기하고 있습니다. 절대 지표와 두 번째 - 요약 절대 지표에 대해. 개인은 인구의 개별 단위 크기를 특징 짓는 절대 값이라고합니다 (예 : 교대 근무당 한 작업자가 제조 한 부품 수, 별도 가족의 자녀 수). 통계적 관찰 과정에서 직접 획득되며 기본 회계 문서에 기록됩니다. 개별 지표는 특정 현상 및 프로세스를 통계적으로 관찰하는 과정에서 관심 있는 고정된 양적 특성의 평가, 계산, 측정의 결과로 획득됩니다. 요약 절대 값은 일반적으로 개별 개별 값을 합산하여 얻습니다. 요약 절대 지표는 개별 절대 지표의 값을 요약하고 그룹화한 결과로 얻어진다. 예를 들어, 인구 조사 과정에서 주 통계 기관은 해당 국가의 인구, 지역별, 성별, 연령별 분포에 대한 최종 절대 데이터를 받습니다. 절대 지표에는 통계적 관찰의 결과가 아니라 계산의 결과로 얻은 지표도 포함될 수 있습니다. 일반적으로 이러한 지표는 두 개의 절대 지표의 차이입니다. 예를 들어, 인구의 자연적 증가(감소)는 일정 기간 동안의 출생 수와 사망자 수의 차이로 발견됩니다. 연도의 생산량 증가는 연말 생산량과 연초 생산량의 차이로 나타납니다. 국가 경제 발전에 대한 장기 예측을 컴파일 할 때 재료, 노동 및 재정 자원에 대한 추정 데이터가 계산됩니다. 예에서 볼 수 있듯이 이러한 지표는 절대 측정 단위가 있으므로 절대적입니다. 절대 값은 현상의 자연적 기초를 반영합니다. 즉, 연구 인구의 단위 수, 개별 구성 요소 또는 물리적 특성(무게, 길이 등)에서 발생하는 자연 단위의 절대 크기를 나타냅니다. 또는 경제적 특성(비용, 인건비)에서 발생하는 단위 측정. 따라서 절대 값은 항상 특정 차원을 갖습니다. 또한 절대 통계 지표는 설명하는 프로세스 및 현상의 특성에 따라 항상 물리적, 비용 및 노동 측정 단위로 표현됩니다. 자연 미터는 자연적인 형태로 현상을 특성화하며 길이, 무게, 부피 등 또는 단위 수, 이벤트 수로 표현됩니다. 자연 단위에는 톤, 킬로그램, 미터 등과 같은 측정 단위가 포함됩니다. 어떤 경우에는 서로 다른 차원으로 표현된 두 수량의 곱인 결합된 측정 단위가 사용됩니다. 예를 들어, 발전량은 킬로와트시로, 화물 회전율은 톤-킬로미터 등으로 측정됩니다. 자연 측정 단위 그룹에는 소위 조건부 자연 측정 단위도 포함됩니다. 그들은 총 절대 값을 얻는 데 사용됩니다 개별 값이 소비자 속성이 유사하지만 예를 들어 지방 함량, 알코올, 칼로리 함량 등이 다른 특정 유형의 제품을 특성화하는 경우 순위. 이 경우 제품 유형 중 하나는 다음과 같습니다. 조건부 자연 미터로 간주하고 개별 품종의 소비자 속성(때로는 노동 집약도, 비용 등)의 비율을 나타내는 변환 계수를 사용하여 이 제품의 모든 품종이 제공됩니다. 노동 측정 단위는 노동 비용을 평가하고 노동 자원의 가용성, 분배 및 사용을 반영할 수 있는 지표를 특성화하는 데 사용됩니다(예: 노동 시간에 수행되는 노동 강도). 자연적, 때로는 노동 측정기는 이기종 제품의 관점에서 요약 절대 지표를 얻는 것을 허용하지 않습니다. 이와 관련하여 비용 측정 단위는 보편적이며 사회 경제적 현상에 대한 비용 (금전적) 평가를 제공하고 특정 제품의 비용 또는 수행 된 작업량을 특성화합니다. 예를 들어, 국민 소득, 국내 총생산과 같은 국가 경제에 대한 중요한 지표는 화폐 단위로 표시되며 기업 수준에서는 이익, 자체 및 차입 자금으로 표시됩니다. 원가 회계는 보편적이지만 항상 허용되는 것은 아니기 때문에 통계에서 가장 선호되는 것은 원가 단위입니다. 절대 지표는 시간과 공간에서 계산할 수 있습니다. 예를 들어, 1991년부터 2004년까지 러시아 연방 인구의 역학은 시간 요인에 의해 반영되고, 2004년 러시아 연방 지역별 베이커리 제품 가격 수준은 공간적 비교가 특징입니다. 시간 경과에 따른 절대 지표를 고려할 때(역학적으로), 등록은 특정 날짜, 즉 특정 시점(연초 기업의 고정 자산 가치) 및 모든 기간에 수행할 수 있습니다. 기간(연간 출생자 수) . 첫 번째 경우 표시기는 두 번째 간격으로 즉각적입니다. 공간적 확실성의 관점에서 절대 지표는 일반 영토, 지역 및 지역으로 나뉩니다. 예를 들어, GDP(국내 총생산)의 양은 일반적인 영토 지표이고, GRP(지역 총생산)의 양은 지역적 특성이며, 도시에 고용된 사람의 수는 지역적 특성, 즉 첫 번째 그룹의 지표는 국가 전체를 특성화하고 지역 지표는 특정 지역, 지역-별도의 도시, 마을 등을 특성화합니다. 절대 지표는 전체 인구에서 이 또는 저 부분이 차지하는 비율에 대한 질문에 답하지 않으며 계획된 목표의 수준, 계획의 이행 정도, 이 또는 저 현상의 강도를 특성화할 수 없습니다. 항상 비교에 적합하므로 상대 값 계산에만 자주 사용됩니다. 4.3. 상대 통계 절대값과 함께 통계에서 일반화 지표의 가장 중요한 형태 중 하나는 상대값입니다. 이는 특정 현상이나 통계 대상에 내재된 양적 비율의 척도를 나타내는 일반화 지표입니다. 상대값을 계산할 때 두 개의 상호 관련된 값(대부분 절대값)의 비율을 측정하는데, 이는 통계 분석에서 매우 중요합니다. 상대 값은 다양한 지표의 비교를 허용하고 이러한 비교를 명확하게 하기 때문에 통계 연구에서 널리 사용됩니다. 상대 값은 두 숫자의 비율로 계산됩니다. 이 때 분자를 비교값이라고 하고, 분모를 상대 비교의 밑이라고 합니다. 연구 중인 현상의 성격과 연구의 목적에 따라 기본 가치는 다른 가치를 가질 수 있으며, 이는 상대 가치의 다른 표현 형태로 이어집니다. 상대 수량은 다음과 같이 측정됩니다. - 계수에서: 비교 기준이 1로 간주되면 상대 값은 정수 또는 분수로 표현되어 한 값이 다른 값보다 몇 배나 더 큰지 또는 어느 부분인지 보여줍니다. - 비교 기준이 100인 경우 백분율로 표시 - ppm으로, 비교 기준이 1000인 경우; - 비교 기준이 10인 경우 데시밀 단위 - 명명된 숫자(km, kg, ha) 등 각각의 특정한 경우에, 하나 또는 다른 형태의 상대 가치의 선택은 연구의 목적과 사회 경제적 본질에 의해 결정되며, 그 측정은 원하는 상대 지표입니다. 내용에 따라 상대 값은 다음 유형으로 나뉩니다. - 계약 의무 이행 - 스피커; - 구조; - 조정; - 강함; - 비교. 계약상 의무의 상대 가치는 계약에 명시된 수준에 대한 계약의 실제 수행 비율입니다. 
이 값은 기업이 계약상 의무를 이행한 정도를 반영하며 숫자(정수 또는 소수) 또는 백분율로 표시할 수 있습니다. 동시에 초기 비율의 분자와 분모가 동일한 계약상 의무에 해당해야 합니다. 역학의 상대적 가치 - 성장률 -은 시간이 지남에 따라 사회 현상의 규모 변화를 특성화하는 지표입니다. 역학의 상대적 크기는 일정 기간 동안 동일한 유형의 현상 변화를 보여줍니다. 이 값은 다음 각 항목을 비교하여 계산됩니다. 원본 또는 이전 기간. 첫 번째 경우에는 역학의 기본 값을 얻고 두 번째 경우에는 역학의 사슬 값을 얻습니다. 그 값과 다른 값은 모두 계수 또는 백분율로 표시됩니다. 역학의 상대 값 및 기타 상대 지표를 계산할 때 비교 기준의 선택은 얻은 결과의 실제 가치가 크게 좌우되기 때문에 특별한주의를 기울여야합니다. 구조의 상대 값은 연구 인구의 구성 요소를 특징으로 합니다. 인구의 상대 가치는 다음 공식으로 계산됩니다. 
일반적으로 비중이라고 하는 구조의 상대 값은 전체의 특정 부분을 100%로 취한 전체로 나누어 계산됩니다. 이 값에는 한 가지 기능이 있습니다. 연구 인구의 상대 값의 합은 항상 100% 또는 1과 같습니다(표현 방법에 따라 다름). 구조의 상대 값은 전체 합계에서 각 그룹의 비중(몫)을 특성화하기 위해 여러 그룹 또는 부분에 속하는 복잡한 현상의 연구에 사용됩니다. 조정의 상대 값은 비교 기준으로 사용되는 인구의 개별 부분과 그 중 하나의 비율을 특성화합니다. 이 값을 결정할 때 전체의 일부 중 하나가 비교 기준으로 사용됩니다. 이 값을 사용하여 모집단 구성 요소 간의 비율을 관찰할 수 있습니다. 조정 지표는 예를 들어 농촌 100명당 도시 거주자 수입니다. 남성 100명당 여성 수 조정 상대 값의 분자와 분모는 동일한 측정 단위를 갖기 때문에 이러한 값은 명명된 숫자가 아니라 백분율, ppm 또는 다중 비율로 표시됩니다. 상대 강도 값은 모든 환경에서 주어진 현상의 유행을 결정하는 지표입니다. 그것들은 주어진 현상의 절대값과 그것이 발달하는 환경의 크기의 비율로 계산됩니다. 상대 강도 값은 통계 실습에서 널리 사용됩니다. 이 값의 예로는 인구 대 인구 비율, 자본 생산성, 의료 서비스 제공(인구 10명당 의사 수), 노동 생산성 수준(직원당 산출 또는 작업 시간 단위당) 등 . 따라서 강도의 상대적 가치는 다양한 종류의 자원 (물적, 재정, 노동) 사용의 효율성, 해당 국가 인구의 사회 문화적 생활 수준 및 기타 공공 생활 측면을 특징으로합니다. 상대강도값은 서로 일정한 관계에 있는 반대의 절대값을 비교하여 계산하며, 다른 유형의 상대값과 달리 일반적으로 이름을 숫자로 하고 그 절대값의 차원을 가지고 그 비율이 표현하다. 그럼에도 불구하고 어떤 경우에는 얻은 계산 결과가 너무 작을 때 명확성을 위해 1000 또는 10을 곱하여 ppm 및 데시밀 단위의 특성을 얻습니다. 특히 흥미로운 것은 XNUMX인당 국내 총생산(GDP)과 같은 다양한 상대적 강도 값입니다. 이 지표를 다양한 산업 또는 특정 유형의 제품에 적용하면 XNUMX인당 전기, 연료, 기계, 장비, 서비스, 상품 등의 생산과 같은 상대적 집약도 값을 얻을 수 있습니다. 상대 비교 값은 같은 기간 또는 한 시점에 다른 개체 또는 영역과 관련된 동명의 수준을 비교한 결과의 상대 지표입니다. 또한 계수 또는 백분율로 계산되며 비교 가능한 값이 다른 값보다 몇 배나 크거나 작은지를 보여줍니다. 상대 비교 값은 개별 기업, 도시, 지역, 국가의 다양한 성과 지표의 비교 평가에 널리 사용됩니다. 이 경우 예를 들어 특정 기업 등의 작업 결과를 비교 기준으로 삼고 다른 산업, 지역, 국가 등에서 유사한 기업의 결과와 일관되게 상관 관계를 맺습니다. 사회 현상의 통계 연구에서 절대 값과 상대 값은 서로를 보완합니다. 절대 값이 현상의 정역학을 특징 짓는다면 상대 값은 현상 발달의 정도, 역학 및 강도를 연구하는 것을 가능하게합니다. 경제 및 통계 분석에서 절대 및 상대 값을 올바르게 적용하고 사용하려면 다음이 필요합니다. - 하나 또는 다른 유형의 절대 및 상대 값을 선택하고 계산할 때 현상의 특성을 고려합니다(이러한 값으로 특징되는 현상의 양적 측면은 질적 측면과 불가분의 관계가 있기 때문에). - 비교 대상의 비교 가능성과 이들이 나타내는 현상의 양과 구성 측면에서 기본 절대값, 절대값 자체를 얻는 방법의 정확성 보장 - 분석 과정에서 상대값과 절대값을 복잡하게 사용하고 서로 분리하지 마십시오(절대값과 별도로 상대값만 사용하면 부정확하고 심지어 잘못된 결론을 초래할 수 있기 때문에). 주제 5. 변동의 평균 및 지표 5.1. 평균값 및 계산의 일반 원칙 평균 값은 다양한 속성의 많은 개별 값을 기반으로 구축되기 때문에 대중 사회 현상의 요약 (최종) 특성을 제공하는 일반화 통계 지표를 나타냅니다. 평균 값의 본질을 명확히하기 위해서는 평균 값이 계산되는 해당 현상의 표시 값 형성의 특징을 고려해야합니다. 각 질량 현상의 단위는 많은 특징을 가지고 있는 것으로 알려져 있습니다. 이 기호 중 어느 것을 취하든 개별 단위에 대한 값은 다르거나 변경되거나 통계에서 말했듯이 단위마다 다릅니다. 따라서 예를 들어 직원의 급여는 자격, 업무의 성격, 근속 기간 및 기타 여러 요인에 따라 결정되므로 매우 광범위합니다. 모든 요소의 누적 영향은 각 직원의 수입을 결정하지만 경제의 다른 부문에 있는 근로자의 평균 월 임금에 대해 이야기할 수 있습니다. 여기에서 우리는 많은 인구의 단위를 참조하는 변수 속성의 전형적인 특성 값으로 작업합니다. 평균 값은 연구 인구의 모든 단위의 특징인 일반을 반영합니다. 동시에, 마치 상호 상쇄되는 것처럼 인구의 개별 단위 속성의 크기에 작용하는 모든 요소의 영향을 균형있게 조정합니다. 모든 사회 현상의 수준(또는 크기)은 두 가지 요소 그룹의 작용에 의해 결정됩니다. 그들 중 일부는 일반적이고 주요하며 지속적으로 작동하며 연구되는 현상이나 과정의 특성과 밀접하게 관련되어 있으며 연구 대상 인구의 모든 단위에 대해 일반적인 형태이며 평균 값에 반영됩니다. 다른 사람들은 개별적이며 그들의 행동은 덜 뚜렷하고 일시적이고 무작위적입니다. 그들은 반대 방향으로 행동하고 인구의 개별 단위의 양적 특성 사이에 차이를 일으켜 연구되는 특성의 일정한 값을 변경하려고합니다. 개별 표지판의 작용은 평균값에서 소멸됩니다. 일반화 특성에서 균형을 이루고 상호 상쇄되는 전형적인 요인과 개별 요인의 결합된 영향에서 수학적 통계에서 알려진 대수의 기본법칙이 일반적인 형태로 나타납니다. 집계에서 기호의 개별 값은 공통 덩어리로 병합되고 그대로 용해됩니다. 따라서 평균 값은 양적으로 일치하지 않고 기능의 개별 값에서 벗어날 수 있는 "비인격적"으로 나타납니다. 평균 값은 개별 단위의 기호 사이의 무작위, 비정형적 차이의 상호 취소로 인해 전체 인구에 대한 일반적, 특성 및 전형적인 것을 반영합니다. 원인. 그러나 평균값이 특징의 가장 대표적인 값을 반영하기 위해서는 모든 모집단에 대해 결정되지 않고 질적으로 동질적인 단위로 구성된 모집단에 대해서만 결정되어야 합니다. 이 요구 사항은 과학적 기반의 평균 적용을 위한 주요 조건이며 사회 경제적 현상 분석에서 평균 방법과 그룹화 방법 사이의 긴밀한 연결을 의미합니다. 따라서 평균 값은 특정 장소와 시간 조건에서 동질 인구의 단위당 가변 형질의 전형적인 수준을 특징 짓는 일반적인 지표입니다. 따라서 평균 값의 본질을 정의할 때 모든 평균 값의 올바른 계산은 다음 요구 사항의 충족을 의미한다는 점을 강조해야 합니다. - 평균값이 계산되는 인구의 질적 동질성. 즉, 평균값 계산은 균질하고 동일한 유형의 현상을 선택하는 그룹화 방법을 기반으로 해야 합니다. - 무작위, 순전히 개별적인 원인 및 요인의 평균값 계산에 대한 영향 제외. 이것은 평균 계산이 큰 수의 법칙이 작용하고 모든 사고가 서로 상쇄되는 충분히 방대한 재료를 기반으로하는 경우에 달성됩니다. - 평균값을 계산할 때 계산의 목적과 지향해야 하는 소위 정의 지표(속성)를 설정하는 것이 중요합니다. 결정 지표는 평균 기능 값의 합, 역수의 합, 값의 곱 등으로 작용할 수 있습니다. 정의 지표와 평균 값 사이의 관계는 다음과 같이 표현됩니다. 모든 값 평균 기능의 평균 값은 평균 값으로 대체되며 이 경우 합 또는 곱은 정의 지표를 변경하지 않습니다. 결정 지표와 평균값의 이러한 연결을 기반으로 평균값의 직접 계산을 위한 초기 정량 비율이 구축됩니다. 통계적 모집단의 속성을 보존하는 평균의 능력을 정의 속성이라고 합니다. 모집단에 대해 전체적으로 계산된 평균값을 일반 평균이라고 합니다. 각 그룹에 대해 계산된 평균은 그룹 평균입니다. 일반 평균은 연구 중인 현상의 일반적인 특징을 반영하고, 그룹 평균은 이 그룹의 특정 조건에서 발생하는 현상에 대한 설명을 제공합니다. 계산 방법은 다를 수 있으므로 통계에서 여러 유형의 평균이 구별되며 그 중 주요 유형은 산술 평균, 조화 평균 및 기하 평균입니다. 경제 분석에서 평균의 사용은 과학 및 기술 진보, 사회적 측정 및 경제 발전을 위한 준비금 검색의 결과를 평가하는 주요 도구입니다. 동시에 평균에 지나치게 집중하면 경제 및 통계 분석을 수행할 때 편향된 결론을 초래할 수 있음을 기억해야 합니다. 이는 일반화 지표인 평균값이 실제로 존재하고 독립적인 관심을 가질 수 있는 인구의 개별 단위의 양적 특성 차이를 상쇄하고 무시한다는 사실 때문입니다. 5.2. 평균 유형 통계에서는 다양한 유형의 평균이 사용되며 두 가지 큰 클래스로 나뉩니다. - 전력 평균(고조파 평균, 기하 평균, 산술 평균, 제곱 평균, XNUMX차 평균); - 구조적 평균(모드, 중앙값). 거듭제곱 평균을 계산하려면 속성의 사용 가능한 모든 값을 사용해야 합니다. 모드와 중앙값은 분포의 구조에 의해서만 결정되므로 구조적 위치 평균이라고 합니다. 중앙값과 최빈값은 평균 지수 계산이 불가능하거나 비실용적인 모집단의 평균 특성으로 자주 사용됩니다. 평균의 가장 일반적인 유형은 산술 평균입니다. 산술 평균은 속성의 모든 값의 합계가 모집단의 모든 단위에 고르게 분포된 경우 모집단의 각 단위가 가질 속성의 값으로 이해됩니다. 이 값의 계산은 변수 속성의 모든 값의 합계와 결과 금액을 총 인구 단위 수로 나눈 값으로 축소됩니다. 예를 들어, 5명의 작업자가 부품 제조 주문을 완료한 반면 첫 번째는 7개의 부품을 생산했고 두 번째는 4, 세 번째는 10, 네 번째는 12, 다섯 번째는 XNUMX입니다. 각 옵션의 값은 한 번만 발생했기 때문에 초기 데이터에서 한 작업자의 평균 생산량을 결정하려면 간단한 산술 평균 공식을 적용해야 합니다. 
즉, 이 예에서 한 작업자의 평균 출력은 다음과 같습니다. 
단순 산술 평균과 함께 가중 산술 평균을 공부합니다. 예를 들어, 연령 범위가 20세에서 18세인 22명 그룹의 학생 평균 연령을 계산해 보겠습니다. 여기서 xi는 평균 특성의 변형이고 fi는 i번째 값이 다음에서 발생하는 횟수를 나타내는 빈도입니다. 인구(표 5.1). 표 5.1 학생들의 평균 연령 
가중 산술 평균 공식을 적용하면 다음을 얻습니다. 
가중 산술 평균을 선택하기위한 특정 규칙이 있습니다. 두 지표에 일련의 데이터가 있고 그 중 하나는 평균 값을 계산하고 동시에 숫자 값을 계산해야합니다. 논리식의 분모 uXNUMXb는 알려져 있고 분자의 값은 알려져 있지 않지만 이러한 지표의 곱으로 찾을 수 있으며 평균값은 가중 산술 평균 공식에 따라 계산되어야 합니다. 어떤 경우에는 초기 통계 데이터의 특성으로 인해 산술 평균 계산이 의미를 잃고 유일한 일반화 지표는 또 다른 유형의 평균 값인 조화 평균일 수 있습니다. 현재, 산술 평균의 계산 속성은 전자 컴퓨터의 광범위한 도입으로 인해 일반화 된 통계 지표 계산에서 관련성을 잃었습니다. 단순하고 가중된 평균 고조파 값은 실제적으로 매우 중요합니다. 논리 공식의 분자 숫자 값을 알고 있고 분모 값을 알 수 없지만 한 지표의 몫으로 다른 지표를 찾을 수 있는 경우 평균 값은 가중 조화에 의해 계산됩니다 공식을 의미합니다. 예를 들어 자동차가 처음 210km를 70km/h의 속도로 주행하고 나머지 150km를 75km/h의 속도로 주행했다고 가정합니다. 산술 평균 공식을 사용하여 360km의 전체 여행에서 자동차의 평균 속도를 결정하는 것은 불가능합니다. 옵션은 별도의 섹션 xj = 70km/h 및 X2 = 75km/h의 속도이고 가중치(fi)는 경로의 해당 세그먼트이므로 가중치에 의한 옵션의 곱은 물리적 의미도 경제적 의미도 없습니다. . 이 경우 경로의 세그먼트를 해당 속도(옵션 xi), 즉 경로의 개별 섹션을 통과하는 데 소요되는 시간(fi / xi)으로 나누는 것이 합리적입니다. 경로의 세그먼트를 fi로 표시하면 전체 경로를 Δfi로 표시하고 전체 경로에 소요된 시간을 Δ로 표시할 수 있습니다. fi/xi , 그러면 평균 속도는 전체 여행의 몫을 총 소요 시간으로 나눈 값으로 찾을 수 있습니다. 
이 예에서는 다음을 얻습니다. 
평균 조화 가중치를 사용할 때 모든 옵션(f)이 동일한 경우 가중치 대신 단순(가중되지 않은) 조화 평균을 사용할 수 있습니다. 
여기서 xi - 개별 옵션; n은 평균화된 기능의 변형 수입니다. 속도가 있는 예에서 다른 속도로 이동한 경로의 세그먼트가 동일한 경우 단순 조화 평균을 적용할 수 있습니다. 모든 평균값은 평균화된 기능의 각 변형을 대체할 때 평균화된 지표와 연결된 일부 최종 일반화 지표의 값이 변경되지 않도록 계산되어야 합니다. 따라서 경로의 개별 섹션에 대한 실제 속도를 평균 값(평균 속도)으로 바꿀 때 총 거리는 변경되지 않아야 합니다. 평균 값의 형식 (공식)은이 최종 지표와 평균 지표의 관계의 특성 (메커니즘)에 의해 결정되므로 옵션을 평균 값으로 대체 할 때 값이 변경되어서는 안되는 최종 지표, 정의 지표라고 합니다. 평균 공식을 도출하려면 평균 지표와 결정 지표의 관계를 사용하여 방정식을 작성하고 풀어야 합니다. 이 방정식은 평균 기능(지표)의 변형을 평균 값으로 대체하여 구성됩니다. 산술 평균과 조화 평균 외에도 다른 유형의 평균도 통계에 사용됩니다. 그들 모두는 힘 평균의 특별한 경우입니다. 동일한 데이터에 대한 모든 유형의 거듭제곱 법칙 평균을 계산하면 값 그들은 동일한 것으로 판명되었으며, 수단의 다수 법칙이 여기에 적용됩니다. 평균의 지수가 증가하면 평균 자체도 증가합니다. 다양한 유형의 전력 평균 값을 계산하기 위해 실제 연구에서 가장 일반적으로 사용되는 공식이 표에 나와 있습니다. 5.2. 표 5.2 동력 수단의 종류 
기하 평균은 n 개의 성장 요인이있을 때 사용되는 반면 속성의 개별 값은 일반적으로 이전 수준에 대한 비율로 체인 값의 형태로 구축 된 역학의 상대 값입니다. 다이내믹스 시리즈의 각 레벨. 따라서 평균은 평균 성장률을 나타냅니다. 기하학적 단순 평균은 다음 공식으로 계산됩니다. 
기하 가중 평균의 공식은 다음과 같습니다. 
위의 공식은 동일하지만 하나는 현재 계수 또는 성장률에 적용되고 두 번째는 계열 수준의 절대 값에 적용됩니다. 제곱 평균 제곱근은 제곱 함수의 값으로 계산할 때 사용되며 분포 계열에서 산술 평균을 중심으로 한 특성의 개별 값의 변동 정도를 측정하는 데 사용되며 공식으로 계산됩니다 
가중 평균 제곱근은 다른 공식을 사용하여 계산됩니다. 
평균 입방체는 입방체 함수의 값으로 계산할 때 사용되며 공식에 의해 계산됩니다 
가중 평균 입방체: 
위의 모든 평균 값은 일반 공식으로 나타낼 수 있습니다. 
평균 값은 어디에 있습니까? - 개별 가치; n은 연구된 모집단의 단위 수입니다. k - 평균 유형을 결정하는 지수. 동일한 초기 데이터를 사용할 때 일반 검정력 평균 공식에서 k가 많을수록 평균값이 커집니다. 이로부터 권력 수단의 가치 사이에는 규칙적인 관계가 있음을 알 수 있습니다. 
위에서 설명한 평균 값은 연구 대상 인구에 대한 일반화 된 아이디어를 제공하며 이러한 관점에서 이론적, 적용 및인지 적 중요성은 논쟁의 여지가 없습니다. 그러나 평균 값이 실제로 존재하는 옵션과 일치하지 않으므로 고려한 평균 외에도 통계 분석에서 우물을 차지하는 특정 옵션의 값을 사용하는 것이 좋습니다 - 정렬된(순위가 지정된) 일련의 속성 값에서 정의된 위치. 이러한 양 중에서 가장 일반적인 것은 구조적 또는 설명적 평균 - 모드(Mo) 및 중앙값(Me)입니다. 모드는 주어진 모집단에서 가장 자주 발생하는 기능의 값입니다. 변이 계열과 관련하여 모드는 순위 계열의 가장 자주 발생하는 값, 즉 가장 빈도가 높은 변이입니다. 패션은 가장 많이 방문한 매장, 모든 제품에 대한 가장 일반적인 가격을 결정하는 데 사용할 수 있습니다. 그것은 인구의 상당 부분의 특징 특성의 크기를 나타내며 공식에 의해 결정됩니다. 
여기서 x0은 간격의 하한입니다. h - 간격 값; fm - 간격 주파수; fm_1 - 이전 간격의 빈도. fm+1 - 다음 간격의 빈도. 중앙값은 순위가 매겨진 시리즈의 중앙에 있는 변형입니다. 중앙값은 양쪽에 동일한 수의 인구 단위가 있는 방식으로 계열을 두 개의 동일한 부분으로 나눕니다. 동시에 인구 단위의 절반에서 변수 속성의 값은 중앙값보다 작고 나머지 절반에서는 그 값보다 큽니다. 중앙값은 값이 분포 계열 요소의 절반보다 크거나 같거나 동시에 작거나 같은 요소를 검사할 때 사용됩니다. 중앙값은 기능 값이 집중된 위치, 즉 중심이 어디에 있는지에 대한 일반적인 아이디어를 제공합니다. 중앙값의 설명 적 특성은 인구 단위의 절반이 소유하는 다양한 속성 값의 양적 경계를 특성화한다는 사실에서 나타납니다. 이산 변이 계열의 중앙값을 찾는 문제는 간단하게 해결됩니다. 시리즈의 모든 단위에 일련 번호가 부여되면 중앙 변형의 일련 번호는 (n + 1) / 2로 정의되며 홀수 멤버 수 n이 있습니다. 시리즈 멤버 수가 짝수이면, 그러면 중앙값은 일련 번호가 n / 2 및 n / 2 + 1인 두 가지 변형의 평균 값이 됩니다. 구간 변동 계열에서 중위수를 결정할 때 그것이 위치한 구간(중위수 구간)을 먼저 결정합니다. 이 간격은 주파수의 누적 합계가 시리즈의 모든 주파수 합계의 절반과 같거나 초과한다는 사실이 특징입니다. 구간 변동 계열의 중앙값 계산은 다음 공식에 따라 수행됩니다. 
여기서 X0는 간격의 하한입니다. h - 간격 값; fm - 간격 주파수; f는 시리즈의 구성원 수입니다. ?m-1 - 이전 시리즈의 누적 멤버 합계. 중앙값과 함께 연구 인구 구조의보다 완전한 특성화를 위해 다른 옵션 값도 사용되며 이는 순위가 매겨진 시리즈에서 매우 확실한 위치를 차지합니다. 여기에는 사분위수와 십분위수가 포함됩니다. 사분위수는 주파수의 합으로 시리즈를 4개의 동일한 부분으로 나누고 십분위수는 10개의 동일한 부분으로 나눕니다. XNUMX사분위수와 XNUMX분위수가 있습니다. 산술 평균과 달리 중앙값과 모드는 변수 속성 값의 개인차를 상쇄하지 않으므로 통계 모집단의 추가적이고 매우 중요한 특성입니다. 실제로는 평균 대신 또는 함께 사용되는 경우가 많습니다. 연구 모집단에 변수 속성 값이 매우 크거나 매우 작은 특정 수의 단위가 포함된 경우 중앙값과 모드를 계산하는 것이 특히 편리합니다. 산술 평균의 값에 영향을 미치지 만 인구에별로 특징이없는 이러한 옵션 값은 중앙값 및 모드 값에 영향을 미치지 않으므로 후자는 경제 및 통계 분석에 매우 유용한 지표가됩니다 . 5.3. 변동 지표 통계 연구의 목적은 연구된 통계 모집단의 주요 특성과 패턴을 식별하는 것입니다. 통계적 관찰 데이터의 요약 처리 과정에서 분포 계열이 구축됩니다. 그룹화의 기초로 사용되는 속성이 정성적 또는 정량적인지 여부에 따라 두 가지 유형의 분포 시리즈가 있습니다. 정량적 기반으로 구축된 변동 분포 시리즈가 호출됩니다. 인구의 개별 단위에 대한 양적 특성의 값은 일정하지 않고 다소 다릅니다. 이러한 형질의 크기 차이를 변이(variation)라고 합니다. 연구된 모집단에서 발생하는 기능의 별도 숫자 값을 값 변형이라고 합니다. 인구의 개별 단위에 변이가 존재하는 것은 특성 수준의 형성에 대한 많은 요인의 영향 때문입니다. 인구의 개별 단위에서 징후의 특성과 변동 정도에 대한 연구는 모든 통계 연구에서 가장 중요한 문제입니다. 변이 지표는 특성 변이의 척도를 설명하는 데 사용됩니다. 통계 연구의 또 다른 중요한 임무는 인구의 특정 특징의 변화에서 개별 요인 또는 해당 그룹의 역할을 결정하는 것입니다. 통계에서 이러한 문제를 해결하기 위해 변동을 측정하는 지표 시스템을 사용하여 변동을 연구하는 특별한 방법이 사용됩니다. 실제로 연구원은 속성 값에 대해 충분히 많은 수의 옵션에 직면해 있는데, 이는 집계에서 속성 값에 따른 단위 분포에 대한 아이디어를 제공하지 않습니다. 이를 위해 속성 값의 모든 변형은 오름차순 또는 내림차순으로 정렬됩니다. 이 프로세스를 시리즈 순위라고 합니다. 순위가 매겨진 시리즈는 기능이 집계에서 취하는 값에 대한 일반적인 아이디어를 즉시 제공합니다. 인구의 철저한 특성화에 대한 평균 값의 부족으로 인해 연구 중인 특성의 변동(변이)을 측정하여 이러한 평균의 전형성을 평가할 수 있는 지표로 평균 값을 보완해야 합니다. 이러한 변동 지표를 사용하면 통계 분석을 보다 완전하고 의미 있게 만들 수 있으므로 연구된 사회 현상의 본질을 더 잘 이해할 수 있습니다. 가장 단순한 변동 신호는 최소값과 최대값입니다. 이것은 집계에서 기능의 가장 작은 값과 가장 큰 값입니다. 특성 값의 개별 변형 반복 횟수를 반복 빈도라고 합니다. 기호 fi 값의 반복 빈도를 나타내면 연구 인구의 부피와 동일한 빈도의 합은 다음과 같습니다. 
여기서 k는 속성 값 옵션의 수입니다. 주파수를 주파수로 바꾸는 것이 편리합니다. 빈도(빈도의 상대적 지표)는 단위 또는 백분율로 표시할 수 있으며 이를 통해 다양한 관측치의 변동 시리즈를 비교할 수 있습니다. 공식적으로 다음이 있습니다. 
특성의 변화를 측정하기 위해 다양한 절대 및 상대 지표가 사용됩니다. 변동의 절대 지표에는 평균 선형 편차, 변동 범위, 분산, 표준 편차가 포함됩니다. 변이 범위(R)는 연구된 모집단에서 특성의 최대값과 최소값 사이의 차이입니다. R = Xmax - Xmin. 이 지표는 변이의 제한 값 간의 차이만 보여주기 때문에 연구 중인 형질의 변동에 대한 가장 일반적인 아이디어만 제공합니다. 그것은 변이 계열의 빈도, 즉 분포의 특성과 완전히 관련이 없으며 그 의존성은 속성의 극단 값에서만 불안정하고 임의의 특성을 줄 수 있습니다. 변동 범위는 연구된 모집단의 특징에 대한 정보를 제공하지 않으며 얻은 평균 값의 전형성 정도를 평가할 수 없습니다. 이 지표의 범위는 상당히 균질한 모집단으로 제한되며, 보다 정확하게는 특성의 모든 값의 변동성을 고려한 지표인 특성의 변화를 특성화합니다. 특성의 변화를 특성화하려면 연구 대상 인구에 대한 일반적인 값에서 모든 값의 편차를 일반화해야합니다. 평균 선형 편차, 분산 및 표준 편차와 같은 변동 지표는 산술 평균에서 개별 모집단 단위 속성 값의 편차를 고려한 것입니다. 평균 선형 편차는 산술 평균에서 개별 옵션 편차의 절대 값의 산술 평균입니다. 
- 산술 평균에서 변형 편차의 절대 값(모듈러스) f- 주파수. 첫 번째 공식은 각 옵션이 집계에서 한 번만 발생하는 경우 적용되고 두 번째 공식은 동일하지 않은 빈도로 연속적으로 발생합니다. 산술 평균에서 옵션 편차를 평균화하는 또 다른 방법이 있습니다. 통계에서 매우 일반적인 이 방법은 평균값에서 옵션의 편차 제곱을 계산한 다음 평균화하는 것으로 축소됩니다. 이 경우 새로운 변동 지표인 분산을 얻습니다. 분산 (?2) - 특성 값 변이의 평균 값에서 편차의 제곱 평균: 
변형에 자체 가중치(또는 변형 시리즈의 빈도)가 있는 경우 두 번째 공식이 사용됩니다. 경제 및 통계 분석에서 표준 편차를 사용하여 가장 자주 속성의 변동을 평가하는 것이 관례입니다. 표준 편차(?)는 분산의 제곱근입니다. 
평균 선형 및 평균 제곱 편차는 연구 중인 모집단의 단위에 대해 속성 값이 평균적으로 얼마나 변동하는지 보여주며 변이와 동일한 단위로 표현됩니다. 통계 실습에서는 다양한 기능의 변동을 비교해야 하는 경우가 많습니다. 예를 들어, 직원의 연령과 자격, 근속 기간 및 임금 등의 변화를 비교하는 것은 매우 중요합니다. 이러한 비교를 위해 기호의 절대 변동성 지표(평균 선형 및 표준 편차)는 적합하지 않습니다. . 실제로 몇 년 단위로 표시되는 근무 경험의 변동과 루블 및 코펙으로 표시되는 임금 변동을 비교하는 것은 불가능합니다. 집계에서 다양한 특성의 변동성을 비교할 때 변동의 상대적 지표를 사용하는 것이 편리합니다. 이러한 지표는 산술 평균(또는 중앙값)에 대한 절대 지표의 비율로 계산됩니다. 변동의 절대 지표로 변동 범위, 평균 선형 편차, 표준 편차를 사용하여 변동의 상대 지표를 얻습니다.
- 인구의 동질성을 특징으로 하는 상대적 변동성의 가장 일반적으로 사용되는 지표. 변동 계수가 정규 분포에 가까운 분포에 대해 33%를 초과하지 않으면 집합이 균질한 것으로 간주됩니다. 주제 6. 표본 관찰 6.1. 선택적 관찰의 일반 개념 통계적 관찰은 연속 및 비연속으로 구성할 수 있습니다. 연속은 현상의 연구 인구의 모든 단위를 비연속적으로 검사하는 것을 포함합니다. 선택적 관찰은 또한 불연속적인 것에 속합니다. 선택적 관찰은 가장 널리 사용되는 비연속 관찰 유형 중 하나입니다. 이 관찰은 무작위 순서로 선택된 단위 중 일부가 연구자가 관심을 갖는 특성에 따라 연구된 현상의 전체 집합을 나타낼 수 있다는 아이디어에 기초합니다. 표본 관찰의 목적은 우선 연구 중인 전체 모집단의 요약 일반화 특성을 결정하기 위한 정보를 얻는 것입니다. 그 목적상 선택적 관찰은 연속적 관찰의 과제 중 하나와 일치하므로 연속적 또는 선택적 관찰의 두 가지 유형 중 어느 것이 수행하기에 더 적합한지에 대한 질문이 발생합니다. 이 문제를 해결할 때 다음과 같은 통계적 관찰을 위한 기본 요건부터 진행해야 합니다. - 정보는 신뢰할 수 있어야 합니다. 즉, 가능한 한 현실과 일치해야 합니다. - 정보는 연구 문제를 해결하기에 충분히 완전해야 합니다. - 정보 선택은 운영 목적으로 사용하기 위해 가능한 한 빨리 수행되어야 합니다. - 조직 및 수행을 위한 현금 및 인건비는 최소화되어야 합니다. 선택적 관찰을 통해 이러한 요구 사항은 연속 관찰보다 더 많이 충족됩니다. 연속 방법과 비교하여이 방법의 장점은 샘플링 방법 이론의 과학적 원칙, 즉 단위 선택의 무작위성과 충분한 수를 보장하는 과학적 원칙에 따라 조직되고 수행되는 경우 인식될 수 있습니다 . 이러한 원칙을 준수하면 연구자의 관심 특성에 따라 전체 연구 세트를 나타내는 단위 세트, 즉 대표(대표)를 얻을 수 있습니다. 선택적 관찰을 수행 할 때 연구 대상의 모든 단위가 검사되는 것은 아닙니다. 즉, 인구의 모든 단위가 아니라 특별히 선택된 일부만 검사됩니다. 무작위성을 보장하는 선택의 첫 번째 원칙은 연구 중인 모집단의 각 단위를 선택할 때 표본에 들어갈 동등한 기회가 제공된다는 사실에 있습니다. 무작위 선택은 무작위 선택이 아니라 특정 방법론에 따른 선택(예: 추첨에 의한 선택, 난수표 활용 등)입니다. 선택의 두 번째 원칙인 충분한 수의 선택된 단위를 확보하는 것은 표본의 대표성 개념과 밀접한 관련이 있습니다. 모든 선택적 관찰은 특정 목적과 명확하게 공식화 된 특정 작업으로 수행되므로 대표성 개념은 연구의 목적 및 목적과 정확히 관련됩니다. 전체 연구 모집단에서 선택된 부분은 무엇보다도 연구 중인 기능과 관련하여 대표성이 있어야 하거나 요약 일반화 특성의 형성에 중요한 영향을 미칩니다. 표본 관찰에서 "일반 모집단"의 개념이 사용됩니다. 연구자가 관심 있는 특성에 따라 연구할 단위의 연구 모집단과 일반 모집단에서 무작위로 선택된 일부인 "표본 모집단"입니다. 이 표본은 대표성 요구 사항이 적용됩니다. 즉, 일반 모집단의 일부만 연구할 때 결과를 전체 모집단에 적용할 수 있습니다. 일반 및 표본 모집단의 특성은 연구된 기능의 평균값, 분산 및 표준 편차, 모드 및 중앙값 등이 될 수 있습니다. 연구자들은 또한 일반 및 표본 모집단에서 연구 중인 특성에 따른 단위 분포에 관심이 있을 수 있습니다. 이 경우의 주파수를 각각 일반 주파수와 샘플 주파수라고 합니다. 연구중인 인구의 단위를 특성화하는 선택 규칙 및 방법 시스템은 샘플링 방법의 내용이며, 그 본질은 샘플을 관찰 할 때 기본 데이터를 얻은 다음 일반화, 분석 및 전체 인구에 대한 분포입니다. 연구 중인 현상에 대한 신뢰할 수 있는 정보를 얻기 위해. 표본의 대표성은 표본의 모집단에서 개체를 무작위로 선택하는 원칙을 준수함으로써 보장됩니다. 모집단이 질적으로 균질하다면 무작위성의 원칙은 샘플 개체를 무작위로 선택하여 구현됩니다. 단순 무작위 선택은 주어진 크기의 표본에 대해 모집단의 각 단위에 대해 관찰을 위해 선택될 동일한 확률을 제공하는 표본 추출 절차입니다. 따라서 표본 추출 방법의 목적은 이 모집단의 무작위 표본 정보를 기반으로 일반 모집단 특성의 의미에 대한 결론을 도출하는 것입니다. 6.2. 샘플링 오류 표본 모집단의 특성과 일반 모집단의 특성 사이에는 원칙적으로 약간의 불일치가 있으며 이를 통계적 관찰의 오류라고 합니다. 대량 관찰 시 오차는 불가피하지만 다양한 원인으로 인해 발생합니다. 발생할 수 있는 표본오차는 등록오류와 대표성오류로 인해 발생할 수 있습니다. 등록 오류 또는 기술 오류는 관찰자의 자격 부족, 부정확한 계산, 도구의 불완전성 등과 관련이 있습니다. 대표성(대표성)의 오류는 표본 특성과 일반 모집단의 예상 특성 사이의 불일치로 이해됩니다. 대표성 오류는 무작위이거나 체계적일 수 있습니다. 체계적인 오류는 설정된 선택 규칙 위반과 관련이 있습니다. 무작위 오류는 일반 모집단 단위의 다양한 범주에 대한 표본 모집단의 불충분한 표현으로 설명됩니다. 첫 번째 이유의 결과로 샘플은 편향된 것으로 쉽게 판명될 수 있습니다. 왜냐하면 각 단위를 선택할 때 항상 같은 방향으로 오류가 발생하기 때문입니다. 이 오류를 오프셋 오류라고 합니다. 크기가 임의 오류 값을 초과할 수 있습니다. 편향 오차의 특징은 대표성 오차의 일정 부분이므로 표본 크기에 따라 증가한다는 것입니다. 무작위 오차는 표본 크기가 증가함에 따라 감소합니다. 또한 임의 오차의 크기는 결정할 수 있지만 편향 오차의 크기는 실제로 결정하기가 매우 어렵고 때로는 불가능하므로 편향 오차의 원인을 알고 제거 조치를 제공하는 것이 중요합니다. 그것. 편향 오류는 의도적일 수도 있고 비의도적일 수도 있습니다. 의도적 오류의 이유는 일반 모집단에서 단위 선택에 대한 편향된 접근 방식 때문입니다. 이러한 오류가 발생하지 않도록 하려면 무작위 단위 선택의 원칙을 준수해야 합니다. 표본 관찰을 준비하고 표본 모집단을 구성하고 데이터를 분석하는 단계에서 의도하지 않은 오류가 발생할 수 있습니다. 이러한 오류를 방지하려면 좋은 샘플링 프레임, 즉 샘플링 단위 목록과 같이 샘플이 만들어지는 모집단이 필요합니다. 샘플링 프레임은 신뢰할 수 있고 완전하며 연구 목적과 일치해야 하며 샘플링 단위 및 특성은 샘플 관찰이 준비된 당시의 실제 상태와 일치해야 합니다. 표본의 일부 단위는 관찰 당시의 부재, 정보 제공의 거부 등으로 인해 정보 수집이 어려운 경우가 많습니다. 이러한 경우 이러한 단위를 다른 단위로 교체해야 합니다. 교체가 동등한 단위로 수행되는지 확인해야 합니다. 무작위 샘플링 오류는 표본의 단위와 일반 모집단의 단위 간의 무작위 차이의 결과로 발생합니다. 즉, 무작위 선택과 관련이 있습니다. 무작위 샘플링 오류의 출현에 대한 이론적 정당성은 확률 이론과 극한 정리입니다. 극한 정리의 본질은 질량 현상에서 규칙성 및 일반화 특성의 형성에 대한 다양한 무작위 원인의 누적 영향이 임의로 작은 값이거나 실제로 경우에 의존하지 않는다는 것입니다. 무작위 표본 오차는 표본 단위와 일반 모집단 간의 무작위 차이의 결과로 발생하므로 표본 크기가 충분히 크면 임의로 작습니다. 확률 이론의 극한 정리를 통해 무작위 샘플링 오류의 크기를 결정할 수 있습니다. 평균(표준)과 주변 샘플링 오류를 구별합니다. 평균 (표준) 샘플링 오류는 평균 샘플과 일반 모집단 (~ -) 사이의 불일치를 초과하지 않는 것으로 이해됩니다. ±. 한계 표본 오차는 가능한 최대 불일치(~ -), 즉 발생 확률에 대한 최대 오차로 간주됩니다. 표본추출법의 수학적 이론에서는 표본과 일반 모집단의 특성의 평균적인 특성을 비교하여 표본크기의 증가에 따라 큰 오차의 확률과 가능한 최대 오차의 한계를 증명한다. 감소하다. 더 많은 단위를 조사할수록 표본과 일반 특성 간의 불일치가 작아집니다. P.L.이 증명한 정리를 기반으로 합니다. Chebyshev, 충분히 큰 표본 크기(n)를 갖는 단순 무작위 표본의 표준 오차 값은 다음 공식으로 결정할 수 있습니다. 
표준오차이다. 단순 무작위 표본의 평균(표준) 오차에 대한 이 공식에서 값이 일반 모집단의 특성 변동성에 따라 달라지는 것을 알 수 있습니다(특성의 변동이 클수록 표본 오류가 커짐). 표본 크기 n에 대해(더 많은 단위를 조사할수록 표본과 일반적인 특성의 불일치 값이 작아짐). 학자 AM Lyapunov는 충분히 큰 크기의 무작위 샘플링 오류 확률이 정규 분포 법칙을 따른다는 것을 증명했습니다. 이 확률은 공식에 의해 결정됩니다. 
수학적 통계에서 신뢰 계수 t가 사용되며 함수 F(t)의 값은 다른 값에 대해 표로 작성되며 해당 신뢰 수준이 얻어집니다(표 6.1). 표 6.1 신뢰 요인 t 및 해당 신뢰 수준 
신뢰 계수를 사용하면 한계 샘플링 오류를 계산할 수 있습니다. 
즉, 한계 샘플링 오류는 평균 샘플링 오류의 수를 t 곱한 것과 같습니다. 따라서 한계표본오차값은 일정한 확률로 설정될 수 있다. Table의 마지막 열에서 알 수 있듯이. 6.1, 오차가 평균 샘플링 오차의 XNUMX배 이상일 확률, 즉
매우 작고 0,003(1-0,997)과 같습니다. 그러한 가능성이 희박한 사건은 실질적으로 불가능한 것으로 간주되므로 가치 
가능한 샘플링 오류의 한계로 간주할 수 있습니다. 표본 관찰을 통해 표본 모집단의 산술 평균과 이 평균의 한계 오차를 결정할 수 있습니다. 이 오차는 표본 값이 일반 평균과 얼마나 다를 수 있는지를 (특정 확률로) 보여줍니다. 그런 다음 일반 평균의 값은 하한이 다음과 같은 구간 추정으로 표시됩니다. 
추정된 모수의 미지의 값이 주어진 확률로 둘러싸이는 구간을 신뢰구간이라고 하고, 확률 P를 신뢰확률이라고 한다. 대부분의 경우 신뢰 확률은 0,95 또는 0,99와 같으며 신뢰 계수 t는 각각 1,96 및 2,58입니다. 이는 신뢰 구간에 주어진 확률의 일반 평균이 포함되어 있음을 의미합니다. 한계 표본 오차의 절대값과 함께 상대 표본 오차도 계산되며, 이는 표본 모집단의 해당 특성에 대한 한계 표본 오차의 백분율로 정의됩니다. 
한계 표본 오차 값이 클수록 신뢰 구간 값이 커지고 결과적으로 추정치의 정확도가 낮아집니다. 표본의 평균(표준) 오차는 표본 크기와 일반 모집단의 특성 변동 정도에 따라 다릅니다. 6.3. 필요한 샘플 크기의 결정 표본 추출 이론의 과학적 원칙 중 하나는 충분한 수의 단위가 선택되도록 하는 것입니다. 이론적으로이 원칙을 준수해야 할 필요성은 확률 이론의 극한 정리 증명에서 제시되며, 이를 통해 충분하고 표본의 대표성을 보장하기 위해 일반 모집단에서 얼마나 많은 단위를 선택해야 하는지를 설정할 수 있습니다. 표본의 표준 오차가 감소하고 결과적으로 추정치의 정확도가 증가하면 항상 표본 크기가 증가하므로 표본 관찰을 구성하는 단계에서 이미 다음을 결정할 필요가 있습니다 관찰 결과의 요구되는 정확도를 보장하기 위해 표본 크기는 얼마이어야 합니다. 필요한 표본 크기의 계산은 한계 표본 오차 공식에서 파생된 공식을 기반으로 합니다. (하지만), 하나 또는 다른 유형 및 선택 방법에 해당합니다. 따라서 무작위 반복 표본 크기(n)에 대해 다음을 얻습니다. 
이 공식의 핵심은 필요한 수를 무작위로 재선택하면 표본 크기가 신뢰 계수(t2)의 제곱과 변동 속성의 분산에 정비례한다는 것입니다. (?십팔) 한계 샘플링 오차의 제곱에 반비례합니다. (?2). 특히, 한계 오차를 두 배로 하여 필요한 표본 크기를 XNUMX배까지 줄일 수 있습니다. XNUMX개의 매개변수 중 XNUMX개(t 및 ?) 연구원이 설정합니다. 동시에 연구자는 목표를 바탕으로 샘플 설문조사의 목적은 다음과 같은 질문을 결정해야 합니다. 최상의 옵션을 제공하기 위해 이러한 매개변수를 포함하는 것이 더 나은 양적 조합은 무엇입니까? 한 경우에 그는 정확도 측정(?)보다 얻은 결과(t)의 신뢰성에 더 만족할 수 있으며 다른 경우도 마찬가지입니다. 표본 관찰을 설계하는 단계에서 연구자가 이 지표를 가지고 있지 않기 때문에 한계 표본 오차의 값에 대한 문제를 해결하는 것이 더 어렵습니다. 따라서 실제로는 한계 표본 오차를 다음과 같이 설정하는 것이 일반적입니다. 규칙, 특성의 예상 평균 수준의 10% 이내. 추정된 평균 수준을 설정하는 것은 유사한 이전 조사의 데이터를 사용하거나 샘플링 프레임의 데이터를 사용하고 작은 파일럿 샘플을 사용하는 등 다양한 방법으로 접근할 수 있습니다. 표본 관찰을 설계할 때 설정하기 가장 어려운 것은 공식 (5.2)의 세 번째 매개변수인 표본 모집단의 분산입니다. 이 경우 이전의 유사 및 예비 조사에서 얻은 조사자가 사용할 수 있는 모든 정보를 사용해야 합니다. 표본 조사가 표본 추출 단위의 여러 기능에 대한 연구를 포함하는 경우 필요한 표본 크기를 결정하는 문제가 더 복잡해집니다. 이 경우 일반적으로 각 특성의 평균 수준과 그 변이가 다르므로 목적과 목적만을 고려하여 특성 중 어느 분산을 선호할지 결정할 수 있습니다. 설문 조사. 표본 관찰을 설계할 때 특정 연구의 목적과 관찰 결과에 따른 결론의 확률에 따라 허용 가능한 표본 오차의 미리 결정된 값을 가정합니다. 일반적으로 표본 평균값의 한계 오차 공식을 통해 다음을 결정할 수 있습니다. - 표본 모집단의 지표에서 일반 모집단 지표의 가능한 편차의 크기; - 가능한 오류의 한계가 특정 지정된 값을 초과하지 않는 필수 정확도를 제공하는 필수 샘플 크기 - 표본의 오류가 주어진 한계를 가질 확률. 6.4. 선택 방법 및 샘플링 유형 표본추출법 이론에서는 대표성을 확보하기 위해 다양한 표본 추출 방법과 표본 추출 방식이 개발되어 왔다. 선택 방법에 따라 일반 인구에서 단위를 선택하는 절차가 이해됩니다. 반복 및 비반복의 두 가지 선택 방법이 있습니다. 재선택에서는 조사 후 무작위로 선택된 각 단위가 일반 모집단에 반환되며 후속 선택 시 다시 표본에 포함될 수 있습니다. 이 선택 방법은 "반환된 공" 방식에 따라 작성됩니다. 일반 모집단의 각 단위에 대한 표본에 들어갈 확률은 선택된 단위의 수에 관계없이 변경되지 않습니다. 비반복 선택의 경우 무작위로 선택된 각 단위는 검토 후 일반 인구에게 반환되지 않습니다. 이 선택 방법은 "돌려지지 않은 공" 방식에 따라 구성됩니다. 즉, 선택이 이루어지면 일반 모집단의 각 단위에 대한 표본에 들어갈 확률이 높아집니다. 샘플링 방법에 따라 다음과 같은 주요 샘플링 유형이 구별됩니다.
실제 무작위 표본은 무작위 선택의 과학적 원칙과 규칙에 따라 엄격하게 형성됩니다. 적절한 무작위 표본을 얻기 위해 일반 모집단을 표본 단위로 엄격하게 나눈 다음 충분한 수의 단위를 무작위 반복 또는 비반복 순서로 선택합니다. 무작위 순서는 추첨과 같습니다. 실제로는 특수 난수 테이블을 사용할 때 가장 자주 사용됩니다. 예를 들어, 1587 단위를 포함하는 모집단에서 40 단위를 선택해야 하는 경우 40보다 작은 1587개의 XNUMX자리 숫자가 표에서 선택됩니다. 실제 임의표본을 반복표본으로 구성한 경우에는 식 (6.1)에 따라 표준오차를 계산한다. 비반복적 샘플링 방법의 경우 표준 오차를 계산하는 공식은 다음과 같습니다. 
어디서? 1 - n / N - 표본에 포함되지 않은 일반 인구 단위의 비율. 이 비율은 항상 5.1보다 작기 때문에 비반복 선택의 오류(다른 조건이 동일한 경우)는 항상 반복 선택의 오류보다 작습니다. 비반복 선택은 반복 선택보다 구성하기 쉽고 훨씬 더 자주 사용됩니다. 그러나 비반복 표본 추출의 표준 오차 값은 더 간단한 공식(XNUMX)을 사용하여 결정할 수 있습니다. 표본에 포함되지 않은 일반 인구 단위의 비율이 커서 값이 XNUMX에 가까울 경우 이러한 대체가 가능합니다. 무작위 선택 규칙에 따라 표본을 형성하는 것은 실제로 매우 어렵고 때로는 불가능합니다. 난수 표를 사용할 때 일반 모집단의 모든 단위에 번호를 매겨야 하기 때문입니다. 종종 일반 인구가 너무 커서 그러한 예비 작업을 수행하는 것이 극히 어렵고 비효율적이므로 실제로는 각각 엄격하게 무작위가 아닌 다른 유형의 샘플이 사용됩니다. 그러나 무작위 선택 조건에 대한 최대 근사가 보장되는 방식으로 구성됩니다. 순전히 기계적인 샘플의 경우 전체 단위 모집단은 우선 연구 중인 특성과 관련하여 일부 중립적인 순서(예: 알파벳순)로 컴파일된 선택 단위 목록의 형태로 표시되어야 합니다. 그런 다음 샘플링 단위 목록은 단위를 선택하는 데 필요한 만큼 동일한 부분으로 나뉩니다. 또한, 연구 중인 형질의 변이와 관련이 없는 미리 정해진 규칙에 따라 목록의 각 부분에서 하나의 단위가 선택됩니다. 이러한 유형의 샘플링은 항상 무작위 선택을 제공하지 않을 수 있으며 결과 샘플이 편향될 수 있습니다. 이것은 첫째, 일반 인구 단위의 순서가 무작위가 아닌 요소를 가질 수 있다는 사실에 의해 설명됩니다. 둘째, 모집단의 각 부분에서 표본을 추출하는 경우 기원이 잘못 설정되면 편향 오류가 발생할 수도 있습니다. 그러나 적절한 무작위 표본보다 기계적 표본을 구성하는 것이 실질적으로 더 쉽고 이러한 유형의 표본추출은 표본 조사에서 가장 자주 사용됩니다. 기계적 샘플링에 대한 표준 오차는 실제 무작위 비반복 샘플링에 대한 공식(6.2)에 의해 결정됩니다. 일반적인(구역화, 계층화) 샘플링에는 두 가지 목표가 있습니다. - 연구원의 관심 특성에 따라 일반 인구의 해당하는 전형적인 그룹의 표본에서 대표성을 보장합니다. - 샘플링 결과의 정확도를 높입니다. 전형적인 샘플을 사용하면 형성이 시작되기 전에 일반 단위 인구가 전형적인 그룹으로 나뉩니다. 이 경우 매우 중요한 점은 그룹화 속성의 올바른 선택입니다. 선택된 일반 그룹에는 선택 단위가 같거나 다를 수 있습니다. 첫 번째 경우 샘플링 세트는 각 그룹에서 동일한 선택 점유율로 구성되며 두 번째 경우에는 일반 모집단에서 해당 몫에 비례하는 몫으로 구성됩니다. 표본이 동일한 선택 비율로 구성되면 본질적으로 각각이 전형적인 그룹인 더 작은 모집단에서 적절하게 무작위로 추출한 다수의 표본과 같습니다. 각 그룹에서 선택은 무작위(반복 또는 비반복) 또는 기계적 순서로 수행됩니다. 선택 점유율이 같거나 같지 않은 일반적인 표본을 사용하면 표본의 각 전형적인 그룹을 의무적으로 나타내므로 연구된 특성의 그룹 간 변동이 결과의 정확도에 미치는 영향을 제거할 수 있습니다. 세트. 표본의 표준 오차는 총 분산의 값에 의존하지 않습니다.2, 및 그룹 분산의 평균값 Δi2. 그룹 분산의 평균은 항상 총 분산보다 작기 때문에 다른 조건이 동일하면 일반적인 표본의 표준 오차는 무작위 표본 자체의 표준 오차보다 작습니다. 일반적인 샘플의 표준 오차를 결정할 때 다음 공식이 사용됩니다. - 반복 선발 방식으로 
- 비반복적 선택 방법: 
- 표본 모집단의 그룹 분산 평균. 연속(중첩) 표본은 조사할 단위가 아니지만 단위 그룹(계열, 중첩)이 무작위로 선택되는 경우의 표본 형성 유형입니다. 선택한 시리즈(중첩) 내에서 모든 단위가 검사됩니다. 직렬 샘플링은 개별 단위를 선택하는 것보다 구성하고 수행하는 것이 실질적으로 더 쉽습니다. 그러나 이러한 유형의 샘플링은 첫째, 각 계열의 표현을 보장하지 않으며 둘째, 조사 결과에 대한 연구 형질의 계열 간 변동의 영향을 제거하지 않습니다. 이 변동이 크면 무작위 대표성 오류가 증가합니다. 표본 유형을 선택할 때 연구자는 이러한 상황을 고려해야 합니다. 직렬 샘플링의 표준 오차는 다음 공식에 의해 결정됩니다. - 반복 선발 방식으로 - 
여기서 α는 표본의 계열간 분산입니다. r은 선택된 시리즈의 수입니다. - 반복되지 않는 선택 방식으로 - 
여기서 R은 일반 모집단의 계열 수입니다. 실제로 표본조사의 목적과 목적, 표본조사의 조직화 및 수행 가능성에 따라 특정 방법과 표본추출 유형이 사용된다. 대부분의 경우 샘플링 방법과 샘플링 유형의 조합이 사용됩니다. 이러한 샘플을 결합이라고 합니다. 기계 및 직렬 샘플링, 일반 및 기계, 직렬 및 실제로 무작위 등 다양한 조합으로 조합이 가능합니다. 조합 샘플링은 설문 조사를 구성하고 수행하는 데 드는 인건비와 금전적 비용을 최소화하면서 대표성을 최대화하는 데 사용됩니다. 결합 표본의 경우 표본의 표준 오차 값은 각 단계의 오차로 구성되며 해당 표본 오차의 제곱합의 제곱근으로 결정할 수 있습니다. 따라서 기계적 샘플링과 일반 샘플링이 결합된 샘플링과 함께 사용된 경우 표준 오차는 다음 공식으로 결정할 수 있습니다. 
여기서 Δ1 및 Δ2는 각각 기계적 및 일반 샘플의 표준 오차입니다. 다단계 샘플의 특징은 샘플이 선택 단계에 따라 점진적으로 형성된다는 것입니다. 첫 번째 단계에서 첫 번째 단계의 단위는 미리 결정된 방법과 선택 유형을 사용하여 선택됩니다. 두 번째 단계에서는 샘플에 포함된 첫 번째 단계의 각 단위에서 두 번째 단계의 단위를 선택하는 식으로 진행되며, 단계의 수는 XNUMX개 이상일 수 있습니다. 마지막 단계에서 샘플이 형성되며 그 단위는 조사 대상입니다. 예를 들어 가계예산 표본조사의 경우 첫 번째 단계에서는 국가의 영토 주체가 선택되고 두 번째 단계에서는 선택한 지역의 지구가 선택되고 세 번째 단계에서는 각 지자체에서 기업 또는 조직이 선택됩니다. , 그리고 마지막으로 네 번째 단계에서 선택된 기업에서 가족이 선택됩니다. . 따라서 샘플링 세트는 마지막 단계에서 형성됩니다. 다단계 샘플링은 다른 유형보다 유연하지만 일반적으로 동일한 크기의 단일 단계 샘플보다 덜 정확한 결과를 제공합니다. 그러나 동시에 다단계 선택의 샘플링 프레임은 샘플에 있는 단위에 대해서만 각 단계에서 구축되어야 하며 이는 매우 중요한 이점이 있습니다. 종종 기성품 샘플링 프레임이 없습니다. 다른 볼륨의 그룹을 사용한 다단계 선택에서 샘플링의 표준 오차는 다음 공식에 의해 결정됩니다. 
여기서 ?1, ?2, ?3, ... - 다른 단계의 표준 오류; n1, n2, n3... - 해당 선택 단계의 샘플 수. 그룹의 부피가 같지 않은 경우 이론적으로이 공식을 사용할 수 없습니다. 그러나 모든 단계에서 선택의 총 비율이 일정하다면 실제로 이 공식에 의한 계산은 오류의 왜곡으로 이어지지 않습니다. 다중 위상 샘플의 본질은 초기에 형성된 샘플을 기반으로 이 하위 샘플에서 하위 샘플이 형성된다는 것입니다. 다음 하위 샘플 등입니다. 초기 샘플은 첫 번째 단계이고 하위 샘플은 그것의 샘플은 두 번째 등입니다. 다음과 같은 경우 다상 샘플을 사용하는 것이 좋습니다.
다단계 샘플링의 확실한 장점 중 하나는 첫 번째 단계에서 얻은 정보를 후속 단계에서 추가 정보로 사용할 수 있고 두 번째 단계의 정보를 후속 단계에서 추가 정보로 사용할 수 있다는 점입니다. 정보의 사용은 표본 조사 결과의 정확도를 높입니다. . 다상 샘플링을 구성할 때 다양한 방법과 선택 유형의 조합을 사용할 수 있습니다(기계적 샘플링을 사용한 일반적인 샘플링 등). 다단계 선택은 다단계와 결합될 수 있습니다. 각 단계에서 샘플링은 다단계일 수 있습니다. 다상 샘플의 표준 오차는 샘플이 형성된 선택 방법 및 샘플 유형의 공식에 따라 각 단계에 대해 별도로 계산됩니다. 상호 침투 표본은 동일한 방법 및 유형으로 형성된 동일한 일반 모집단에서 두 개 이상의 독립적인 표본입니다. 짧은 시간에 샘플 조사의 예비 결과를 얻는 데 필요한 경우 상호 침투 샘플에 의존하는 것이 좋습니다. 조사 결과를 평가하는 데는 샘플을 상호 침투하는 것이 효과적입니다. 독립 표본에서 결과가 동일하면 표본 조사 데이터의 신뢰성을 나타냅니다. 상호 침투 샘플은 때때로 각 연구자가 다른 샘플 조사를 수행하도록 하여 다른 연구자의 작업을 테스트하는 데 사용할 수 있습니다. 샘플 상호 침투에 대한 표준 오차는 일반적인 비례 샘플링(5.3)과 동일한 공식으로 결정됩니다. 표본을 상호 침투시키는 것은 다른 유형보다 더 많은 노동력과 비용이 필요하므로 연구자는 표본 조사를 설계할 때 이를 고려해야 합니다. 다양한 선택 방법 및 샘플링 유형에 대한 한계 오차는 공식 ? = t?, 어디? 는 해당 표준 오차입니다. 주제 7. 인덱스 분석 7.1. 인덱스의 일반 개념 및 인덱스 방법 통계 실무에서 평균과 함께 지수는 가장 일반적인 통계 지표입니다. 그들의 도움으로 국가 경제 전체와 개별 부문의 발전이 특성화되고 가장 중요한 경제 지표 형성에 대한 개별 요인의 역할이 연구되며 지수는 경제 지표의 국제 비교에도 사용되어 결정 생활 수준, 경제 활동 모니터링 등 지수(라틴 지수)는 주어진 조건에서 연구된 현상의 수준이 다른 조건에서 같은 현상의 수준과 몇 배나 다른지를 나타내는 상대 값입니다. 조건의 차이는 시간(역학 지수), 공간(영토 지수) 및 비교 기준으로 일부 조건부 수준 선택에서 나타날 수 있습니다. 인구 요소 (대상, 단위 및 특성)의 적용 범위에 따라 개인 (초등) 및 요약 (복합) 지수가 구별되며 차례로 일반 및 그룹으로 나뉩니다. 개별 지수는 예를 들어 제품의 가격, 판매량 등을 비교하는 것과 같이 동일한 대상과 관련된 두 가지 지표를 비교한 결과입니다. 기업 및 산업 활동의 통계 및 경제 분석에서 개별 지수는 질적 및 양적 지표가 널리 사용됩니다. 에- 예를 들어, 가격 지수 ip = P1 / P0은 보고 기간 동안 각 제품 유형의 단가 수준의 상대적인 변화를 기본과 비교하여 특성화하며 질적 지표입니다. 물리적 볼륨 지수 iq = q1 / q2는 비교가 이루어진 기간과 관련하여 보고 기간 동안 이러한 유형의 제품 생산량이 몇 번이나 변경되었는지를 나타내는 정량적 지표입니다. 복합 지수는 인구의 여러 요소 수준의 비율을 특성화합니다(예: 천연 물질 형태가 다른 여러 유형의 제품 생산량의 변화 또는 노동 생산성 수준의 변화) 여러 유형의 제품 생산). 연구 중인 모집단이 여러 그룹으로 구성된 경우 개별 단위 그룹의 수준 변화를 특징짓는 각각의 복합 지수는 그룹(하위 지수)과 전체 단위 모집단을 포괄하는 복합 지수입니다. 는 일반(총) 인덱스입니다. 복합 지수는 복잡한 사회 경제적 현상의 비율을 나타내며 지수 값과 가중치라고 하는 상응하는 두 부분으로 구성됩니다. 인덱스를 특징 짓는 변경 사항을 인덱스라고합니다. 인덱싱된 지표는 두 가지 종류가 있습니다. 그들 중 일부는 특정 현상의 일반적인 총 크기 (부피)를 측정하고 조건부로 부피, 확장 (주어진 유형의 제품의 물리적 부피, 직원 수, 총 생산 노동 비용, 총 생산 비용 등)이라고합니다. ). 이 지표는 직접 계산 또는 합계의 결과로 얻어지며 초기, 기본입니다. 다른 지표는 인구의 하나 또는 다른 단위 측면에서 현상 또는 기능의 수준을 측정하며 조건부로 질적, 집약적이라고 합니다. 단위 시간당(또는 직원당) 출력, 단위 출력당 노동 시간, 단위 생산 비용 , 등. 이 지표는 체적 지표를 나누어 얻습니다. 즉, 계산된 XNUMX차 특성입니다. 그들은 현상이나 과정의 강도, 효율성을 측정하며 일반적으로 평균 또는 상대적 값입니다. 인덱스 방법을 사용할 때 특정 기호, 즉 규칙 체계가 적용됩니다. 색인된 각 지표는 특정 문자(일반적으로 라틴어)로 표시됩니다. 다음 표기법을 소개하겠습니다. Q - 물리적 측면에서 이러한 유형의 제조된 제품의 수량(볼륨)(또는 판매된 상품의 수량); T - 노동 시간 또는 노동일로 측정한 이러한 유형의 제품 생산을 위한 총 노동 시간(노무) 비용. 어떤 경우에는 동일한 문자가 직원의 평균 급여 수를 나타냅니다. z - 생산 단가; t는 생산 단위의 노동 집약도입니다. p는 생산 단위 또는 상품의 가격입니다. - 주어진 유형 및 양의 제품 생산을 위한 원자재, 재료 또는 연료의 총 소비. 기본 기간에 대한 표시기는 수식에 아래 첨자 "0"이 있고 비교(현재, 보고) 기간의 경우 기호 "1"이 있습니다. 개별 지수는 문자 i로 표시되며 아래 첨자도 함께 제공됩니다(색인된 지표의 지정). 따라서 iQ는 주어진 유형의 제조된 제품(또는 판매된 제품)의 수량(물리적 볼륨)의 개별 지수를 의미합니다. iz - 주어진 유형의 제품 등의 개별 단가 지수 복합 지수는 문자 I로 표시되며 변화를 특징짓는 지표의 첨자 지표도 함께 표시됩니다. 예를 들어, 생산 단위 등의 노동 집약도의 복합 지수입니다. 개별 지수는 일반적인 상대값, 즉 넓은 의미의 지수라고 할 수 있다. 좁은 의미의 지수 또는 고유 지수도 상대적인 지표이지만 특별한 종류입니다. 그들은 더 복잡한 구성 및 계산 방법을 가지고 있으며 구체적인 구성 방법은 지수 방법의 본질입니다. 사회 경제적 현상과 그것을 특징 짓는 지표는 비례 할 수 있습니다. 즉, 공통 척도를 가지며 비교할 수 없습니다. 따라서 다른 기업에서 생산되거나 다른 상점에서 판매되는 동일한 유형 및 다양성의 제품 또는 상품의 양은 상응하여 합산될 수 있지만, 다른 유형의 제품 또는 상품의 양은 측정할 수 없으며 직접 합산할 수 없습니다. 예를 들어 XNUMXkg의 빵에 XNUMX리터의 우유, XNUMX미터의 천, 신발 한 켤레를 추가하는 것은 불가능합니다. 복합 지수의 구성 및 계산에서 직접 합계의 공약 불가능성과 불가능성은 자연 측정 단위의 차이가 아니라 소비자 속성의 차이, 이러한 제품 또는 상품의 불평등한 천연 물질 형태에 의해 설명됩니다. . 이와 관련하여 종합지수를 계산하기 위해서는 구성요소를 비교 가능한 형태로 가져와야 합니다. 다른 유형의 제품이나 다른 상품의 통일성은 노동의 산물이며 특정 가치와 금전적 표현 - 가격 (p)을 가지고 있다는 사실에 있습니다. 또한 각 제품에는 특정 비용(z)과 노동 집약도(t)가 있습니다. 이러한 질적 지표는 이기종 제품의 비교 계수인 일반적인 측정으로 사용할 수 있습니다. 각 유형의 생산량(Q)에 생산 단위의 해당 가격, 비용 또는 노동 집약도를 곱하면 다양한 제품을 동일한 단위로 줄이고 비교 가능한 지표를 얻을 수 있습니다. 질적 지표의 복합 지수를 구성할 때도 상황은 비슷합니다. 예를 들어 판매된 다양한 상품의 일반적인 가격 수준의 변화에 관심이 있다고 가정합니다. 서로 다른 상품의 가격은 공식적으로는 측정할 수 있지만 판매된 각 상품의 수량을 고려하지 않고 직접 합계하면 독립적인 실제 의미가 없는 가치가 나타납니다. 따라서 종합 물가 지수는 단순 합계의 비율로 구성될 수 없습니다. ip = ?p1/?p2. 개별 상품의 가격은 판매된 특정 상품 수와 상품 유통 과정에서 상품의 통계적 무게 및 역할을 고려하지 않습니다. 개별 상품의 단순 가격 합계는 복합 지수를 구성하는 데 적합하지 않습니다. 가격은 상품 측정 단위에 따라 달라지며, 이를 변경하면 다른 금액과 다른 지수 값이 제공되기 때문입니다. 결과적으로 질적 지표의 복합 지표를 구성할 때 이러한 질적 지표가 계산되는 단위당 관련 체적 지표와 분리하여 고려할 수 없습니다. 하나 또는 다른 질적 지표(p, z, t)에 직접 관련된 볼륨 지표(Q)를 곱해야만 특정 경제에서 각 유형의 제품(또는 제품)의 역할과 통계적 가중치를 고려할 수 있습니다. 프로세스 - 총 가치 (pQ), 총 비용 (zQ), 총 작업 시간 (tQ) 등의 형성 과정. 동시에 합계가 실제적으로 중요한 지표를 얻습니다. 따라서 인덱스 방법과 인덱스 자체의 첫 번째 특징은 인덱스된 지표가 단독으로 고려되지 않고 다른 지표와 함께 고려된다는 것입니다. 색인 된 지표에 관련 지표를 곱하여 다양한 현상을 통일성으로 줄이고 양적 비교 가능성을 보장하며 실제 경제 과정에서 가중치를 고려합니다. 따라서 인덱스된 지표와 관련된 승수 지표는 일반적으로 지표의 가중치라고 하며, 이들에 의한 곱셈을 가중치라고 합니다. 그러나 색인된 지표의 값에 연관된 다른 지표(가중치)의 값을 곱해도 지표 자체의 문제는 아직 해결되지 않습니다. 예를 들어 가격에 그에 해당하는 상품 수량을 곱하면 각 기간에 이러한 상품의 가치를 찾을 수 있으며 그에 따라 균형 및 가중치 문제를 해결할 수 있습니다. 그러나 결과 합계를 비교하면 (?p1Q1 및 ?p0Q0)은 상품의 가격과 수량(볼륨)의 두 가지 요소에 따라 달라지는 무역 회전율의 변화를 특성화하는 지표를 제공하지만 가격 수준과 상품 생산 수준의 변화를 특징짓지는 않습니다. 
지수가 한 요인의 변화를 특성화하려면 공식 (7.1)에서 다른 요인의 변화를 제거하고 분자와 분모 모두에서 같은 기간 수준으로 고정해야합니다. 예를 들어, 비교된 두 기간의 이종 제품의 볼륨을 추정하려면 두 기간에 판매된 제품을 동일한 기본 가격(예: 기본 가격(p0))으로 평가해야 합니다. 결과 지표는 물리적 생산량 Q의 한 가지 요인의 변화만을 반영합니다. 
그리고 상품 그룹에 대한 가격 수준의 변화를 평가하려면 이러한 상품의 동일한 양을 비교할 필요가 있습니다. 즉, 상품 수(Q)는 지수의 분자와 분모 모두에서 고정되어야 합니다. 동일한 수준에서(기본 또는 보고 수준에서). 따라서 구성된 종합 가격 지수는 고정으로 인해 가중치(Q)의 변화가 제거(제거)되기 때문에 가격 변화, 즉 지수 지표만 특징짓습니다. Ip =?p1q1/?p0q1; IP=?p1q0/?p0q0. 두 경우 모두(Iq 및 Ip) 지수는 한 가지 요인의 변화만을 반영했습니다. 즉, 동일한 수준에 다른 요인(가중치)이 고정되어 있는 지수 지표입니다. 가중치를 같은 수준에서 지수의 분자와 분모에 고정시켜 가중치 변화의 영향을 제거하는 것은 지수의 두 번째 특징이자 지수 방식이다. 실제 지수 구성에서 발생하는 문제를 고려하여 이질적인 요소(다양한 유형의 제품 등)로 구성된 복잡한 현상의 수준을 비교 기술하는 것이 과제였습니다. 따라서 Ip는 가격 수준이 일반적으로 어떻게 변했는지, 즉 다양한 상품의 가격 역학을 하나의 일반화 지표 형태로 측정해야합니다. 역사적으로 지수 자체는 하나의 일반화 지표인 복합 지수에서 복잡한 현상의 개별 요소의 역학을 일반화하고 종합하는 작업인 이 특정 경제 과제를 해결한 결과로 나타났습니다. 그러나 지수 자체는 개별 지표의 변화가 이러한 요인의 기능을 나타내는 지표의 변화에 미치는 영향을 분석하는 또 다른 문제를 해결하는 데 사용됩니다. 따라서 판매된 총 상품 비용(회전율 - ?pq)은 가격(p)과 수량(볼륨 - Q)의 함수이므로 이러한 각 요인이 가격 변동에 미치는 영향을 측정하는 작업을 설정할 수 있습니다. 회전율, 즉 각 요인을 변경하여 개별적으로 어떻게 변경되었는지 확인합니다. 이러한 분석 문제를 해결하는 데 사용되는 지수도 지수 방법의 특정 기능(가중치 및 가중치 변경 제거)을 사용하여 구축됩니다. 따라서 지수 자체는 사회 경제적 현상의 수준이 다른 (또는 다른) 현상과 관련하여 고려되는 특수한 종류의 상대적 지표이며, 이 경우 그 변화는 제거됩니다. 지수화된 지표와 관련된 지표는 지수 가중치로 사용되며 가중치 변경의 제거(동일한 수준에서 지수의 분자와 분모에 고정)는 지수 자체와 지수 방식의 세부사항입니다. 7.2. 질적 지표의 종합 지표 각 정성 지표는 계산되는 측정 단위(또는 참조하는 측정 단위)에 따라 하나 또는 다른 볼륨 지표와 연결됩니다. 따라서 상품의 단가는 수량(Q)과 관련이 있습니다. 가격(p), 비용(z) 및 생산 단위의 노동 집약도(t = T / Q)와 같은 품질 지표와 원자재 및 자재의 특정 소비(m = M / Q)는 다음과 연관됩니다. 제조된 제품의 양. 품질 지표의 종합 지수는 임의의 상품 또는 제품 세트와 관련하여 일반적으로 변화를 특성화해서는 안되며, 완전히 특정 양의 생산 또는 판매된 상품의 가격, 주요 비용, 노동 집약도 또는 단위 비용의 변화를 특성화해야 합니다. 이것은 가중치를 부여함으로써(색인된 질적 지표의 수준에 관련된 볼륨 지표(가중치) 값을 곱하고 같은 수준에서 지수의 분자와 분모의 가중치를 고정함으로써 달성됩니다. 이러한 제품의 합계를 비교하면 집계 지수가 제공됩니다. 유사하게, 원재료 또는 재료의 특정 소비 지수뿐만 아니라 생산 단위의 비용 및 노동 집약도의 역학에 대한 총계 지수를 구성할 수 있습니다. 이러한 복합 지수를 구성할 때의 주요 문제는 지수의 가중치, 즉 이 경우 생산량(또는 상품) - Q를 고정하는 데 필요한 수준을 경제적으로 정당하게 선택하는 것입니다. 일반적으로 질적 지표의 역학의 복합 지수 전에 과제는 수준의 상대적 변화뿐만 아니라이 변화의 결과로 현재 기간에 얻은 경제적 효과의 절대 가치를 측정하는 것입니다. : 가격인하로 인한 구매자의 절감액(가격이 인상된 경우 추가비용액), 비용변동에 따른 절감액(또는 추가비용) 등 이 문제의 공식화는 현재 기간의 가중치를 가진 질적 지표의 역학 지수로 이어집니다. - 첫째, 연구원은 과거가 아닌 현재 생산되는 제품의 비용 또는 노동 집약도를 변경하는 데 관심이 있습니다. - 둘째, 경제적 효과는 이전(기준) 기간이 아닌 현재 보고의 실제 결과와 연결되어야 합니다. 총 비용 지수를 예로 들어 보겠습니다. 
따라서 이 지수에서 분자는 보고 기간의 제품에 대한 실제 비용의 합계이며 분모는 각 유형의 단위 비용이 다음과 같은 경우 보고 기간에 제품에 지출할 금액을 나타내는 조건부 값입니다. 제품은 기본 수준을 유지했습니다. 생산 단가를 변경하여 얻은 실질 경제 효과는 절대값으로 표시되며 지수의 분자와 분모 금액의 차이로 계산됩니다. (?z1Q1 ??z0Q1) 또는 (?z1?z0) 질문1). 따라서보고 (현재) 기간의 가중치에 의한 가중치는 지수 지표를 변경하여 얻은 경제적 효과 지표와 질적 지표의 지표를 연결합니다. 따라서 집계 인덱스! 질적 지표의 역학은 일반적으로 보고 기간의 가중치로 구축 및 계산됩니다. 
공식 (7.2)는 종합 물가 지수이고, 공식 (7.3)은 재료 소비의 종합 지수의 계산입니다. 이 지수에서 분자와 분모의 차이는 첫 번째 경우 차이의 부호에 따라 동일한 상품 세트를 구입하는 비용의 감소 또는 증가를 나타냅니다. 두 번째 경우 - 동일한 양의 제품 생산을 위한 재료 소비의 증가 또는 감소. 7.3. 볼륨 지표의 집계 지수 체적 지표는 상응할 수 있고(T, pQ, zQ) 비교할 수 없을 수도 있습니다(다양한 유형의 제품 또는 상품의 양 - Q). 비교 가능한 거래량 지표는 직접 요약 할 수 있으며 집계 지표의 구성은 어려움을 일으키지 않습니다. 일반적인 결과를 얻고 이질적인 거래량 지표의 종합 지표를 구축하려면 먼저 이 지표의 개별 값을 측정해야 합니다. 현상의 경제적 본질을 바탕으로 공통 척도를 찾아 비교계수로 활용하는 것이 필요하다. 볼륨 지표에 대한 이러한 일반적인 측정은 관련 정성 지표입니다. 따라서 다양한 유형의 제품의 볼륨은 이러한 제품의 가격(p), 비용(z) 및 노동 집약도(t)를 사용하여 측정할 수 있습니다. 색인된 거래량 지표에 하나 또는 다른 질적 지표를 곱하면 합계 가능성이 있을 뿐만 아니라 실제 경제 과정에서 제품과 같은 각 요소의 역할, 즉 통계적 이 과정에서 무게도 고려됩니다. 다양한 질적 지표가 거래량 지수에서 가중치로 작용할 수 있으므로 어느 것을 사용해야 하는지에 대한 질문이 발생합니다. 각각의 특정한 경우에 이 문제는 지수 앞에 놓인 인지적 경제 과제에 따라 해결되어야 합니다. 즉, 특정 가중치-보정자의 선택은 경제적으로 정당화되어야 합니다. 경제 및 통계 작업의 실행에서 가격은 일반적으로 총 산출 지수에 대한 가중치로 사용됩니다. 이것은 산업 및 농산물 거래량의 지표뿐만 아니라 물리적 거래량의 지표가 구축되는 방식입니다. 많은 경우 생산량의 변화는 그 자체가 아니라 더 복잡한 주문의 지표인 총 생산 비용, 총 비용의 변화에 미치는 영향의 관점에서 볼 때 관심 대상입니다. , 총 작업 시간 비용, 주어진 섹션의 총 생산량 등 이러한 경우 가중치 구성 요소의 선택은보다 복잡한 지표가 의존하는 지표 요인의 관계에 의해 결정됩니다. 지수가 지수 거래량 지표의 변화만을 반영하기 위해 분자와 분모의 가중치는 같은 기간의 수준으로 고정됩니다. 볼륨 지표의 역학 지수에서 경제 작업을 수행할 때 가중치는 일반적으로 기본 기간 수준에서 고정됩니다(공식 7.2 참조). 이를 통해 상호 연결된 인덱스 시스템을 구축할 수 있습니다. 개별 수량 지표(판매량, 생산성 수량, 파종 면적)의 경우 기준 기간 수준에서 가중치가 선택됩니다. 예를 들어: 
여기서 In은 종합 수익률 지수입니다. I - 무역 가치의 복합 지수; Iq - 복합 비용 지수. 비교 가능한 범위의 단위(비교 가능한 제품)에 대해 계산되는 질적 지수와 달리 종합 거래량 지수는 완전성과 정확성을 위해 각 기간에 생산(또는 판매)된 전체 단위 범위를 포함해야 합니다. 이와 관련하여 비교 기간 중 하나에 생산되지 않은 제품 유형에 대해 어떤 가중치를 적용해야 하는지에 대한 질문이 발생합니다. 이러한 경우 통계 실습에서는 두 가지 방법이 사용됩니다. 산업 생산량의 지표를 계산할 때 기준 기간의 가격이없는 새로운 유형의 산업 생산량은 현재 기간의 가격으로 조건부로 추정됩니다. 판매량 지수를 계산할 때 새로운 상품의 가격이 유사 상품의 비교 범위의 가격과 동일한 정도로 변경되었다는 조건부 가정에 기반한 방법을 사용합니다. 7.4. 상수 및 가변 가중치가 있는 일련의 집계 인덱스 경제 현상의 역학을 연구할 때 여러 연속 기간에 대해 지수를 만들고 계산합니다. 그들은 일련의 기본 또는 연쇄 지수를 형성합니다. 일련의 기본 지수에서는 각 지수의 지수 지표를 같은 기간의 수준과 비교하고, 일련의 연쇄 지수에서는 지수 지표를 이전 기간의 수준과 비교한다. 각 개별 지수에서 분자와 분모의 가중치는 반드시 동일한 수준으로 고정됩니다. 일련의 인덱스가 구축되는 경우 해당 가중치는 시리즈의 모든 인덱스에 대해 일정하거나 가변적일 수 있습니다. 생산량 ?q1p0/?q0p0,?q2p0/?q0p0,?q3p0/?q0p0 등의 많은 기본 지표는 일정한 가중치(р0)를 갖는다. 많은 체인 인덱스도 일정한 가중치(p0)를 갖습니다. ?q1p0/?q0p0,?q2p0/?q1p0,?q3p0/?q2p0 등. 다수의 체인 가격 지수 ?p1q1/?p1q0,?p2q2/?p2q0, ?p3q3 /?p3q2 등은 가변 가중치로 구축됩니다(첫 번째 인덱스에서 - 1nd에서 q1 - q2 등). 가중치가 일정한 역학 지수의 경우 체인과 기본 성장률(지수) 간의 관계가 유효합니다. 
따라서 수년에 걸쳐 일정한 가중치를 사용하면 체인 인덱스에서 기본 인덱스로 또는 그 반대로 이동할 수 있습니다. 따라서 생산량과 판매량에 대한 일련의 지수는 일정한 가중치를 사용하여 통계적 관행으로 구성됩니다. 예를 들어 거래량 지수에서 기준 연도의 1월 XNUMX일에 설정된 수준으로 고정된 가격이 고정 가중치로 사용됩니다. 수년 동안 사용되는 이러한 가격을 비교 가능(고정)이라고 합니다. 생산량(상품) 지수에 비교 가능한 가격을 사용하면 간단한 요약으로 몇 년 동안 결과를 얻을 수 있습니다. 비교 가능한 가격은 현재(현재) 가격과 크게 다르지 않아야 하므로 주기적으로 검토되어 새로운 비교 가능한 가격으로 이동합니다. 서로 다른 비교 가능한 가격이 적용된 장기간의 생산량 지수를 계산할 수 있도록 XNUMX년 생산은 이전 고정 가격과 새로운 고정 가격 모두에서 평가됩니다. 장기간의 지수는 체인 방법, 즉 이 기간의 개별 세그먼트에 대한 지수를 곱하여 계산됩니다. 현재 기간의 가중치에 따라 경제적으로 올바른 일련의 질적 지표 지표는 가변 가중치로 구성됩니다. 7.5. 통합 영토 지수 구축 영역 지수를 구성할 때, 즉 공간에서 지표를 비교할 때(지구간, 다른 기업 간의 비교 등), 지수 가중치가 적용되어야 하는 수준에서 비교 기준 및 지역(대상)의 선택에 대한 질문이 발생합니다. 고정되다. 각각의 특정 경우에 이러한 문제는 연구의 목적에 따라 해결되어야 합니다. 비교 기준의 선택은 특히 비교가 쌍방향(예: 인접한 두 영토 단위의 지표 비교)인지 또는 다자간(여러 영토, 개체의 지표 비교)인지에 따라 다릅니다. 양면 비교에서 동일한 기준을 가진 각 영역 또는 대상은 비교 및 비교 기준으로 간주될 수 있습니다. 이와 관련하여 종합지수의 가중치를 특정 영역(객체) 수준으로 고정하는 문제가 발생한다. 예를 들어, 두 영역 중 어느 영역에서 생산 단가가 몇 퍼센트나 더 낮고 생산량이 더 많은지를 결정해야 한다고 가정합니다. 영역 A와 영역 B를 비교하면 상당히 합리적이고 간단한 방법은 비용 지수에서 두 영역(Q = QA + QB)에 대한 일반적으로 생산량을 가중치로 고정하는 것입니다. 그러면 다음을 얻습니다. Iz =?zQ/? zQ . 예를 들어 다자간 비교의 경우 여러 영역에서 질적 지표를 비교할 때 가중치가 그에 따라 고정되는 수준에서 영역의 경계를 확장해야 합니다. 볼륨 지표의 통합 영역 지수에서 비교 영역에 대해 전체적으로 계산 된 해당 질적 지표의 평균 수준을 가중치로 취할 수 있습니다. 따라서 우리의 예에서 
7.6. 평균 지수 개별 지수와 복합 지수를 계산하는 방법에 따라 산술 평균과 평균 조화 지수가 있습니다. 즉, 개별 지수를 기반으로 구축된 전체 지수는 산술 평균 또는 조화 지수의 형태를 취하는데, 산술 평균과 평균 조화 지수로 변환될 수 있다. 복합 지수를 개별(그룹) 지수의 평균으로 구성한다는 아이디어는 충분히 이해할 수 있습니다. 결국 복합 지수는 지수 지표의 평균 변화를 특성화하는 일반적인 척도이며, 물론 그 값은 다음과 같아야 합니다. 개별 지수의 값에 따라 다릅니다. 그리고 평균값(평균지수) 형태로 복합지수를 구성하는 정확성의 기준은 종합지수에 대한 동일성이다. 집계 지수를 개별(그룹) 지수의 평균으로 변환하는 작업은 다음과 같이 수행됩니다. 집계 지수의 분자 또는 분모에서 인덱싱된 지표는 해당 개별 지수에 대한 표현으로 대체됩니다. . 분자에서 이러한 대체가 이루어지면 총계 지수는 산술 평균으로 변환되고 분모에 있으면 개별 지수의 조화 평균으로 변환됩니다. 예를 들어, 물리적 볼륨 iq = q1/q0의 개별 지수와 기준 기간(q0p0)의 각 유형의 생산 비용이 알려져 있습니다. 개별 지수의 평균을 구성하는 초기 기초는 물리적 볼륨의 복합 지수입니다. 
(라스파이레스 지수의 집계 형태). 사용 가능한 데이터에서 공식의 분모만 합계를 통해 직접 얻을 수 있습니다. 분자는 기본 기간의 개별 제품 유형 비용에 개별 지수를 곱하여 얻을 수 있습니다. 
그러면 복합 지수의 공식은 다음과 같은 형식을 취합니다. 
즉, 우리는 물리적 부피의 산술 평균 지수를 얻습니다. 여기서 가중치는 기준 기간의 개별 유형 제품 비용입니다. 보고 기간(p1q1)에 각 제품 유형의 생산량(r^)과 각 유형의 제품 비용의 역학에 대한 정보가 있다고 가정합니다. 이 경우 기업 생산량의 총 변화를 결정하려면 Paasche 공식을 사용하는 것이 편리합니다. 
공식의 분자는 q1P1 값을 합산하고 분모는 각 제품 유형의 실제 비용을 물리적 생산량의 해당 개별 지수로 나누어 얻을 수 있습니다. 
따라서 물리적 부피의 평균 가중 조화 지수에 대한 공식을 얻습니다. 물리적 부피 지수(총계, 산술 평균 및 조화 평균)에 대한 하나 또는 다른 공식의 사용은 사용 가능한 정보에 따라 다릅니다. 또한 보고 기간과 기준 기간의 제품 또는 상품 유형 목록(해당 범위)이 일치하는 경우(즉, 총 지수가 비교 가능한 범위의 단위를 기반으로 합니다( 비교 가능한 분류에 따라 질적 지표의 집계 지표 및 볼륨 지표의 집계 지표). 주제 8. 역학 분석 8.1. 사회 경제 현상의 역학 및 통계 연구의 과제 사회경제적 통계가 연구하는 사회생활의 현상은 끊임없이 변화하고 발전하고 있다. 시간이 지남에 따라 - 매월, 해마다 - 인구의 규모와 구성, 생산량, 노동 생산성 수준 등이 변화하므로 통계의 가장 중요한 임무 중 하나는 연구입니다. 시간에 따른 사회 현상의 변화 - 발달 과정, 역학. 통계는 시계열(시계열)을 구성하고 분석하여 이 문제를 해결합니다. 일련의 역학(시간순, 동적, 시계열)은 연구 중인 현상의 발전 수준을 특성화하는 일련의 숫자 지표입니다. 시리즈에는 시간과 지표의 특정 값(시리즈 수준)이라는 두 가지 필수 요소가 포함됩니다. 현상의 크기, 크기를 특성화하는 지표의 각 숫자 값을 계열의 수준이라고합니다. 레벨 외에도 각 역학 시리즈에는 레벨과 관련된 순간 또는 기간의 표시가 포함됩니다. 통계적 관찰 결과를 종합하면 두 가지 유형의 절대 지표가 얻어진다. 그들 중 일부는 특정 시점의 현상 상태를 특성화합니다. 그 순간에 전체 단위의 존재 밀도 또는 피쳐의 하나 또는 다른 볼륨의 존재. 이러한 지표에는 인구, 자동차 차량, 주택 재고, 상품 재고 등이 포함됩니다. 이러한 지표의 가치는 특정 시점에서만 직접 결정할 수 있으므로 이러한 지표와 해당 시계열을 모멘텀이라고 합니다. 다른 지표는 특정 기간(간격)(일, 월, 분기, 연도 등) 동안의 프로세스 결과를 특성화합니다. 이러한 지표는 예를 들어 출생 수, 제조된 제품 수, 주거용 건물의 시운전, 임금 기금 등입니다. 이러한 지표의 가치는 일정 기간(기간) 동안만 계산할 수 있으므로 그러한 표시기 및 해당 일련의 값을 간격이라고 합니다. 해당 시계열 수준의 일부 기능(속성)은 간격 및 모멘트 절대 표시기의 다른 특성에서 따릅니다. 간격 계열에서 특정 시간 간격(기간)에 대한 프로세스의 결과인 수준 값은 이 기간(간격의 길이)에 따라 다릅니다. 다른 조건이 같으면 구간 계열의 수준이 클수록 이 수준이 속하는 구간의 길이가 길어집니다. 역학의 순간 시리즈에서 간격 - 시리즈의 인접한 날짜 사이의 시간 간격 - 특정 수준의 값은 인접한 날짜 사이의 기간에 의존하지 않습니다. 간격 계열의 각 수준은 이미 더 짧은 기간에 대한 수준의 합계입니다. 동시에 한 수준의 일부인 인구 단위는 다른 수준에 포함되지 않으므로 역학의 간격 시리즈에서 인접한 기간의 수준을 요약하여 더 긴 기간 동안 결과(수준)를 얻을 수 있습니다. 기간 (따라서 월별 수준을 합산하면 분기별로, 분기별로 합산하여 연간을 얻고 연간 합산 - 다년) 때로는 인접한 시간 간격에 대한 간격 계열의 수준을 순차적으로 추가하여 일련의 누적 합계가 구성되며 각 수준은 특정 날짜( 연초부터 등) .). 이러한 누적 결과는 종종 기업의 회계 및 기타 보고서에 제공됩니다. 순간 시계열에서 인구의 동일한 단위는 일반적으로 여러 수준에 포함되므로 이 경우 얻은 결과에 독립적인 경제적 중요성이 없기 때문에 역학의 순간 시리즈 수준 자체를 요약하는 것은 의미가 없습니다 . 위에서 초기, 기본인 절대값의 일련의 역학에 대해 언급했습니다. 그들과 함께 일련의 역학이 구성될 수 있으며, 그 수준은 상대적이고 평균입니다. 또한 일시적이거나 간격일 수 있습니다. 상대 및 평균 값의 역학의 간격 시리즈에서 상대 및 평균 값은 파생 상품이며 다른 값을 나누어 계산하기 때문에 레벨 자체의 직접적인 합은 의미가 없습니다. 일련의 역학을 구성하고 분석하기 전에 먼저 시리즈의 수준이 서로 비교할 수 있다는 사실에주의를 기울여야합니다.이 경우에만 동적 시리즈가 현상의 발전을 올바르게 반영하기 때문입니다 . 일련의 역학 수준의 비교 가능성은 이 시리즈의 분석 결과 얻은 결론의 타당성과 정확성을 위한 가장 중요한 조건입니다. 시계열을 구성할 때 시리즈는 비교 가능성을 위반하는 변경(영토 변경, 개체 범위 변경, 계산 방법 등)이 발생할 수 있는 많은 기간을 포함할 수 있음을 염두에 두어야 합니다. 사회 현상의 역학을 연구할 때 통계는 다음 작업을 해결합니다. - 별도의 기간 동안 수준의 절대 및 상대 성장률 또는 감소를 측정합니다. - 주어진 기간 동안 수준의 일반적인 특성과 변화율을 제공합니다. - 개별 단계에서 현상 발전의 주요 경향을 밝히고 수치로 특성화합니다. - 다른 지역 또는 다른 단계에서 이 현상의 발전에 대한 비교 수치적 특성을 제공합니다. - 시간에 따라 연구 현상의 변화를 일으키는 요인을 밝힙니다. - 미래에 현상의 발전을 예측합니다. 8.2. 역학 시리즈의 주요 지표 역학을 연구할 때 초등학교, 단순 및 더 복잡한 다양한 지표와 분석 방법이 사용되므로 더 복잡한 수학 섹션을 사용해야 합니다. 주로 일련의 역학 수준의 변화율을 측정할 때 여러 문제를 해결하는 데 사용되는 가장 간단한 분석 지표는 절대 성장률, 성장률 및 성장률 및 절대값(내용)입니다. XNUMX퍼센트 성장. 이러한 지표의 계산은 일련의 역학 수준을 서로 비교하는 것을 기반으로 합니다. 동시에 비교가 이루어지는 수준은 비교의 기준이 되므로 기준 수준이라고 합니다. 일반적으로 이전 수준 또는 일부 이전 수준(예: 시리즈의 첫 번째 수준)이 비교 기준으로 사용됩니다. 각 레벨을 이전 레벨과 비교하면 이 경우에 얻은 지표를 체인 지표라고 합니다. 말하자면 시리즈의 레벨을 연결하는 "체인"의 링크이기 때문입니다. 모든 수준이 동일한 수준과 연결되어 일정한 비교 기준 역할을 하는 경우 이 경우 얻은 지표를 기본이라고 합니다. 종종 일련의 역학 구성은 지속적인 비교 기준으로 사용될 수준에서 시작됩니다. 이 기초의 선택은 연구중인 현상의 발전의 역사적, 사회 경제적 특징에 의해 정당화되어야합니다. 몇 가지 특징적이고 전형적인 수준을 기본 수준으로 취하는 것이 편리합니다. 예를 들어 개발 이전 단계의 최종 수준(또는 이전 단계에서 수준이 증가하거나 감소한 경우 평균 수준)입니다. 절대 증가는 주어진 기간(기간) 동안 기준선과 비교하여 수준이 증가(또는 감소)한 단위 수를 나타냅니다. 절대 증가는 비교된 수준 간의 차이와 같으며 다음 수준과 동일한 단위로 측정됩니다. ? =yi?yi?1; ? = yi ?y0 , 여기서 yi는 i번째 연도의 수준입니다. yi-1 - 전년도 수준; y0 - 기준 연도 수준. 레벨이 기준선에 비해 감소했다면 ? ‹0; 그것은 수준의 절대적인 감소를 특징으로 합니다. 단위 시간(월, 년)당 절대 성장률은 해당 수준의 절대 성장률(또는 하락)을 측정합니다. 체인과 기본 절대 성장은 서로 연결되어 있습니다. 연속적인 체인 성장의 합은 해당 기본 성장, 즉 전체 기간의 총 성장과 같습니다. 절대값이 상대값으로 보완될 때만 성장에 대한 보다 완전한 특성화를 얻을 수 있습니다. 역학의 상대적 지표는 성장 과정의 강도를 특징짓는 성장률과 성장률입니다. 성장률(Tr)은 일련의 역학 수준의 변화 강도를 반영하는 통계 지표로 기준선에 비해 수준이 몇 배 증가했는지, 감소한 경우 기준선의 어느 부분 는 비교 수준입니다. 이전 또는 기준에 대한 현재 수준의 비율로 측정: 
다른 상대값과 마찬가지로 성장률도 계수(단순한 수준의 비율)의 형태로 나타낼 수 있을 뿐만 아니라 백분율로도 나타낼 수 있습니다. 절대 성장률과 마찬가지로 모든 시계열의 성장률은 그 자체로 간격 지표입니다. 즉, 하나 또는 다른 기간(간격)을 나타냅니다. 사슬과 기본 성장률 사이에는 일정한 관계가 있으며, 계수 형태로 표시됩니다. 연속 사슬 성장률의 곱은 전체 해당 기간의 기본 성장률과 같습니다. 예: y2/y1 y3/y2 = y3 / y1. 성장률(Tpr)은 상대 성장률을 나타냅니다. 즉, 이전 또는 기본 수준에 대한 절대 성장률의 비율입니다. 
백분율로 표시되는 성장률은 100%로 간주하여 기준선과 비교하여 수준이 몇 퍼센트 증가(또는 감소)했는지 보여줍니다. 발전 속도를 분석할 때 성장률과 성장률 뒤에 숨겨진 절대값, 즉 수준과 절대적 증가를 간과해서는 안 됩니다. 특히, 성장률과 성장률이 감소(감속)되면 절대 성장률이 증가할 수 있다는 점을 염두에 두어야 합니다. 이와 관련하여 절대 성장률을 해당 성장률로 나눈 결과로 결정되는 1% 성장률의 절대 값(내용)인 역학의 또 다른 지표를 연구하는 것이 중요합니다. 
이 값은 성장의 각 백분율이 제공하는 절대적 측면을 보여줍니다. 때로는 지역, 부서 및 기타 변경 (회계 및 지표 계산 방법론의 변경 등)으로 인해 XNUMX 년 동안의 현상 수준이 다른 해의 수준과 비교할 수 없습니다. 비교가능성을 확보하고 분석에 적합한 시계열을 얻기 위해서는 다른 것과 비교할 수 없는 수준을 직접 재계산해야 한다. 그러나 때때로 이에 필요한 데이터를 사용할 수 없습니다. 이러한 경우 일련의 역학을 닫는 특수 기술을 사용할 수 있습니다. 예를 들어, i 번째 해에 일부 현상의 발전 역학이 연구 된 영역의 경계에 변화가 있다고 가정합니다. 그러면 올해 이전에 얻은 데이터는 다음 연도의 데이터와 비교할 수 없습니다. 이 시리즈를 닫고 전체 기간 동안 시리즈의 역학을 분석할 수 있도록 하기 위해 각 시리즈를 비교 기준으로 사용합니다. 영토의 오래된 경계와 새로운 경계. 동일한 비교 기준을 가진 이 두 행은 하나의 닫힌 역학 행으로 대체될 수 있습니다. 닫힌 계열의 데이터에서 연도와 비교하여 성장률을 계산할 수 있으며 새 경계 내에서 전체 기간에 대한 절대 수준을 계산할 수도 있습니다. 그럼에도 불구하고 일련의 역학을 닫음으로써 얻은 결과에는 약간의 오류가 포함되어 있음을 명심해야 합니다. 그래픽으로 현상의 역학은 막대 및 선 차트의 형태로 가장 자주 묘사됩니다. 곱슬, 정사각형, 섹터 등의 다른 형태의 차트도 사용됩니다. 분석 차트는 일반적으로 꺾은선형 차트의 형태로 작성됩니다. 8.3. 평균 역학 시간이 지남에 따라 현상의 수준이 변할뿐만 아니라 역학의 지표 - 절대 증분 및 발전 속도, 따라서 발전의 일반화 특성을 위해 일반적인 주요 추세 및 패턴을 식별 및 측정하고 다른 문제를 해결하기 위해 분석의 평균 수준, 평균 절대 이득 및 평균 역학 비율과 같은 시계열의 평균 지표가 사용됩니다. 평균 및 상대 값을 계산할 때 분자와 분모의 비교 가능성을 보장하기 위해 시계열을 구성할 때 이미 일련의 역학의 평균 수준 계산에 의존해야 하는 경우가 종종 있습니다. 예를 들어 러시아 연방에서 XNUMX인당 전력 생산의 일련의 역학을 구축해야 한다고 가정해 보겠습니다. 이렇게하려면 매년 주어진 연도에 생산 된 전력량 (간격 표시기)을 같은 해의 인구로 나눌 필요가 있습니다 (순간 표시기, 그 값은 일년 내내 계속 변합니다). 일반적인 경우 한 지점 또는 다른 지점의 인구 규모는 전체 연도의 생산량과 비교할 수 없다는 것이 분명합니다. 비교 가능성을 보장하기 위해 인구의 날짜를 어떻게 든 전체 연도로 계산해야 하며 이는 해당 연도의 평균 인구를 계산해야만 가능합니다. 많은 현상의 수준이 예를 들어 매년 증가하거나 감소하는 것과 같이 기간에 따라 크게 변동하기 때문에 역학의 평균 지표에 의존하는 것이 종종 필요합니다. 이것은 연도가없는 많은 농업 지표에 특히 해당되므로 농업 발전을 분석 할 때 연간 지표가 아니라 몇 년 동안보다 일반적이고 안정적인 평균 연간 지표로 작동하는 경우가 많습니다. 역학의 평균 지표를 계산할 때 평균 값 이론의 일반 조항이 이러한 평균 지표에 완전히 적용된다는 점을 염두에 두어야 합니다. 이것은 무엇보다도 동적 평균이 현상의 발전을 위한 균질하고 다소 안정적인 조건을 가진 기간을 특징짓는다면 동적 평균이 전형적이라는 것을 의미합니다. 이러한 기간의 할당(발전 단계)은 어떤 면에서 그룹화와 유사합니다. 현상의 진행 조건이 크게 변경된 기간, 즉 현상의 발전 단계를 포괄하는 기간에 대해 동적 평균값을 계산하는 경우 이러한 평균값은 각별히 주의하여 사용해야 합니다. 개별 단계에 대한 평균 값을 사용합니다. 역학의 평균 지표는 또한 논리적 및 수학적 요구 사항을 충족해야하며, 이에 따라 평균을 얻은 실제 값을 대체 할 때 정의 지표의 값, 즉 평균 지표와 관련된 일부 일반화 지표, 변경해서는 안됩니다. 일련의 역학의 평균 수준을 계산하는 방법은 주로 계열의 기본 지표의 특성, 즉 시계열 유형에 따라 다릅니다. 가장 간단한 방법은 동일한 수준의 절대값 역학의 간격 계열의 평균 수준을 계산하는 것입니다. 계산은 간단한 산술 평균의 공식에 따라 이루어집니다. 
여기서 n은 연속적인 동일한 시간 간격에 대한 실제 레벨의 수입니다. 절대값의 역학 모멘트 시리즈의 평균 수준을 계산하면 상황이 더 복잡해집니다. 모멘트 표시기는 거의 지속적으로 변경될 수 있으므로 변경에 대한 데이터가 더 자세하고 철저할수록 평균 수준을 더 정확하게 계산할 수 있습니다. 또한 계산 방법 자체는 사용 가능한 데이터가 얼마나 상세한지에 따라 다릅니다. 여기에서는 다양한 경우가 가능합니다. 모멘트 지표의 변화에 대한 포괄적 인 데이터가있는 경우 평균 수준은 수준이 다른 간격 시리즈에 대한 산술 가중 평균 공식으로 계산됩니다. 
여기서 t는 수준이 변경되지 않은 기간의 수입니다. 인접한 날짜 사이의 시간 간격이 서로 동일한 경우, 즉 날짜 사이의 동일한(또는 거의 동일한) 간격을 처리할 때(예: 수준이 매월 또는 분기, 연도의 시작에 알려진 경우), 등거리 수준의 순간 시리즈의 경우 연대순 평균 공식을 사용하여 시리즈의 평균 수준을 계산합니다. 
레벨이 다른 모멘트 시리즈의 경우 시리즈의 평균 레벨은 공식을 사용하여 계산됩니다. 
위에서 우리는 절대값의 역학 계열의 평균 수준에 대해 이야기했습니다. 일련의 평균 및 상대 값의 역학에 대해 이러한 평균 및 상대 지표의 내용과 의미를 기반으로 평균 수준을 계산해야 합니다. 평균 절대 증가는 단위 시간(평균, 월간, 연간 등)당 평균적으로 이전 기간에 비해 수준이 증가하거나 감소한 단위를 나타냅니다. 평균 절대 증가는 수준의 평균 절대 성장률(또는 감소)을 특징짓고 항상 간격 지표입니다. 전체 기간의 총 성장률을 다양한 시간 단위에서 이 기간의 길이로 나누어 계산합니다. - 평균 절대 사슬 성장의 계산: 
- 평균 절대 기본 증가의 계산: 
여기서 - 연속적인 기간 동안의 체인 절대 증분. n은 체인 증분 수입니다. Y0 - 기본 기간의 수준입니다. 평균 성장률(및 평균 절대 증가)을 계산하는 정확성에 대한 기준 및 기준으로 고려 중인 전체 기간의 성장률과 동일한 연쇄 성장률의 곱을 다음과 같이 사용할 수 있습니다. 결정 지표. 따라서 n 체인 성장률을 곱하면 전체 기간에 대한 성장률을 얻을 수 있습니다. 
공식 8.11의 실제 연쇄 속도를 대체할 때 전체 기간(y1 / y1 -1)의 성장률이 변경되지 않고 유지되는 평균 성장률(p)을 찾는 작업을 설정해 보겠습니다. 따라서 평등 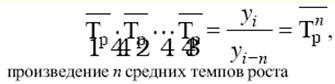
다음 중: 
여기서 n은 역학 시리즈의 레벨 수입니다. T1, T2, Tp - 사슬 성장률. 공식 (8.1)은 단순 기하 평균, (8.2) 암시적 기하 평균이라고 합니다. 계수의 형태로 표현된 평균 성장률은 단위 시간당(평균 연간, 월간 등) 이전 기간에 비해 몇 배나 증가했는지를 나타냅니다. 평균 성장률과 성장률의 경우 정상 성장률과 성장률 사이에 동일한 관계가 유지됩니다. 
백분율로 표시되는 평균 증가율(또는 감소율)은 단위 시간(평균 연간, 월간 등)당 이전 기간에 비해 수준이 몇 퍼센트 증가(또는 감소)했는지를 나타냅니다. 평균 성장률은 평균 성장률, 즉 레벨 변화의 평균 상대 비율을 나타냅니다. 평균 성장률에 대한 두 가지 유형의 공식 중에서 모든 사슬 성장률을 계산할 필요가 없기 때문에 공식 (8.2)가 더 자주 사용됩니다. 공식 (8.1)에 따르면 일련의 역학 수준이나 전체 기간의 성장률을 알지 못하고 연쇄 성장률 (또는 성장률) 만 알려진 경우에만 계산하는 것이 좋습니다. 8.4. 주요 개발 동향의 식별 및 특성화 시계열 분석에서 발생하는 작업 중 하나는 시간에 따라 연구 중인 지표 수준의 변화 패턴을 설정하는 것입니다. 이를 위해서는이 현상과 다른 현상의 관계 및 발달 조건과 관련하여 충분히 균질 한 개발 기간 (단계)을 선별해야합니다. 발달 단계의 식별은 이러한 현상을 연구하는 과학(경제학, 사회학 등)과 통계의 교차점에서 수행되는 작업입니다. 이 문제의 해결책은 통계적 방법의 도움을 받아 수행될 뿐만 아니라(그들은 어느 정도 도움이 될 수 있음에도 불구하고) 본질, 현상의 본질 및 일반 그것의 발달 법칙. 발전의 각 단계에 대해 현상의 수준을 변화시키는 주요 경향을 식별하고 수치적으로 특성화할 필요가 있다. 추세는 시간이 지남에 따라 현상 수준의 증가, 감소 또는 안정화를 향한 일반적인 방향으로 이해됩니다. 레벨이 지속적으로 증가하거나 지속적으로 감소하면 상승 또는 하락 추세가 명확하게 관찰됩니다. 시계열 그래프에서 시각적으로 쉽게 감지됩니다. 그러나 레벨의 성장과 감소는 균등하게, 가속되거나, 느려지는 등 다른 방식으로 발생할 수 있다는 점을 염두에 두어야 합니다. 균일한 성장(또는 쇠퇴)은 사슬의 절대 증분(;)이 동일할 때 일정한 절대 속도로 성장(또는 쇠퇴)하는 것으로 이해됩니다. 증가 또는 감소가 가속화되면 체인 증분은 체계적으로 절대값으로 증가하고 성장이 느리거나 감소하면 감소합니다(절대값에서도). 실제로, 일련의 역학 수준이 엄격하게 균일하게 증가(또는 감소)하는 경우는 매우 드뭅니다. 드물게 단일 편차 없이 체인 증분의 증가 또는 감소가 체계적으로 발생합니다. 이러한 편차는 현상의 수준이 의존하는 주요 원인 및 요인의 전체 복합체의 시간 경과에 따른 변화 또는 무작위, 상황 및 따라서 요인을 분석할 때 역학을 분석할 때 개발 추세가 아니라 이 개발 단계 전반에 걸쳐 상당히 안정적인(지속 가능한) 주요 추세에 대해 이야기하고 있습니다. 어떤 경우에는 개체 개발의 일반적인 추세인 이 패턴이 동적 계열의 수준으로 매우 명확하게 표시됩니다. 주요 추세(추세)는 시간에 따른 현상 수준의 상당히 부드럽고 안정적인 변화이며 임의의 변동이 거의 없습니다. 주요 추세는 추세의 방정식(모델) 형태로 분석적으로 또는 그래픽으로 나타낼 수 있습니다. 시계열의 정렬에서는 주요 발전 추세(트렌드)의 식별을 통계라고도 하며, 주요 추세를 식별하는 방법을 정렬 방법이라고 합니다. 일련의 역학의 주요 추세(추세)를 식별하는 가장 일반적인 방법 중 하나는 다음 방법입니다. - 간격의 통합; - 이동 평균(방법의 본질은 특정 기간 동안 절대 데이터를 산술 평균으로 대체하는 것입니다). 평균 계산은 슬라이딩 방식으로 수행됩니다. 즉, 첫 번째 수준의 허용 기간에서 점진적으로 제외하고 다음 수준을 포함합니다. - 분석적 정렬. 이 경우 역학 계열의 수준은 시간의 함수로 표현됩니다. 1) f (t) = a0 + a1t - 선형 의존성; 2) f (t) = a0 + a1t + a2t2 - 포물선 의존성. 간격의 확대 방법 및 평균 수준에 따른 특성은 더 짧은 간격에서 더 긴 간격으로의 전환으로 구성됩니다. 기간 간격. 일련의 역학 수준이 다소 일정한 주기성(파동 모양)으로 변동하는 경우 진동 주기(주기의 "파동" 길이)와 동일한 확대 간격을 취하는 것이 좋습니다. 그러한 주기성이 없으면 추세의 일반적인 방향이 충분히 뚜렷해질 때까지 작은 간격에서 더 큰 간격으로 점진적으로 확대가 수행됩니다. 역학 계열이 일시적이고 계열의 수준이 상대적 또는 평균값인 경우에도 수준의 합계가 의미가 없으며 집계된 기간은 평균 수준으로 특성화되어야 합니다. 간격이 확대되면 동적 계열의 구성원 수가 크게 감소하므로 확대된 간격 내에서 수평 이동이 시야에서 벗어납니다. 이와 관련하여 주요 추세와 더 자세한 특성을 식별하기 위해 이동 평균을 사용하여 계열을 평활화합니다. 이동 평균을 사용하여 일련의 역학을 평활화하는 것은 시리즈의 특정 수의 첫 번째 수준에서 평균 수준을 계산한 다음 동일한 수의 수준에서 평균 수준을 계산하고 두 번째부터 시작하여 세 번째부터 시작하는 방식으로 구성됩니다. 따라서 평균 수준을 계산할 때 처음부터 끝까지 시계열을 따라 "이동"하며 매번 처음에 한 수준을 버리고 다음 수준을 추가합니다. 따라서 이름 - 이동 평균. 이동 평균의 각 링크는 해당 기간의 평균 수준입니다. 그래픽 표현과 일부 계산을 통해 각 링크는 일반적으로 계산이 이루어진 기간의 중심 간격(즉석 시리즈의 경우 중심 날짜)을 참조합니다. 이동 평균 링크를 계산해야 하는 기간에 대한 질문은 역학의 특정 기능에 따라 다릅니다. 간격의 확대와 마찬가지로 레벨 변동에 일정한 주기성이 있는 경우 진동 기간 또는 그 값의 배수와 동일한 평활 기간을 취하는 것이 좋습니다. 따라서 연간 계절적 감소 및 증가를 경험하는 분기별 수준이 있는 경우 XNUMX분기 또는 XNUMX분기 평균 등을 사용하는 것이 좋습니다. 수준 변동이 불규칙한 경우 다음까지 평활 간격을 점진적으로 늘리는 것이 좋습니다. 명확한 추세 패턴이 나타납니다. 시계열의 분석적 정렬을 통해 추세의 분석적 모델을 얻을 수 있습니다. 다음과 같은 방식으로 생산됩니다. - 의미 있는 분석을 바탕으로 발전단계를 선별하여 이 단계의 역동성을 정립한다. - 하나 또는 다른 성장 패턴의 가정과 역학의 특성에 따라 추세의 분석 표현 형식이 선택되고 그래픽으로 특정 선에 해당하는 근사 함수 유형: 직선, 포물선, 지수 곡선 등. 이 선(함수)은 시간 경과에 따른 부드러운 수준 변화의 예상 패턴, 즉 주요 추세를 나타냅니다. 이 경우 일련의 역학의 각 수준은 조건부로 두 구성 요소(구성 요소)의 합으로 간주됩니다. yt=f(t)+?t. 추세를 나타내는 그 중 하나(yt = f(t))는 영구적인 주요 요인의 영향을 특성화하며 체계적인 규칙 구성 요소라고 합니다. 또 다른 구성요소(8t)는 무작위 요소 및 환경의 영향을 반영하며 무작위 구성요소라고 합니다. 이 구성 요소는 추세에서 실제 수준의 편차와 같기 때문에 잔차(또는 단순히 잔차)라고도 합니다. 따라서 지속적으로 작용하는 주요인의 영향으로 주추세(추세)가 형성되고, 이차적 변이요인으로 인해 추세에서 벗어나게 되는 것으로 가정(조건부 가정)한다. 곡선 모양의 선택은 추세 외삽의 결과를 크게 결정합니다. 이 현상의 발전 본질에 대한 의미있는 분석은 곡선 유형을 선택하는 기초로 사용할 수 있습니다. 또한 이 분야의 이전 연구 결과에 의존할 수도 있습니다. 가장 간단한 경험적 기법은 시각적 기법입니다. 즉, 시리즈의 그래픽 표현(파선)을 기반으로 추세 모양을 선택하는 것입니다. 실제로 선형 종속성은 단순성으로 인해 포물선형 종속성보다 더 자주 사용됩니다. 사회경제적 통계 주제 9. 주 규정에 사용되는 사회경제적 통계 및 지표의 주제 및 방법 9.1. 사회 경제 통계의 개념, 주제 및 방법 사회경제통계는 경제와 사회영역에서 일어나는 대중현상과 과정의 양적 특성을 연구하는 과학분야이다. 사회경제적 통계자료는 사회에서 일어나는 다양한 경제적, 사회적 과정에 대한 체계적인 정량적 기술을 제공한다. 이 분야에는 사회 인구 통계, 인구 생활 수준 통계, 노동 및 고용 통계, 물가 통계, 투자 통계, 국부 통계, 다양한 산업 통계(운송, 건설, 인구, 농업 등)와 같은 섹션이 포함됩니다. . 사회 경제 통계에는 다음 지표가 사용됩니다. - 가격 역학의 지표; - 제조 제품의 양 및 비용 지표; - 인구의 수와 구성에 대한 지표; - 인구의 생활 수준 지표; - 인구의 소득 및 지출 지표; - 노동, 물질 및 재정 자원의 지표; - 생산성 및 임금 지표; - 고정 및 운전 자본의 가용성 지표; - 거시 경제 지표. 위의 지표는 일반 통계 이론의 도구를 사용하여 다양한 방법으로 계산됩니다. 통계 방법론의 중요한 조건은 시간과 공간 및 국제적으로 데이터의 비교 가능성을 보장하는 것입니다. 따라서 사회 경제적 통계의 주제는 장소와 시간의 특정 조건에서 사회 경제적 지표에 대한 연구, 그 역학 및 가장 중요한 관계에 대한 분석입니다. 사회경제통계의 주요업무는 다음과 같다. - 정부 당국이 사회 경제적 정책 및 정부 프로그램 형성 분야에서 적절한 결정을 내리는 데 필요한 정보 제공 - 모든 이해 관계자와 기관에 국가 및 인구 집단의 경제 및 사회적 영역 상태에 대해 알립니다. - 연구 기관, 사회 정치 단체에 국가의 사회 경제적 발전 결과에 대한 데이터 제공. 나열된 사회 경제 통계 작업은 국가의 사회 경제 개발 프로그램 구현과 긴밀한 상호 작용을합니다. 현대 사회경제적 통계에서는 가동률의 증감에 따른 국내총생산(GDP) 생산량의 변화를 반영하는 경제상황 지표를 매우 중시하며, 결과적으로 소비자 수요의 변화. 경제 성장 지표는 생산 능력 증가, 투자 유치 및 노동 생산성 증가의 결과로 GDP 생산량의 변화를 나타냅니다. 위의 내용 외에도 사회 경제 통계의 중요한 임무는 국가 예산 분석, 구조, 역학, 형성 출처 및 지출 방향에 대한 연구입니다. 이와 관련하여 재정 및 통화 정책의 효과를 평가하기 위해 GDP 대비 국가 예산 적자 비율을 포함한 다양한 절대 및 상대 지표가 사용됩니다. 똑같이 중요한 또 다른 작업은 저축률에 영향을 미치는 요인을 연구하는 것입니다. 이러한 요소는 은행 금리의 크기, 가처분 소득 금액, 예금의 수익성 등입니다. 현재 러시아에서 대외 경제 관계가 활발히 발전하고 있으므로 대외 무역에 대한 신뢰할 수있는 통계 데이터, 환율의 통계 모니터링 및 환율의 역학에 영향을 미치는 요인 분석에 대한 관심이 증가하고 있습니다. 사회경제통계의 다음으로 중요한 과제는 화폐시장과 주식시장의 활동과 다양한 거시경제지표의 형성에 미치는 영향을 분석하는 것이다. 이와 관련하여 통계 기관은 사회 경제적 현상 간의 관계를 포괄적이고 완전히 특성화하는 상호 연결된 통계 지표 시스템에 의존하여 정책 개발 및 관리 결정에 필요한 모든 정보를 수집, 처리 및 추가 분석을 제공해야 합니다. 사회의 경제 및 사회 생활 분야에서 만들기. 국가의 노동, 물질 및 재정 자원에 대한 연구는 자산과 부채의 균형을 집계하여 국민 계정 시스템을 사용하여 해결되는 사회 경제 통계의 또 다른 중요한 과제입니다. 환경 상태의 관찰 및 모니터링은 천연 자원의 고갈을 모니터링하고 천연 자원의 상태 및 소비 조건에 대한 필요한 정보를 제공해야 하는 통계 당국의 책임이기도 합니다. 통계 정보 시스템에는 다음과 같은 경제 현상 및 프로세스에 대한 정보, 설명 및 분석이 포함됩니다. - 국가의 경제 자원의 구조 및 개발; - 인구, 번식의 가장 중요한 지표; - 경제 과정의 결과, 경제 성장률; - 소득 분배; - 인플레이션에 영향을 미치는 요인; - 고용 및 실업 및 이에 영향을 미치는 요인; - 인구 생활 수준의 역학, 상품 및 서비스 소비; 소득 및 저축; - 투자 프로세스, 자금 출처의 효율성; 금융 시스템의 활동: 금융 거래, 국가 예산, 금융 부채, 주식 시장; 환경의 상태. 사회의 사회 경제적 삶에 대한 연구의 통계 방법론에 대해 말하면 연구 된 과정, 현상, 경제 및 사회 환경의 메커니즘을 반영하는 과학적으로 개발 된 개념과 정의를 기반으로해야한다는 점에 유의해야합니다. 이러한 과학적으로 조직화된 분석의 핵심은 일반통계이론의 방법과 균형방법이다. 9.2. 스코어카드 및 경제통계 구성 특정 종류의 경제 현상과 전체 경제를 연구하기 위해 통계적 방법과 도구를 적용하여 숫자 또는 숫자인 통계 데이터를 얻습니다. 통계에 사용되는 숫자, 수치는 추상적이지 않은 것, 즉 통계적 데이터를 통계적 지표로 특징짓기 때문에 수학적 숫자로 간주해서는 안 됩니다. 경제 통계에서 경제 지표는 모든 경제 현상이나 과정을 반영하는 데이터를 일반화합니다. 경제 통계의 대상은 연구 된 모든 과정과 현상이 격리되지 않고 상호 연결되어 있으므로 이러한 현상과 과정을 특징 짓는 모든 통계 지표도 격리되지 않은 우리나라의 경제입니다. 따라서 모든 통계 지표는 서로 연결되어 통계 지표 시스템을 형성합니다. 통계 지표 시스템은 단일 수준 및 다단계 구조를 가지며 특정 통계 문제를 해결하는 것을 목표로 하는 상호 연관된 통계 지표의 집합입니다[1]. 경제 통계 지표 시스템은 많은 경제 문제를 설명하기 위해 형성되고 자체 구조와 일정 수의 연결이 가능한 경제 통계 지표의 기초입니다. 시스템의 모든 지표는 상호 연결되어 있으므로 다른 구성 지표를 알면 알려지지 않은 지표를 계산할 수 있습니다. 경제 통계 지표 시스템은 다양한 수준에서 사회의 모든 경제적 측면을 다룹니다. 국가, 지역 - 거시적 수준; 기업, 기업, 협회, 가족, 가정 - 미시적 수준. 경제 통계 지표 시스템은 다음 작업을 해결하는 것을 목표로합니다. - 러시아 연방 경제 기능의 구조를 상호 연결된 구성으로 보여줍니다. - 러시아 경제에서 발생하는 프로세스 분석의 주요 작업을 결정합니다. - 국내 및 세계 경험, 국제 경제 조직의 권장 사항을 고려하여 연방 및 지역 수준에서 분석에 필요한 지표 시스템을 구축합니다. - 통계 정보를 구성하는 방법에 대한 현대적인 접근 방식을 주장합니다. - 경제 분석 자체의 내용 측면을 기반으로 한 통계적 방법 세트를 개발합니다. 경제 통계 지표 시스템을 통해 경제 현상과 과정을 연구하는 과정을 통계 연구라고합니다. 경제 통계 지표 시스템에는 다음과 같은 특징이 있습니다. - 역사적 성격을 띠고 있습니다. 인구와 사회의 생활 조건이 변화하고 있습니다. - 특정 경제 시스템의 통계 지표도 변화하고 있습니다. - 통계 지표를 계산하는 방법 세트는 지속적으로 개선되고 있습니다. 경제 통계 지표 시스템을 기반으로 경제 문제를 해결할 준비가되어 있습니다. 통계 지표의 종류는 다음과 같이 분류됩니다. 인구의 개별 단위를 포함하여: - 통계 모집단의 별도 단위를 특성화하는 개별 통계 지표; - 개별 통계 지표를 합산하고 속성의 총량을 특성화하여 계산된 체적 통계 지표로 구분되는 요약 통계 지표; - 다양한 공식으로 계산되고 모든 종류의 분석 문제를 해결하도록 설계된 계산된 통계 지표. 시간 요소: - 특정 날짜에 설정되고 고정된 일시적 통계 지표; - 일정 기간 동안 설정된 간격 통계. 표현의 관점에서: - 일시적인 특성을 반영하여 경제 현상 및 프로세스의 절대 값을 특성화하는 절대 지표; - 하나의 절대 지표를 다른 절대 지표로 나누어 계산된 경제 과정과 현상의 양적 특성 간의 균형을 나타내는 상대 지표; - 평균 통계 지표는 특정 상황뿐만 아니라 장소와 시간의 특정 조건에서 통계 인구의 속성에 대한 일반화된 양적 특성입니다. 러시아 국가 통계 위원회가 제시한 2002년 러시아 연방의 주요 사회경제적 지표(표 9.1)를 고려하십시오. 표 9.1 2002 년 러시아 연방의 주요 사회 경제적 지표 
경제 주체의 상태에 대한 기본 정보의 수집, 처리에 대한 모든 활동은 러시아 연방 통계 기관에 할당됩니다. 경제 통계 조직의 필수 단계는 모든 경제 주체(기업, 조직, 기업)에서 기본 데이터를 수집하는 것입니다. 동시에 주요 수집 방법은 회계 및 통계 보고, 등록부 작성, 경제 및 인구 조사, 표본 조사 등입니다. 회계 정보는 수집되는 모든 정보의 상당 부분을 차지합니다. 경제통계의 업무는 수집된 회계자료를 경제통계의 요청에 따라 가져오는 것이다. 통계 당국은 현대의 통신 수단과 컴퓨터 기술을 사용하여 정보를 전송하고 저장하는 효과적인 시스템을 구성하여 기본 데이터를 수집하는 기존 시스템을 적용해야 합니다. 경제 통계는 전체 인구를 동질적인 그룹으로 분배하기 위한 기준의 정의를 포함하는 경제 분류를 기반으로 연구 중인 현상과 과정을 정량적으로 특성화하는 방법을 제공합니다. 이러한 분류를 통해 개별 그룹의 양적 특성과 비중을 결정할 수 있습니다. 또한 경제적 분류는 데이터를 구성하고 코딩을 위한 기반을 만드는 데 도움이 됩니다. 경제 통계와 회계 사이의 연결에는 양방향 특성이 있습니다. 회계 정보는 통계 지표를 일반화하는 데 사용됩니다. 계정과목표 및 회계보고 양식을 작성할 때 경제 통계의 원칙과 요구 사항이 고려됩니다. 다양한 출처에서 얻은 기본 데이터는 최종적으로 요약 지표를 계산하기 위해 처리됩니다. 9.3. 통계의 표기법 대중 사회 경제적 현상에 대한 통계 연구를 구성하는 통계는 초기 통계 개념과 범주, 다양한 표기 체계를 형성합니다. 여기에는 지표 시스템, 측정 단위 시스템, 그룹화 및 분류 시스템, 국가 계정 시스템, 통합 문서 시스템 등이 포함됩니다. 통계 방법론은 통계 연구의 일반 원칙 및 방법 집합이며, 그 기초는 공통 표기법 사용. 통계의 지표 시스템은 의미 론적 통일성으로 묶인 지표 목록으로 이해되며 다양한 방식으로 상호 관계에서 사회 경제적 현상과 범주를 특징 짓는 특정 구성 논리의 대상입니다. 통계 지표에는 정성적 및 정량적 평가가 있습니다. 정량적 지표의 분석을위한 필수 조건은 측정 단위, 무게, 길이, 부피 및 기타 특성을 측정하기위한 표준 목록을 포함하는 OKEI 통합 측정 단위 시스템을 준수하는 것입니다. 국가. 사회 경제적 과정과 현상에 대한 포괄적인 통계 연구는 그룹화 시스템을 기반으로 하는 경우 가장 효과적입니다. 그룹화 시스템은 연구되는 현상의 가장 중요한 측면을 종합적으로 반영하는 가장 중요한 특징에 따라 일련의 상호 관련된 통계적 그룹화입니다. 그룹화가 여러 기능을 기반으로 하는 경우 이러한 그룹화를 복합이라고 합니다. 그룹핑 특성의 유형에 따라 그룹핑은 양적 특성과 질적 특성에 따라 구분됩니다. 통계 실무에서 연구자는 종종 질적 특성이 많은 다양성을 가지며 고정 자산의 유형, 상품 및 제품의 범위, 근로자 및 직원의 직업 등 이 경우 품종 분류가 개발됩니다. 즉, 통계에 의해 관찰 된 개체를 클래스 (그룹)로 체계적으로 배포합니다. 분류는 일반적으로 오랫동안 사용되는 관찰 단위의 안정적인 차별화로 이해됩니다. 분류는 관찰 대상에서 발생한 변경 사항을 반영할 필요가 있을 때 다소 중요한 변경 사항이 있을 수 있습니다. 분류는 원칙적으로 국가 또는 국제 표준으로 승인됩니다. 따라서 분류기가 생성됩니다. 연구 중인 현상을 설명하는 질적 특징 세트의 인코딩된 목록입니다. 우리는 그 중 가장 중요한 것을 나열합니다. OKATO - 행정 영토 분할 객체의 전 러시아 분류기 -는 통계 분야에서 정보의 신뢰성, 비교 가능성 및 자동화된 처리를 보장하도록 설계되었습니다. OKATO의 분류 대상은 공화국, 영토, 지역, 연방 중요 도시, 자치 지역, 지구, 지구, 도시 등입니다. OKVED - 경제 활동 유형의 모든 러시아 분류기 -는 경제 활동 유형과 이에 대한 정보를 분류하고 코딩하기 위한 것입니다. OKVED는 국제 수준에서 비교를 위한 통계 정보를 준비할 때 활동 유형별 경제 프로세스 개발에 대한 국가 통계 모니터링을 구현하는 데 사용됩니다. OKOGU - 공공 기관 및 행정의 모든 러시아 분류기 -는 공공 기관 및 행정에 대한 정보를 간소화 및 체계화하고, 통계 회계를 수행하고, 국가 통계 관찰을 제공하도록 설계되었습니다. OKFS - 소유권 형태의 전 러시아 분류기 -는 통계 분야의 분석 문제를 해결하기 위해 민법 주제에 대한 정보를 포함하는 정보 자원, 등록부, 등록부 및 지적을 형성하기 위한 것입니다. OKFS 분류의 대상은 소유권의 형태입니다. OKOPF - 조직 및 법적 형태의 전 러시아 분류기 - 또한 통계 분야의 분석 문제를 해결하도록 설계되었습니다. OKOPF 분류의 대상은 조직 및 법적 형식입니다. OKSM - 전 세계 국가의 모든 러시아 분류기 -는 국가를 식별하도록 설계되었습니다. OKSM의 분류 대상은 주권 국가 또는 정치적, 경제적, 지리적 또는 역사적 특징을 가진 기타 영토입니다. 위의 모든 분류기는 USCC(러시아 연방 기술, 경제 및 사회 정보에 대한 통합 분류 및 코딩 시스템)의 일부이며 러시아 연방에서 시행 중인 규제 프레임워크에 따라 개발되었으며 통계 분류와 조화를 이룹니다. 유럽 경제 공동체에서 채택되었습니다. 이러한 분류기를 개발할 때 계층적 분류 방법과 순차 코딩 방법이 사용됩니다. 러시아에서 국제적으로 인정되는 회계 및 통계 시스템으로의 전환과 관련하여 기업, 조직, 기관 및 협회의 통합 국가 등록부(등록부) - USREO가 생성되어 작동하고 있습니다. 창설의 목적은 기업 및 조직의 통일된 국가 회계, 정보 기금의 형성을 보장하는 것입니다. 정보 기금의 가장 중요한 섹션인 분류에는 위의 모든 러시아 분류 기준에 따른 주제 분류가 포함됩니다. USREO 정보 기금은 식별, 참조 및 경제의 세 부분으로 구성됩니다. 식별 섹션은 러시아의 전체 정보 공간에 고유한 개체의 등록 코드입니다. 참조에는 머리의 이름, 대상의 주소, 전화 번호 등에 대한 정보가 포함됩니다. 경제에는 주제를 특징 짓는 지표가 포함됩니다. 따라서 국가 통계에 채택된 표기법 시스템은 러시아 연방의 공식 표준이며 분석 문제를 해결하는 데 사용되며 내부 요구와 국제 수준의 비교를 위해 통계 정보를 수집하고 처리하는 방법론의 기초입니다. 9.4. 국가 규제에 사용되는 통계 지표 현대 사회에서 국가의 주요 기능 중 하나는 국가의 사회 경제적 생활 과정을 규제하는 것입니다. 국가 규제의 주요 임무는 경제의 효율성과 인구의 생활 수준을 높이는 것입니다. 사회가 직면한 주요 사회경제적 문제를 해결하기 위해 통계는 우리 주변 세계에서 발생하는 사회 경제적 과정의 모든 측면을 특성화하는 포괄적인 지표 시스템을 제공합니다. 경제 및 사회 영역의 발전 수준과 역학을 특성화하는 지표 시스템 개선 분야와 통계 분야에서 많은 작업이 수행되고 있습니다. 경제 효율성의 기준은 노동력 및 생산 자산의 소비 자원에 대한 생산 된 국민 소득 또는 증분 가치의 최적 비율입니다. 효율성의 일반화 지표는 실제 비용이나 자원으로 사회적 생산의 달성 결과를 측정합니다. 이를 위해 실제 가격으로 표시되는 국민 소득의 금액이 자주 사용됩니다. 국민소득은 국가예산의 형성, 국내 화폐유통, 국제결제지급 등의 원천 역할을 한다. 국민소득으로 계산된 일반화 지표를 통해 새로 생성된 부분의 단위당 실질비용을 산정할 수 있다. 부문 간 균형의 도움으로 부문 간 비율, 특정 유형의 제품 단위당 직접 및 간접 비용 계수, 총 사회적 생산의 비용 및 지역 구조 등을 결정하는 기초 사회 총생산. 비용을 기준으로 계산되는 경제 효율성 지표는 국민 소득 단위 생산을 위한 연간 비용의 실제 수준을 반영합니다. 국민소득 생산에 생활노동, 원자재, 원자재, 연료가 얼마나 사용되는지를 보여준다. 인간 노동 사용의 효율성에 대한 자세한 특성은 다음 지표의 조합으로 표시됩니다. - 사회적 노동의 생산성; - 제품 및 작업의 복잡성; - 생산성과 임금의 성장률 비율; - 근로 시간 자금 사용. 기술 발전, 고정 및 운전 자본 사용을 특징으로하는 많은 지표가 있습니다. 생산 자산의 비용 효율성 지표에는 총 사회적 제품의 물질적 집약도가 포함됩니다. 생산 자산 자원 사용의 효율성 지표에는 고정 자산 단위당 생산된 국민 소득, 고정 자산 단위당 이윤, 운전자본의 순환 속도가 포함됩니다. 기술 진보의 효과는 생산 자산 총계의 증가 단위당 생산 국민 소득의 증가, 신기술 도입을 위한 자본 지출의 회수 기간이 특징입니다. 국가 규제에서 가장 중요한 것은 증권 시장의 상태에 대한 분석입니다. 증권 시장 지표는 주식, 채권 등과 같은 유형별로 계산됩니다. 증권 시장 지수는 주가의 역학을 결정하며 일별, 주별, 월별, 분기별, 반기별, 연간으로 계산할 수 있습니다. 증권 시장 지수를 사용하면 다양한 시장 부문의 가격 변동을 비교하고 현재 투자자에게 가장 수익성이 높은 부문에 대한 결론을 도출할 수 있습니다. 현대 경제의 조건에서 상품 및 서비스 가격의 역학 분석은 실질적으로 매우 중요합니다. 소비재 시장의 인플레이션 과정을 특징짓는 지표는 많은 경제적 문제를 해결하는 데 사용됩니다. 상품 가격의 역학을 평가하기 위해 소비자 물가 지수가 사용됩니다. 인플레이션 평가, 소득 색인화, 현재 생산 비용 결정에 도움이 됩니다. 지수 계산 방법은 많은 국가에서 동일하므로 국제 비교가 가능합니다. 또한 경제 프로세스의 주 규제를 위해 상품 및 서비스의 투자, 수출 및 수입을 고려하면서 주에서 생산 및 소비되는 전체 상품 세트에 대한 인플레이션 정도를 평가하는 디플레이터 지수가 사용됩니다. 국가의 산업 및 사회 생활의 다양한 측면은 인구의 생활 수준에 대한 통계 지표로 특징 지어집니다. 인구의 생활 수준에 대한 국가 규제의 임무는이 수준의 패턴과 추세를 연구하는 것입니다. 생활 수준 지표 시스템의 주요 섹션에는 인구 소득 지표, 인구 지출 및 소비 지표, 서비스 부문 지표, 근로 및 휴식 조건, 인구 통계 지표가 포함됩니다. 소득! 인구는 화폐 임금, 인구 예금, 인구의 실질 소득, 구조 및 역학이 특징입니다. 인구의 지출 및 소비 지표를 연구하면서 가계 예산, 식품 및 비 식품 재화 및 서비스 소비, 구조 및 역학을 고려합니다. 서비스 부문의 지표에는 무역 회전율, 주택 제공, 소비자 및 공동 서비스, 의료, 교육, 문화 지표 등이 포함됩니다. 근로 및 휴식 조건은 인구 고용, 근무일, 주, 휴일의 특징을 나타냅니다. . 인구 통계 지표에는 출생률, 사망률, 평균 기대 수명 등이 포함됩니다. 국가 규제의 가장 중요한 임무는 정확한 균형을 보장하고 경제의 다양한 부문, 경제 및 사회 영역의 발전을 위한 장기 계획의 개발 간의 불균형을 방지하는 것입니다. 사회의 사회 경제적 관계의 현재 상태, 경제 및 사회의 개별 요소 및 부문 발전의 추세, 단점 및 불균형에 대한 심층적이고 다양한 정보를 제공한다는 측면에서 이러한 작업의 수행을 보장하는 것은 통계입니다. 구체. 주제 10. 국민회계와 국민회계제도 10.1. 국가회계통계방법론 국가 회계의 대상은 국가의 경제입니다. 국가 회계의 주제는 거시 경제 지표 시스템과 이들로 구성된 국가 계정, 부문 간 대차 대조표 및 기타 표를 사용하여 국가 경제의 상태 및 발전에 대한 통계적 설명입니다. 이 맥락에서 "회계"라는 단어는 거시 경제 지표 시스템과 회계의 연결을 반영합니다. 이것은 국가 회계에서 회계의 기본 원칙의 사용을 설명합니다: 모든 지표의 가치 표현, 균형 방법, 이중 입력 방법, 경제 기능의 무제한 기간 가정. 국가 회계는 시장 경제, 그 메커니즘 및 제도에 중점을 둡니다. 국가 회계의 이론적 기초는 모든 형태의 소유권의 평등, 경쟁에 기반한 가격 형성의 시장 특성, 이윤에 대한 모든 사람들의 자연스러운 욕구에 대한 인식입니다. 국가 회계는 국가가 적극적으로 규제하는 시장 경제를 기반으로 합니다. 국민 계정 시스템의 국가는 인구에게 비 시장 (무료) 서비스를 제공하고 경제 및 사회 정의의 원칙에 따라 소득을 분배 및 재분배하는 독립 부문으로 대표됩니다. 복지 국가에 중점을 둔 국민 계정 시스템(SNA)은 국가의 사회 정책을 "개방"하여 소득 재분배의 현금 흐름을 보여줍니다. 경제 관계. 그러한 경제는 상품과 서비스뿐만 아니라 노동, 자본, 기업가 정신, 투자, 신기술 등 생산 요소에 대해서도 국경을 넘어 자유롭게 이동할 수 있다는 특징이 있습니다. 국가 회계는 시장 경제로의 전환이라는 국가 조건에 맞게 조정된 SNA의 국제 표준을 기반으로 하고 그에 따라 만들어진 실질적으로 작동하는 시스템입니다. 국민 계정 시스템 (SNA)은 국가 시장 경제에 해당하는 회계로, 거시적 수준에서 결과를 특징 짓는 특정 계정 및 대차 대조표 형태로 구축 된 상호 관련된 통계 지표 시스템으로 표현됩니다. 경제 활동, 경제 구조 및 연결 고리의 가장 중요한 상호 연결. 국가 회계 시스템은 산업 및 기관 부문별로 그룹화되는 활동 및 기관 단위의 두 가지 유형의 분류 단위를 사용합니다. 주요 기관 부문: - 급여, 재산 소득, 생산 활동 소득, 국가로부터의 이전 등을 지출 자금 조달의 원천으로 하는 가구; - 가정에 봉사하는 비영리 단체. 여기에는 노동 조합, 종교 단체, 정당, 사회 및 정치 운동, 회비와 자발적 기부금으로 운영되는 공공 단체가 포함됩니다. 그들은 가정의 특별한 필요를 충족시키는 서비스를 제공합니다. - 주 당국 및 지방 자치 정부를 포함한 주 기관, 주 예산 외 기금. 예산으로 자금을 조달하여 제품 또는 서비스를 생산하는 기업 무료 또는 경제적으로 하찮은 가격으로 소비자에게 이전됩니다. - 금융 기관에는 중앙 은행, 상업 은행, 비국가 보험 기금, 투자 회사 등이 포함됩니다. 주로 금융 중개를 포함하는 금융 서비스를 생산하며, 그 자금의 출처는 제공된 서비스의 수익금으로 경쟁 시장에서 판매됩니다. - 비금융 기업 - 시장에서 경제적으로 중요한 가격으로 판매되는 제품 및 비금융 서비스를 생산하고 받은 이익에서 비용을 충당하는 기관 단위. "나머지 세계"라는 용어는 국제 관계를 설명하는 데 사용됩니다. 경제 활동의 유형은 USREO에 기업, 기관을 입력하여 OKVED 분류기에 의해 결정됩니다. 국민회계는 경제를 자산과 부채의 시스템으로 연구합니다. 경제적 자산은 다음과 같은 특징이 있습니다. - 경제 주체는 자산에 대한 소유권을 가지고 있습니다. - 이 재산권의 실현은 경제 주체가 소득 또는 기타 경제적 혜택을 받거나 받기를 희망하는 것을 허용합니다. - 자산에 가치 평가, 즉 화폐 측정이 있습니다. 자산은 금융과 비금융으로 나뉩니다. 금융 자산에는 가치를 결정하는 물질적 기질이 없습니다. 한 실체의 금융자산은 다른 실체의 금융부채와 상반된다. 금융 자산에는 현금 및 예금, 대출, 유가 증권(어음, 채권), 주식, 보험 증권이 포함됩니다. 비금융 자산1은 유형과 무형의 두 그룹으로 나뉩니다. 생산된 것과 생산되지 않은 것. 위의 모든 국가 회계 개념은 지표와 지표에 의해 형성된 국가 계정으로 설명됩니다. 지표와 국민계정은 상호 연결되고 보완되는 시스템을 형성하며 일반적으로 국가 경제를 정확하고 포괄적으로 설명합니다. 국민 계정 시스템의 주요 계정은 다음과 같습니다. - 소득 창출 계정(표 10.1) 표 10.1 소득 창출 계정 
- 소득분배계정(표 10.2) 표 10.2 소득 분배 계정 
- 소득 사용에 대한 설명(표 10.3) 표 10.3 소득 사용 계정 
- 자본 비용 계정(표 10.4). 표 10.4 자본 비용 계정 
국민 계정 지표의 형성 순서는 재생산주기의 단계 순서에 해당합니다. 10.2. 거시적 수준의 사회경제적 지표 통계 거시적 수준에서 국가의 삶을 특징 짓는 많은 사회 경제적 지표가 있습니다. 여기에는 국내 총생산, 총 또는 XNUMX인당, 국민 총소득, 경제 성장률, 국가 부, 공공 부채, 루블 대비 미국 달러(러시아 연방 중앙 은행에서 설정), 등록된 실업자 수 등 위의 모든 사회 경제적 지표 중 가장 중요한 것은 국가의 국내 총생산 지표이며 여러 가지 방법으로 계산할 수 있습니다 (생산 단계에 따라 다름). - 생산 방식(부가가치 생산 단계에서) - GDP의 가치를 총 생산량과 중간 소비량의 차이 또는 경제의 모든 산업 및 부문의 총 부가가치의 합으로 결정 . 이것이 생산된 GDP가 계산되는 방법입니다. - 분배 방법 (제조 제품의 유통 단계에서 생산) - 노동 소득 (임금 및 발생액, 수수료, 현물 소득, 수수료, 등), 재산 소득(이익, 임대료, 배당금 등), 혼합 소득(프리랜서 소득, 농업 소득, 자영업 등). 이 방법은 분배된 GDP를 계산합니다. - 최종 사용 방법(비용 측면에서) - 이를 사용하는 모든 경제 주체(기업, 가계, 외국인, 주)의 비용을 합산한 결과, 즉 GDP = P + I + W + E, 어디서 P - 내구재에 대한 가계의 개인 소비자 지출; I - 총 투자(주택을 제외한 신규 장비 및 건설 구매에 대한 기업 투자); Z - 정부의 상품 및 서비스 구매(교육, 의료, 군대 등을 위한 지출); E - 순수출(국가의 수출과 수입의 차이). GDP는 요소 가격과 시장 가격 모두에서 계산할 수 있습니다. 요소 가격은 상품 및 서비스 생성을 위한 모든 생산 요소의 비용에 의해 결정됩니다. 즉, 이는 생산 비용과 이윤으로 구성된 생산자의 가격입니다. 시장 가격은 요소 가격과 간접세(부가가치세(VAT), 소비세, 관세 등)의 합계에서 제품, 수입, 손해 배상 등에 대한 국가 및 기타 출처의 무상 영수증을 포함하는 보조금을 뺀 것입니다. . 러시아에서 GDP와 국민총생산(GNP)은 현재 생산 방법에 의해 계산됩니다. 즉, GDP는 경제의 산업 및 부문의 총 부가가치, 제품에 대한 순 세금(보조금 제외)의 합계입니다. 그 다음으로 중요한 지표는 국민총생산에서 감가상각비를 뺀 국민소득이다. 동시에 순국민소득(NNI)은 국민소득과 해외 순이전(인도적 지원, 선물, 기부 등)에서 해외 순이전을 뺀 금액으로 계산된다. 국민총생산(GNP)은 다른 국가에 거주하더라도 해당 국가의 시민이 소유한 생산 요소에 의해 생산된 최종 제품의 가치를 나타냅니다. GNP = GDP + NFD, 여기서 NFD는 해외로부터의 순 요소 소득, 즉 해외에서 주어진 국가의 시민이받는 소득과이 국가의 영토에서받는 외국인의 소득의 차이입니다. 국가의 사회 경제적 상황을 분석하려면 다음 지표를 그룹화해야합니다.
필요한 경우 다른 기준에 따라 그룹화할 수도 있습니다. 경제 활동 결과 지표의 역학은 공식에 따라 해당 물리적 부피 지수를 계산하여 연구됩니다 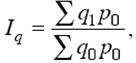
여기서 q0P0은 기준 기간의 총생산, 국내총생산, 국민소득의 실제 가치입니다. q1P0 - 기준 기간의 가격에서 보고 기간의 동일한 지표의 비용. 시장 경제에서는 상품과 서비스의 가격이 지속적으로 상승합니다. 지수 계산에서 발생하는 주요 문제는보고 기간의 비용 지표를 기준 기간의 가격으로 재평가하는 것입니다. 인플레이션은 불균등한 과정이기 때문에 각 유형의 상품 및 서비스 가격을 기준 기간과 비교 가능한 가격으로 다시 계산하는 것은 실제로 불가능합니다. 통계 이론에서 국내 총생산과 국민 소득의 지표를 기준 기간의 비교 가능한 가격으로 변환하는 세 가지 주요 방법이 있습니다. 기준 기간의 가격으로 상품 및 서비스 생산량에 대한 직접적인 평가를 사용합니다. 관련 지표를 사용하여 국내총생산 및 국민소득의 구성요소를 재평가함 소비자 물가 지수를 기반으로합니다. 첫 번째 방법은 계산하기가 매우 어렵습니다. 계획된 관리 시스템에서 가장 자주 사용되었습니다. 그 본질은 출력의 물리적 볼륨(물리적 측면에서)에 기본 기간의 해당 가격을 곱한다는 사실에 있습니다. 이 방법을 사용하면 재화 및 용역의 가격 변동의 역학을 자세히 고려할 수 있지만 기본 가격을 정기적으로 변경해야 하고 해당 국가의 재화 및 용역의 비교 가능성 문제가 있다는 단점이 있습니다. 품질의 변화로 인해 동일한 이름(생산 연도가 다름)으로 인해 복합 가격 지수를 결정할 대표 제품 세트를 찾아야 하며, 이 또한 매우 불편하고 문제가 있습니다. 두 번째 방법은 첫 번째 방법만큼 정확하고 복잡하지 않으며 국내 총생산과 국민 소득의 요소를 적절한 지수로 나누어 비교 가능한 가격으로 변환한다는 사실로 구성됩니다. 기계 및 장비를 재평가 할 때 사용됩니다 - 기계 및 장비 등의 가격 지수. 이 재계산 방법은 해당 가격 지수를 계산하기 위해 상당히 넓은 기반이 필요합니다. 소비자 물가 지수를 기반으로 구축 된 나열된 방법 중 세 번째는 가장 간단하고 완전히 정확하지는 않지만 비교 가능한 가격을 계산하는 데 편리하며 대부분의 선진국에서 사용됩니다. 그러나이 방법은 공공 서비스 및 자본 투자, 수출입 운영, 경제의 다른 부문의 자본재 가격 변화의 역학을 고려하지 않습니다. 10.3. 국부 통계 경제통계에서 중요한 부분은 국부통계를 다루는 부분이다. 국부는 모든 이전 세대의 노동에 의해 생성된 축적된 유형 및 무형 자산의 집합으로, 국가 또는 그 거주자가 소유하고 이 국가의 경제 영역 및 외부(국유 재산)에 위치하며 탐사 및 참여 천연 및 기타 자원의 경제적 순환에서 [2]. 국부 통계는 국부의 주요 흐름, 경제의 개별 부문의 투자 활동, 정도를 결정할 수 있는 기반으로 일반적으로 모든 구성 요소 및 각 범주에서 개별적으로 모든 구성 요소의 데이터를 수집하고 분석하는 데 도움이 됩니다. 금융 자산의 유동성 등. 획득한 국부 통계 데이터는 국가 전체에 대한 경제적 평가, 자산 상태 및 국가의 경제적 잠재력이 국제 기준을 충족하는 방법을 제공합니다. 통계 데이터를 고려하고 분석할 때 국가의 추가 발전을 위한 잠재적이고 수용 가능한 기회를 결정할 수 있습니다. 국부의 구성 요소: 천연 자원(토지, 광물, 에너지 자원, 삼림 및 야생 동물)은 회전율에 포함되고 관련됩니다. 천연자원의 특성으로 재생산 불가능한 혜택으로 구분할 수 있습니다. 천연 자원에 대한 통계 데이터를 얻을 때 다음을 수행할 수 있습니다. - 천연 자원의 효율적인 사용에 대한 지표 시스템을 개발합니다. - 환경 보호 조치의 작업을 분석하고 작업의 효율성을 평가합니다. - 환경 목적에 필요한 재정 자원의 양을 결정합니다. - 인적 요소가 자연 환경에 미치는 영향의 정도와 환경이 인구의 생활 수준에 미치는 영향을 분석합니다. - 축적된 노동의 결과로 얻은 물질적 자원. 물질적 자원은 언제든지 생산될 수 있으므로 재생산 가능한 상품입니다. 국유 재산 - 생산 과정에서 형성되며 다음이 포함됩니다. - 고정 자산(건물, 구조물, 차량, 기계, 장비 등). 고정 자산의 통계 데이터는 일반적인 상태, 고정 자산의 발전 전망을 전국 및 각 산업에서 개별적으로 특성화합니다. - 운전 자본(생산 재고 - 원자재, 자재, 연료, 예비 부품, 진행 중인 작업, 완제품, 자재 매장량 등); - 사유 재산. 국가 자산 통계는 경제 발전 수준을 평가하는 데 사용됩니다. - 축적된 과학적, 기술적 잠재력 - 지적 잠재력. 따라서 국부에는 국가의 모든 생산 및 비 생산 자산, 주식, 준비금, 개인 및 공공 재산의 가치가 포함됩니다. 경우에 따라 국부에는 근로자의 과학 및 기술 수준과 경험이 포함됩니다. 국가의 부는 소비재를 포함한 과거 노동의 축적된 산물과 경제적 회전율에 관련된 천연 자원으로 구성됩니다. 국부의 일부로 주식과 준비금은 결정 장소와 보관 기간에 따라 별도로 계산됩니다. 국가의 금 매장량과 국가 방위에 필요한 매장량도 별도로 고려됩니다. 국부에 대한 계산은 현재 존재하는 현재 및 비교 가능한 가격으로 수행됩니다. 국부의 통계 지표는 국제적 규모로 국가의 발전 수준을 보여줍니다. 10.4. 지역 전체에 대한 균형 구축 대차 대조표의 구성과 러시아 지역의 유형학, 사회 경제적 발전의 다양한 지표 측면에서의 차별화 분석은 빠르게 발전하는 러시아 지역 경제의 주요 연구 영역 중 하나가 되었습니다. 같은 용어 - "지역"-은 활동의 규모, 발전 방향, 정치적 성향 측면에서 완전히 비교할 수 없는 사회 경제적 시스템을 설명하므로 유형의 구성은 지역 경제 분석을 위한 출발점, 조건 역할을 합니다. 시스템을 구축하고 지역 전체에 대한 균형을 구축합니다. 러시아 지역의 차별화를 연구 할 때 우선 지역의 사회 경제적 상황의 특성을 결정하는 요소를 선택하는 것이 필요합니다. 지역 수준의 지방 정부는 소비에트 이후 기간에만 지역 수준의 경제 개발 계획 및 프로그램 개발에 착수했음을 강조해야 합니다. 사실 그들은 이 분야에 대한 전통도, 기술도, 경험도 없었습니다. 소비에트의 중앙집권화된 경제정치체제의 조건하에서 지방정부는 중앙집권화된 정치경제체제의 일부였다. 중앙집권적 경제계획체제에서 지방정부는 중앙부처, 중앙예하기업, 정당구조에 전적으로 의존하였다. 지방 정부의 책임에는 중앙에서 수립된 표준에 따라 사회 경제적 기반 시설을 제공하는 것이 포함되었으며 지역 균형을 구축하는 작업은 부차적이었습니다. 지역의 경제 상황을 분석하는 문제의 공식화는 지방 정부가 지역 수준에서 경제 개발 과정에 적극적으로 영향을 미칠 수있는 기회를 얻은 소비에트 이후 개발 조건에서만 관련이 있습니다. 일반적으로 지역 균형의 개발은 연방 수준에서 개발된 사회 정책(연금 정책, 고용 프로그램, 주택 프로그램, 의료, 교육, 사회 보호 분야의 연방 표준)의 지역 조건에 효과적으로 적응하기 위한 조건으로 작용합니다. 인구). 사회 정책 구현 방법 선택에 중점을 둔 지역 사회 경제적 상황의 균형을 구축하기위한 지표 선택은 다소 어려운 작업입니다. 지역 총생산과 같은 지표의 사용은 계산 방법론의 개선과 국가 계정 지표 시스템에서 지역의 경제 활동을 설명하는 시스템 개발을 의미합니다. 지역 수준에서 이 지표를 사용할 때 관계(GRP), XNUMX인당 생산량 및 웰빙 수준의 이론적 및 방법론적 측면을 연구할 필요가 있습니다. 대부분의 연방 정부의 경우 국민 계정 시스템(SNA)과 호환되는 지역 경제 계정 시스템을 보유하는 것이 중요합니다. 일반적으로 지역의 경제 계정은 SNA에 필수적인 부분으로 포함됩니다. 현재까지 SNA는 지역 경제를 포함한 실물 경제의 거시 경제 분석을 위해 합리적이고 일반적으로 인정되는 유일한 도구입니다. 지역 계정의 중심 지표는 해당 지역에서 생산된 국내 총생산입니다. 러시아에서이 지표 (지역 총생산 - GRP)는 러시아 연방 주제 수준에서만 계산됩니다. 계산을 위한 방법론적 기초가 개발 중입니다. 지역 경제 계정 시스템의 개발 및 해당 계정 구성에 대한 공식 권장 사항은 발표되지 않았습니다. 러시아 경제 발전의 지역적 차이에 대한 연구는 결과 지표 인 GRP 하나만 기반으로 수행 할 수 없다는 것이 분명합니다. 실제 차이는 지역균형을 구축하고 지역별 경제과정을 분석한 결과 추정할 수 있다. 지역의 경제 계정의 산 시스템. 지역의 경제 계정을 개발할 때 지역의 일반적인 거시 경제 상황, 실물 부문의 상태, 예산 및 금융 시스템을 반영하는 주요 지표 시스템이 선택됩니다. 지역균형을 구축하기 위해 다음과 같은 지표체계를 제안할 수 있다. 거시 지표 및 실제 부문 : GRP / XNUMX 인당 (천 루블); 산업 생산량 / XNUMX 인당 (천 루블); 농업 생산량 / XNUMX인당 (천 루블); 전체 인구에서 도시 인구의 비율(%); 고정 자본 / XNUMX 인당 투자 (천 루블); 외국인 투자/XNUMX인당(USD); 수출량 / XNUMX 인당 (천 루블); 소매 무역 회전율 / XNUMX인당 (천 루블); 소비자 물가 지수(% 단위, 해당 연도의 XNUMX월/XNUMX월) 현금 소득 / XNUMX 인당 (천 루블); 화폐 소득의 구매력(%); 일반 실업 수준(%); 빈곤율(%). 재정 및 예산 시스템: GRP 참조 예산 적자(%); 예산 수입에서 세금 수입의 비율(%); 주요 경제 활동 유형에 대한 이익 비율(GRP 참조)(%) 수익성이 없는 기업의 몫(%); 연체 미지급금 비율(GRP 참조)(%) 기업 10개당 운영하는 신용기관 수 GRP와 관련된 신용 투자 비율(%); 총 대출 금액에서 대출에 대한 연체 부채 비율(%); GRP(%)로 표시되는 기업의 경상 계정 및 결제 계정 몫; GRP에 따른 가계 예금(%); 통화 구매 / 000 인당 (천 루블); 통화 판매 / XNUMX 인당 (천 루블). 제안 된 지표 시스템은 경제의 가장 중요한 결과와 비율을 특징 짓는 거시 경제 지표로 표현되는 통계 정보의 주요 흐름을 수집, 설명 및 연결하기위한 합의 된 체계입니다. 지역 개발. 그들의 도움으로 지역 균형은 지역의 물질적 수입과 혜택의 자원과 사용을 보여주는 일련의 테이블 형태로 나타낼 수 있습니다. 보조 테이블을 사용하면 특정 기준에 따라 개별 집계 지표를 구체화할 수 있습니다. 그들은 연방 예산 초안의 주요 매개 변수의 일부인 예산 자금 조달 표준 개발, 예산 간 균등화의 목적으로 사용됩니다. 주제 11. 인구, 노동 및 생활 기준의 통계 11.1. 인구, 고용 및 실업 통계 경제 활동 인구(노동력)는 재화와 서비스의 생산에 필요한 노동력의 공급을 제공하는 인구의 일부입니다. 경제활동인구는 취업자와 실업자로 구분되며 조사대상에 따라 다양하다. 전체 인구에서 경제 활동 인구의 비율은 인구의 경제 활동 수준입니다. 고용된 사람에는 18세 이상의 여성 및 남성과 XNUMX세 미만의 사람이 포함되며, 이들은 검토 기간 동안 다음과 같습니다. - 직위 또는 직위에 대한 수입을 받는 시기에 관계없이 독립적으로 또는 개별 시민을 위해 보수를 받는 정규직 또는 시간제 고용 및 기타 소득 창출 업무를 수행했습니다. 고용서비스를 통해 제공받은 유급 공공근로를 수행하는 등록 실업자 및 교육 기관의 지시에 따라 유급 농업 근로를 수행하는 학생 및 학생은 취업자 구성에 포함되지 않습니다. - 질병이나 부상으로 인해 일시적으로 결근; 환자 간호; 연차 또는 휴가; 보상 휴가 또는 휴가; 초과 근무 또는 공휴일(주말) 근무에 대한 보상; 특별한 일정에 따라 일하십시오. 예비 중 (운송에서 일할 때); 임신, 출산 및 육아에 대한 법정 휴가; 훈련, 직장 밖에서의 재훈련; 학업 휴가; 무급 또는 관리의 주도로 유급 휴가; 파업, 기타 유사한 사유 - 가족 사업에서 무급으로 일했습니다. 실업자에는 검토 기간 동안 16세 이상인 사람이 포함됩니다. - 직업이 없었습니다(유익한 직업). - 구직, 즉 주 또는 상업 고용 서비스에 지원, 언론에 광고 사용 또는 게재, 기업(고용주) 관리에 직접 지원, 인맥을 사용하거나 자신의 사업을 조직하기 위한 조치를 취한 경우 일할 준비가되었습니다. 실업자를 언급할 때 세 가지 기준을 동시에 충족해야 합니다. 실업자에는 고용 서비스 방향으로 공부하는 사람도 포함됩니다. 학생, 학생, 연금 수급자 및 장애가 있는 사람은 나열된 기준에 따라 구직 중이었고 시작할 준비가 된 경우 실업자로 간주됩니다. 실업자는 고용되지 않은 사람, 구직자로 고용 서비스에 등록된 사람 또는 실업자로 인정된 사람을 포함합니다. 경제활동인구 중 실업자가 차지하는 비율이 실업률이다. 실업 기간은 개인이 어떤 수단을 사용하여 일자리를 찾는 기간(구직이 시작된 순간부터 취업의 순간까지)입니다. 실업자에 대한 정보는 절대 지표와 상대 지표로 특징지을 수 있습니다. 절대 실업자 수는 매월 초에 일시적인 지표입니다. 한 달 동안 역학이 있습니다. 얼마나 많은 실업자가 등록 취소, 고용, 조기 퇴직을 위해 발급, 직업 훈련을 위해 파견, 고용 직업 훈련을 마친 후. 실업자의 구성은 교육 수준, 성별, 거주지로 특징지을 수 있습니다. 상대적 지표에는 고용 서비스에 등록된 전체 실업자 수 중 실업자가 차지하는 비율과 실업 수당을 받는 비율이 포함됩니다. 실업자 및 고용자의 평균 수는 월, 분기, 연도별로 계산됩니다. 실업률은 다음 공식을 사용하여 계산됩니다. 
이 계수는 유급 노동에 대한 수요 또는 노동 수요 초과 공급에 대한 불만의 정도를 반영합니다. 일반(표준)실업률 외에 청년실업자 비율, 장기간 실업상태에 있는 여성 등 다양한 측면을 특징짓는 다른 지표들이 사용된다. 특정 기간, 이 경우 실업자 및 고용자 수의 평균 월간(연간) 지표. 또한 표준 계수는 특정 날짜에 결정될 수 있습니다. 이를 위해 해당 날짜의 실업자 및 고용자 수에 대한 절대 데이터가 사용됩니다. 실업률을 계산하는보다 상세하고 정교한 방법이있어 수요에 대한 노동 공급의 실제 초과를 설정할 수 있습니다. 여기에는 특히 전일제 근로에 해당하는 실업률이 포함됩니다. 고용을 수량화하기 위해 통계는 절대 및 상대적 특수 지표를 사용합니다. 절대 지표는 고용 인구가 생산 과정의 주요 요소이기 때문에 경제 잠재력, 국가 경제 발전 가능성을 반영합니다. 절대 지표에는 국가 경제에 고용된 사람의 수가 포함됩니다. 국가 경제에 고용된 사람들의 분포; 경주- 경제 분야, 성별, 연령, 교육 수준에 따른 직원 분포; 경제의 다양한 부문에 고용된 노동 연령의 사람들의 수 등 상대 지표는 전체 인구와 개별 연령 그룹의 경제 활동에 대한 참여 정도를 나타냅니다. 이들은 인구의 고용률, 노동 자원의 고용률, 생산 가능 인구의 고용률, 생산 가능 연령 인구의 고용률과 같은 지표입니다. 인구의 고용률은 다음 공식에 의해 결정됩니다. Kzn = (Szn / S) 1000, 여기서 Szn - 고용된 사람의 수; S는 전체 인구입니다. 노동 자원의 추가 지불 계수는 다음 공식에 의해 결정됩니다. 
여기서 TR은 노동 자원의 수입니다. 이 계수는 노동 연령 개념과 관련하여 더 좁게 고려할 수 있습니다. Kzntv \u1000d (Szn / Stv) XNUMX, 여기서 Stv는 생산 가능 인구입니다. 모든 생산가능인구가 건강상의 이유로 건강하지 않다는 사실 때문에 생산가능인구가 경제에 참여하는 정도를 결정하는 것은 매우 중요합니다. 이를 위해 고용인구의 고용률은 전체 고용인구에 대한 고용인구의 비율로 계산되어야 한다. 이 계수가 1에 가까울수록 노동 활동에 유능한 인구가 더 많이 관여합니다. 1에서 빼면 경제의 어느 부문에도 고용되지 않은 생산 가능 인구의 비율을 얻습니다. 퇴직 연령 인구의 노동 활동 참여 정도를 측정하는 것이 좋습니다. 이를 위해서는 퇴직연령 근로자 수를 전체 근로자 수로 나누어야 합니다. 이 비율은 퇴직 연령의 사람들이 노동 활동에 종사하는 비율을 보여줍니다. 11.2. 노동 생산성 통계 노동 생산성 - 근로자 XNUMX인당 생산량. 노동 생산성을 측정하기 위해 생산과 노동 집약도라는 두 가지 주요 지표가 사용됩니다. 노동 집약도 - 생산 단위 생산을 위한 노동 시간 비용. 산출량은 평균 노동자 XNUMX명이 단위 시간당 생산한 산출량입니다. 출력을 결정하는 방법은 다음과 같습니다. - 자연(생산량은 자연 단위로 측정됨) - 비용; - 노동, 또는 노동 시간을 정상화하는 방법. 통계에는 노동 생산성에 대한 두 가지 연구 영역이 있습니다. 첫 번째 방향은 활발한 노동의 생산성만을 결정합니다. 즉, 특정 생산량의 생산에 노동자가 소비한 직접 노동만을 고려합니다. 두 번째 방향은 사회적 노동의 생산성이라고 불리는 국가적 규모의 노동 생산성을 결정합니다. 연구에 통계를 사용하고 노동 생산성을 결정하면 다음 문제를 해결할 수 있습니다. - 노동 생산성의 정도와 역학을 특징 짓는 주요 지표 찾기; - 노동 생산성의 변화가 제품(작업, 서비스)의 양과 노동 시간 비용의 변화에 미치는 영향에 대한 연구; - 노동 생산성의 정도와 역학에 대한 다양한 상황의 영향 분석. 노동 생산성 통계를 통해 다음을 식별할 수 있습니다. 국가의 지원이 필요한 생산 부문; 국가에서 생산을 개발하기 위해 사용할 재정 자원을 할당하는 방법. 노동 생산성의 통계 데이터를 분석 할 때 생산 효율성의 주요 지표를 결정할 수 있습니다. 일반 지표: - 자원 비용 단위당 순 제품 생산 - 총 비용의 단위당 이익; - 시장성 있는 제품의 루블당 비용; - 생산의 수익성; - 생산 강화로 인한 성장 몫; - 생산 단위 사용의 국가 경제 효과; 노동 효율성 지표: - 노동 생산성의 성장률; - 노동 생산성 증가로 인한 생산 증가율; - 근로자의 절대적 및 상대적 석방 - 유용한 노동 시간 기금의 사용 계수 (노동 생산성과 생산 조직 모두에 따라 다름) - 생산 단위의 노동 집약도 - 발전에 반비례하는 지표; - 생산 단위의 임금 집약도 생산 자산 사용에 대한 성과 지표: - 자산 수익률; - 펀드의 활성 부분의 자산 수익률; - 고정 자산의 수익성; - 생산의 자본 집약도; - 가장 중요한 유형의 원자재 및 장비 사용 계수; 재정 자원 사용의 효율성 지표 : - 운전 자본의 회전율; - 운전자본의 수익성; - 운전 자본의 상대적 방출; - 용량 단위 또는 출력 단위당 특정 자본 투자 - 자본 투자의 수익성; - 자본 투자의 회수 기간; 등. 노동 생산성은 노동 자원 사용의 효율성을 나타내는 지표입니다. 노동의 지표는 생산성입니다. 노동 생산성의 증가는 경제적, 사회적으로 매우 중요하며 미시적 수준과 거시적 수준(국가적 규모)에서 계산해야 합니다. 이러한 관점에서 노동 생산성을 높이는 것은 다음을 의미합니다. - 국가 생산, 소득의 성장; - 자본 축적 및 자본 소비의 성장(확대 재생산을 위해) - 국가의 생활 수준을 높이고 사회 문제를 해결합니다. - 국가의 발전, 경제 성장, 국가의 힘 강화. 기업 내 노동 생산성의 성장(미시적 수준)은 다음을 가능하게 합니다. - 제품의 생산 및 판매 비용을 줄입니다(노동 생산성의 증가가 임금을 초과하는 경우). - 이익 증가 (기업 직원의 임금 인상) - 기술적인 재장비를 수행하기 위해; - 경쟁력을 높이고 재정적 안정성을 확보합니다. 통계 데이터를 연구할 때 생산 효율성의 주요 요인을 식별할 수 있습니다. - 효율성 증가의 주요 원인: 노동 집약도, 물질 집약도, 생산 자본 집약도 감소 천연 자원의 합리적인 사용, 시간 절약 및 제품 품질 향상; - 생산의 발전 및 개선의 주요 방향 : 과학 기술 진보의 가속화, 생산 기술 및 경제 수준의 증가, 생산 구조의 개선, 새로운 조직 계획의 도입, 관리 방법의 개선; - 생산 관리 시스템의 구현 수준. 영향의 성격에 따라 내부 요인과 외부 요인이 구별됩니다. 내부 요인에는 새로운 유형의 제품 개발, 기계화, 생산 자동화, 첨단 기술 도입이 포함됩니다. 외부 요인은 생산, 국가, 경제 및 사회 정책의 부문 구조 개선, 시장 관계 형성, 시장 인프라 개발을 반영합니다. 11.3. 인구의 수준과 삶의 질에 대한 통계 인구의 생활 수준은 사회 경제적 범주입니다. 경제 문헌에는 이 개념에 대한 단일 정의가 없지만 여전히 생활에 필요한 물질적 재화를 해당 국가의 주민들에게 제공하는 것으로 정의할 수 있습니다. 인구의 생활 수준을 특성화하는 단일 일반화 지표가 없기 때문에 이 범주의 다양한 측면을 반영하고 다음 주요 블록으로 그룹화하여 분석을 위해 많은 통계 지표가 계산됩니다[3]. - 인구 소득 지표; - 인구에 의한 물질적 상품 및 서비스의 비용 및 소비 지표; - 저축; -누적 재산 및 주택 공급에 대한 지표; - 인구 소득의 차별화 지표, 빈곤 수준 및 한계; - 사회 인구 통계학적 특성; - 인구의 생활 수준에 대한 일반화된 평가. 인구의 생활수준에 대한 통계적 분석 및 평가를 위해 국내총생산(GDP), 국민소득 및 XNUMX인당 실질소득, 주택, 무역액 등 다양한 지표가 사용된다. , 그러나 출생 및 사망률, 국가 인구의 평균 기대 수명 등과 같은 생활 인구 지표의 수준에 여전히 영향을 미칩니다. 인구의 삶의 질은 수준에 직접적으로 의존합니다. 인구의 생활 수준이 증가함에 따라 인구의 소득이 증가하므로 인구에 물질적 재화 제공이 증가하고 삶의 질도 향상됩니다. 넓은 의미의 "삶의 질"은 다양한 필요와 관심 측면에서 인구의 삶에 대한 만족도를 나타냅니다. 이 개념은 경제 범주로서의 생활 수준, 근로 및 휴식 조건, 주거 조건, 사회 보장 및 보장, 법 집행 및 개인 권리 존중, 자연 및 기후 조건, 환경 보전 지표, 가용성의 특성 및 지표를 다룹니다. 자유 시간과 그것을 잘 활용하는 능력, 마지막으로 주관적인 평화, 편안함, 안정감[4] . 오늘날 통계 데이터가 없어도 우리 나라의 전체 경제를 시장 형태의 관리로 전환하는 것은 주로 인구 통계 학적 상황의 악화와 사회 영역을 희생시키면서 수행된다는 것이 분명합니다. 대다수 인구의 수준과 삶의 질 저하. 점점 더 많은 사람들이 건강을 잃고 있으며 출생률과 같은 국가의 주요 지표가 감소하고 기대 수명이 급격히 감소하고 있지만 가장 중요한 것은 러시아 인구가 고령화되고 노동력이 함께한다는 것입니다. 인구의 삶의 질과 수준은 필요를 충족시키는 사람들의 능력에 직접적으로 의존하며, 아시다시피 지속적인 기본 요구를 충족시키기 위해서는 일정한 소득이 필요합니다. 러시아 연방 인구의 주요 수입은 임금입니다. 급여는 노동 활동 과정에서 직원이 받는 소득의 구성 요소입니다. 임금 외에도 인구의 소득 수준과 삶의 질은 사회 보장, 물질적, 영적 상품 및 서비스의 가용성, 국가 인구의 주요 대중 교육 수준 등에 달려 있습니다. 인구의 수준과 삶의 질에 대한 연구에서 통계를 사용하면 많은 문제를 해결할 수 있습니다. 그 중 주요 문제는 개선을 위해 인구의 수준과 삶의 질에 대한 통계 데이터를 얻는 것입니다. 인구생활수준통계의 업무는 다음과 같다. - 인구의 삶의 수준과 질을 객관적이고 안정적이며 종합적으로 특성화하는 지표 시스템의 개발 - 인구의 삶의 질과 수준의 역학에 대한 통계 분석; - 인구의 삶의 질과 수준의 변화에 영향을 미치는 상황 식별; - 인구의 삶의 질과 수준의 주요 경향 및 변화 패턴의 결정; - 지역별 인구의 수준과 삶의 질 지표의 격차 분석; - 확립 된 소비 규범과 비교하여 물질적 자원 및 서비스에 대한 국가 거주자의 요구 만족 수준 결정; - 인구의 삶의 질과 수준에 대한 통계 정보 수집을 위한 소스 시스템의 개선; - 상호 연결될 인구의 수준과 삶의 질 지표 결정. 후자의 문제를 해결하기 위해 1992년 경제 정세 및 예측 센터는 인구 생활 수준의 기본 지표 시스템을 제안했습니다[5]. - 일반 지표; - 인구의 소득; - 인구의 소비 및 지출; - 인구의 금전적 절약; - 축적된 재산 및 주택; - 인구의 사회적 분화; - 인구의 저소득층. 11.4. 인구에 의한 재화 및 서비스의 소득 및 소비 통계 아시다시피, 인구의 소득 금액은 전적으로 재화와 서비스의 소비에 달려 있으며 그 반대의 경우도 마찬가지입니다. 사회 통계의 중요한 임무는 가계 예산에 대한 체계적인 표본 연구의 자료를 기반으로 인구 소비 구조를 결정하는 것입니다. 일반적으로이 구조는 인구의 소비자 지출 구조에 의해 결정됩니다. 이러한 비용의 일부로 다음과 같은 비용 영역이 구분됩니다. 음식, 때로는 알코올 음료, 비식품 제품 및 서비스 지불의 가능한 분리가 있습니다. 인구에 의한 재화와 서비스의 소득과 소비는 인구의 생활 수준 분석의 주요 특성 중 하나입니다. 지표로서 생활수준은 XNUMX인당 또는 가족당 금전적 소득으로 계산된다. 소득이 증가하면 재화와 서비스의 소비가 증가하므로 소비되는 재화와 서비스의 품질이 향상됩니다. 통계는 국가의 영토, 경제 부문, 가구 유형 및 인구의 사회 집단의 맥락뿐만 아니라 전체 인구에 대한 소득의 양과 구성, 구조, 역학을 연구합니다. 재화와 서비스의 소비가 감소하면 소득에주의를 기울여야합니다. 소득이 감소하면 인구의 구매력이 감소하고 결과적으로 지출이 감소합니다. 재화와 서비스를 구매하기 위해 지출한 비용을 인구의 소비자 지출이라고 합니다. 통계는 소비자 지출의 수준, 정도, 역학 및 구조를 연구합니다. 인구의 수입과 지출에 관한 통계는 경제 전반과 생활 수준을 분석하고 사회 및 조세 정책을 개발하며 내부 준비금을 동원하여 투자 프로세스를 확장할 가능성을 평가하기 위한 정보 기반을 제공합니다. 통계가 가장 정확하려면 계산할 때 소득 구조를 알아야 합니다. 인구의 소득 구조는 다음과 같이 구성됩니다. 요소 소득: - 샐러리; - 기업 활동으로 인한 소득; - 재산 소득; 이전 지불 - 모든 사회 연금, 근로가 아닌 수혜금. 인구의 총소득을 더하고 지불금을 이전하면 인구의 총소득이 됩니다. 이러한 유형의 소득에서 인구는 세금 및 기타 지불금을 지불합니다. 인구 소득 및 인구가 국가에 지불해야 하는 의무 지불에 대한 통계 데이터가 있으면 인구의 가처분 소득을 계산할 수 있습니다. 총 및 가처분 소득 지표는 다른 국가의 소득을 비교하고 지역별 소득, 인구의 부문별 소득, 영토를 비교하는 데 사용됩니다. 이러한 개념을 정의하기 위해 최소 생활비 또는 최소 소비자 예산에 대한 지표가 있습니다. 즉, 인구의 기본 사회 문화적 및 생리적 필요와 구매 비용을 충족시키는 데 필요한 소비재 및 서비스 세트입니다. . 이 지표는 또한 최저 임금을 결정하기 위해 계산됩니다. 생리적 생존 최소값은 일정 기간 동안 생리적 상태를 유지하는 데 필요한 최소 한도입니다(이 최소값은 국가에서 제공해야 함). 전체 인구의 수입과 지출을 규제하기 위해 주에서는 소비자 바구니인 각 개인의 최소 생계를 결정합니다. 이 개념에는 사람이 존재하는 데 필요한 모든 것의 평가가 포함됩니다. 즉, 식이 제한을 고려하고 필요한 최소 칼로리 수와 비식품 제품 및 서비스 비용, 세금 및 저소득 가구의 예산에서 이러한 목표에 대한 비용 분담을 기반으로 한 의무 지불. 인구가 최소한의 필요를 충족할 만큼 소득이 충분하지 않다면 이는 해당 국가가 빈곤선 아래에서 살고 있음을 의미합니다. 빈곤선, 즉 빈곤은 소득이 생리학적 최소치를 제공하기에 충분하지 않은 상태입니다. 빈곤 수준의 분석은 사회 경제적 및 인구 통계학적 가계 그룹에 의해 수행되며, 영토 맥락에서 빈곤 수준이 국가 평균 이상(또는 설정된 한계 이상)인 영역을 포함하는 "빈곤 지역"이 식별됩니다. . 인구의 생활 수준에 관한 통계의 중요한 부분은 재화와 서비스의 소비에 관한 통계입니다. 물질적 상품의 소비 기금은 국민 소득의 소비 기금의 일부를 나타내며, 여기에는 가족의 인구의 개별 소비와 교육, 문화, 건강 관리, 주택 및 공동 서비스 분야의 기관 및 조직에서의 소비가 포함됩니다. , 등. 공공소비자금을 특성화할 때 소비재의 부문별 출처와 보상원(개별예산 및 공공소비자금)을 고려하여 원가량뿐만 아니라 천연물 구성도 결정해야 한다. 이 그룹화를 통해 정적 및 역학에서 소비의 천연 재료 구조를 결정할 수 있습니다. 전체 인구의 소비에 대한 데이터는 무역 통계, 재무 통계 및 기타 여러 출처에서 얻습니다. 주요 사회 그룹 및 직업에 의한 인구 소비에 대한 정보는 인구 예산 통계에 포함되어 있습니다. 소비 기금의 주요 부분은 무역 인구가 획득 한 물질적 상품으로 구성되므로 사람들의 복지를 특성화 할 때 소매 무역 회전율 지표, 역학 및 구조가 널리 사용됩니다. 인구가 소비하는 총 물질적 상품은 단기 사용 품목, 주로 식품 및 내구재 품목으로 세분화됩니다. 물질적 상품의 소비와 함께 다음과 같은 서비스의 소비: - 교사, 교육자의 교육 및 교육 활동; - 예술가, 강사의 문화, 교육 및 미적 활동; - 의료인 등의 의료지원 및 예방조치 인구의 웰빙 지표 중 중요한 장소는 인구를위한 주택 제공 및 웰빙 정도, 즉 중앙 난방, 물 공급, 가스 공급, 전기 조명 등 특정 제품 및 서비스의 소비 역학은 개별 지수 공식을 사용하여 계산됩니다. 
여기서 I는 전체 인구에 대한 개별 소비 지수입니다. i - 1인당 개인소비지표 Q0,Q1 - 현재 및 기본 기간에 특정 유형의 제품 또는 서비스의 물리적 소비량. H0, HXNUMX - 현재 및 기본 기간의 평균 연간 인구. 주제 12. 다양한 소유권 형태의 기업 통계 12.1. 비즈니스 활동 통계 시장 경제에서 통계는 모든 수준의 국가 기관에 정보 및 분석 자료를 제공하며 이를 기반으로 시장 기능 분야에서 결정이 내려지고 세금 및 가격 정책이 개발되며 시장 발전을 촉진하기 위한 조치가 취해집니다 처지. 연구의 대상은 다양한 형태로 존재하는 기업입니다. 비즈니스 활동 통계는 다음과 같은 주요 블록을 포함하는 성과 기록표를 사용합니다. 시장의 상태 및 균형 지표 (기업 발전에 영향을 미치는 외부 요인으로): - 제품 제공; - 소비자 요구; - 시장의 용량, 포화도; - 시장 구조 지표; 상품 유통 및 서비스 판매 지표: - 회전율 및 서비스 판매 지표; - 무역 구조의 지표; - XNUMX인당 회전율 지표; - 상품 재고 및 상품 회전율의 지표; 상품 및 서비스에 대한 가격(관세) 지표: - 가격 수준 지표; - 가격 구조 지표; - 루블의 구매력과 인구의 금전적 소득에 대한 지표; 인프라 지표(재료 및 기술 기반): - 기업의 고정 자산, 수, 구성, 용량, 규모, 기술 장비; - 기업의 노동 자원의 숫자 구성; 기업의 상업 활동의 사회 경제적 효과 및 효율성 지표 : - 기업의 소득, 이익, 수익성 지표; - 유통 및 생산 비용; - 인건비 및 지불 - 고객 요구 충족 - 과세. 정보 출처는 일반적으로 통계 보고, 회계, 선택 및 단행본 연구의 데이터입니다. 통계는 다음 기준에 따라 정보를 분류합니다. -회계 작업 참가자 (고정 자산, 현금, 컨테이너의 상품 회계 정보) - 관리 단계(계획, 회계, 분석, 예후) - 관리 프로세스에 대한 태도(알림, 관리) - 제어 개체와의 관계(외부 및 내부, 수신 및 발신) - 교육 단계(초등 및 중등); - 안정성(조건부 고정 표준 및 조건부 가변 표준); - 데이터 범위의 완전성(충분한, 불충분한, 중복) - 처리 완료 정도(중간, 출력 또는 결과). 기업 통계 방법은 수학적 통계, 통계의 일반 이론 및 여러 산업 통계에 의해 개발된 일련의 기술 및 방법으로 대표됩니다. 그 중 관찰 통계, 요약 및 그룹화, 상대 값, 평균 값, 변동 지표, 시계열 지표, 지표 등을 구분할 수 있습니다. 기업 통계 업무는 다음과 같습니다. 기업의 상태 및 발전에 관한 정보 수집 및 처리; 기업 간의 시장 관계의 특성; 기업의 다양한 지표의 양과 구조, 수준 및 역학에 대한 연구; 기업 인프라의 상태 및 개발에 대한 연구 및 기업 기능의 사회 경제적 효율성 분석. 설정된 작업은 기업의 경제 서비스와 함께 통계 당국에서 해결합니다. 기업 활동 통계의 또 다른 구성 요소는 기업의 무역 및 상업 활동에 대한 통계입니다. 여기에는 판매자, 구매자, 생산자 및 소비자뿐만 아니라 생산자 및 재판매인을 기준으로 한 판매 행위의 분류가 포함됩니다. 통계는 다음과 같은 주요 범주를 고려합니다. 회전율은 상품을 돈으로 교환하는 과정, 따라서 시장 규모를 특성화하는 다기능 지표입니다. 정의 기능은 상품의 가용성과 판매 행위의 구현입니다. 통계는 도매, 소매, 총 및 순 회전율을 구분합니다. 총 회전율은 보고 기간 동안의 모든 판매 합계 또는 모든 구매 합계를 특징으로 합니다. 도매 회전율은 재판매인이 상품 판매에 참여하는 것을 고려합니다. 소매 회전율은 소비자에 대한 최종 제품 판매를 특징으로 합니다. 순 회전율은 국가 전체의 상품 판매를 특징으로하며 요식업 기업의 회전율을 고려한 소매 회전율과 같습니다. 개별 조직의 경우 순 회전율은 소매 회전율과 연구 대상 조직 외부의 생산량을 합한 것과 같습니다. 비즈니스 활동의 다음 지표는 제품 제안입니다. 이것은 상품 덩어리 형태의 산업 기업가 정신의 결과입니다. 제품 제안의 구성 요소는 판매자의 현재 생산 및 재고입니다. 상품 공급의 실제 수준은 가격 수준과 경제 및 기타 생산 조건의 준수 여부에 달려 있습니다. 시장 상황은 소비자 수요에도 반영됩니다. 수요를 연구할 때 개인 수요와 생산 수요, 소비재 수요, 생산 수단에 대한 수요를 구분합니다. 또한 통계는 다음과 같은 여러 기준에 따라 수요를 차별화합니다. - 상품 그룹에 대한 거시적 수요; - 개별 상품에 대한 소액 수요; - 불만족; - 만족(실현); - 집중 (성장); - 안정적이고 떨어지는 것; - 유사체가 없는 신제품에 형성됨; - 불안정한; - 견고하게 형성됨(고려됨); - 대안(자발적); - 기본 (거주지에서); - 철새; - 이동하는. 시장 상황은 또한 시장 용량의 지표(일반적으로 XNUMX년 이내에 시장에서 판매되는 상품의 양을 나타냄), 즉 특정 조건에서 특정 기간 동안 시장이 흡수할 수 있는 상품의 수량 또는 비용을 반영합니다. 기간. 시장 용량은 공식에 의해 결정됩니다. 시장 용량 = 국가 생산량 + 수입량 - 수출량. 특정 제품에 대한 수요에 대한 연구는 특정 회사 또는 국가 전체의 제품 판매량을 결정하기 위해 이 제품의 시장 용량을 결정하는 데도 필요하므로 시장 용량은 다음과 같이 표현할 수도 있습니다. : 시장 용량 = ? (i번째 그룹의 소비자 수 x i번째 그룹의 기준 기간의 소비 계수(또는 기준)) 가격과 소득의 탄력적 수요 계수 + 상품의 정상적 보험적립금의 양 (시장 포화) - 상품의 물리적 감가상각 - 상품의 진부화) - 요구 충족의 대체 시장 형태 - 시장에서 경쟁자의 점유율. 시장 포화는 소비자, 특히 가정에서 이미 사용할 수 있는 재화의 양입니다. 시장 용량이 높을수록 포화도가 낮아지고 그 반대도 마찬가지입니다. 시장이 이 제품으로 포화되면 시장 용량이 감소합니다. XNUMX인당 평균소비지표는 시장능력의 요소 중 하나로 시장포화도를 나타내는 지표로 많이 사용된다. 
식품의 XNUMX인당 소비 지수가 상대적으로 안정적이라면 소비 내에서, 즉 인구 증가를 초과하는 상당한 성장에 대한 전망이 없다는 증거로 작용한다는 점에 유의해야 합니다. 차례로, 식품에 대한 지출의 낮은 평균 비율은 국가 인구의 높은 생활 수준을 나타냅니다. 12.2. 다양한 소유권 형태의 기업 기능 효율성에 대한 통계 분석 효율성은 모든 유형의 사회 발전에 내재된 사회 경제적 범주입니다. 항상 효율성을 달성한다는 것은 생산과 관련된 비용 단위당 최대 결과를 얻거나 결과 단위당 비용을 최소화하는 것을 의미했습니다. 효율성은 또한 사용 가능한 재료 및 노동 자원과 관련하여 평가되어야 합니다. 자원의 양에 대한 달성된 결과(효과)의 비율은 자원에 포함된 기회 구현의 효율성, 자원 사용의 효율성을 나타냅니다. 시간 경과에 따른 이러한 관계의 변화는 비용 또는 자원 효율성 수준의 증가 또는 감소를 반영합니다. 효율성은 소유권 형태, 활동 유형 및 산업 계열에 관계없이 회사, 증권 거래소, 무역 기업의 모든 활동 수준에서 평가됩니다. 통계 지표 및 방법의 사용을 기반으로 기업 기능의 효율성을 평가하기 위한 일반적인 방법론적 원칙의 통일성이 있습니다. 기업 기능의 효율성에 대한 통계적 평가의 가장 일반적이거나 기본적인 모델에는 기업의 재무 및 경제적 상태에 대한 분석 및 평가가 포함됩니다. 이러한 분석을 수행할 가능성은 기업에서 신뢰할 수 있는 관리 및 회계 기록을 수행함으로써 보장됩니다. 이를 위해 재무 제표, 예산, 지불 일정, 사업 계획, 비용 구조 보고서, 판매량 보고서, 주식 현황 보고서, 운전자본 잔액, 내역서와 같은 관리 및 재무 회계 및 보고 형식 채무자와 채권자의 채무 등 기업 효율성의 통계 분석 대상은 다음과 같습니다. - 기업의 재무 결과의 수준과 역학; - 기업의 재산 및 재정 상태; - 상업 활동; - 기업의 자본 구조 관리; - 고정 자산 관리; - 운전자본 관리; - 재정적 위험 관리; - 예산 및 사업 계획 시스템; - 기업의 비 현금 지불 시스템. 다음은 위의 개체의 상태 또는 기능의 효율성에 대한 주요 기준(지표)입니다. 재무 결과의 수준과 역학을 통해 기업 활동의 최적화(제품 판매로 인한 수익 및 이익 증가, 생산 비용 절감 등)를 판단할 수 있습니다. 높은 품질의 이익, 높은 수준의 자본화(조건부 지표), 즉 축적 자금 창출을 목표로 한 높은 이익 비율, 기업이 처분할 수 있는 순이익에서 이익잉여금의 높은 비율은 다음의 생산 개발 가능성을 나타냅니다. 기업과 미래에 긍정적인 재무 결과의 성장. 재무 결과의 최적 역학은 자본 및 차입 자본의 수익성 (수익성) 증가, 다양한 유형의 활동으로 인한 총 이익 및 이익의 증가, 자본 회전율 등을 기반으로 판단 할 수 있습니다. 자본 구조에 대한 결정을 내릴 때 부채 융자 금액을 최적화한다는 점에서 회사가 수령한 소득 금액(수취한 소득의 충분함)에서 부채를 상환하고 상환할 수 있는 능력, 예상 현금 흐름의 규모와 안정성이 고려됩니다. 계정. 또한 기업의 산업, 영토 및 조직 특성, 목표 및 전략, 기존 자본 구조 및 계획된 성장률을 고려해야 합니다. 고정 자산(고정 자본)에 투자된 자본을 관리하기 위해 자본 생산성, 자본 집약도, 고정 자산의 수익성, 고정 자산의 증가로 인한 고정 자산의 상대적 저축의 지표로 특징되는 고정 자산 사용의 효율성을 연구합니다. 자본 생산성, 노동 도구의 수명 연장 등 운전 자본 관리의 효율성은 회전율, 자재 소비, 생산을 위한 자원 비용 절감 등의 지표, 운전 자본의 필요성 계산을 위한 과학적 기반 방법 사용, 확립된 표준 준수, 점유율 증가로 특징지어집니다. 최소 및 낮은 투자 위험을 가진 자산. 기업 기능의 효율성에 대한 간략한 통계 검토에는 다음과 같은 일반 지표에 대한 분석 및 평가가 포함됩니다. - 기업 기능의 기술 및 조직 수준; - 생산 자원 사용의 효율성 지표 : 고정 생산 자산의 자본 생산성, 생산의 재료 집약도, 노동 생산성, 제품의 양과 품질, 생산을 위한 자원 비용, 경제 활동을 위한 고정 자산 및 유동 자산, 재고 회전율 및 재료; - 핵심 및 재무 활동의 결과; - 제품의 수익성, 자본의 회전율 및 수익성, 기업의 재무 상태 및 지급 능력. 보다 자세한 분석에는 위 지표의 임계값과 최적값의 식별(계산), 실제 값과의 비교가 포함됩니다. 분석 기간 동안 각 지표의 변화를 평가하고, 지표의 구조와 변화를 평가하고, 지표의 역학을 평가하고, 지표의 변화 요인과 원인을 식별하는 것이 매우 중요합니다. 예를 들어, 이익 분석의 일부로 다음을 수행해야 합니다. - 이익 지표의 수준 및 역학 분석 및 평가 - 제품 (작품, 서비스) 판매로 인한 이익의 요인 분석; - 순이익 사용 분석 및 평가 - 비용, 생산(판매) 및 이익 간의 관계 분석 - 이익, 운전 자본의 이동 및 현금 흐름의 관계 분석. 기업의 비즈니스 (경제) 활동 및 효율성 분석에는 다음 지표도 사용됩니다. - 고정 자산의 활성 부분의 지분, 고정 자산의 감가상각, 퇴직 및 갱신 - 형성 출처가있는 매장량 제공; - 일반 유동성 지표, 현재 유동성 계수, 긴급 유동성, 절대 유동성 - 기업의 지불 의무 이행 수준, 기업에 대한 지불 의무 이행 수준. 현재 기업은 경쟁이 치열한 시장 상황에서 운영됩니다. 오늘날 비즈니스를 수행하는 조직의 적극적인 위치 없이는 불가능합니다. 이 입장은 역동적이고 효율적이며 합리적인 개발인 기업의 기능을 위한 전략적 목표의 존재를 전제로 합니다. 이 작업의 수행 정도에 대한 평가는 시장 관계 주제 기능의 효율성에 대한 통계 연구의 주제입니다. 12.3. 고정 자산 통계 고정 생산 자산 (OPF) - 이것은 노동 수단으로 실질적으로 구현되는 기업의 생산 자산의 일부입니다. 오랜 시간 동안 자연스러운 모양을 유지합니다. 부품 비용을 제품으로 이전하고 여러 생산 주기 후에만 비용을 상환합니다. 고정 자산 통계(F)의 가장 중요한 작업은 고정 자산의 노동력 연구, 고정 자산 구성의 존재 및 연구, 고정 자산의 이동, 사용 및 상태 연구입니다. 고정자산은 생산과정에 참여하는 정도에 따라 고정생산자산과 고정비생산자산으로 나뉜다. 고정 생산 자산(OPF)에는 생산 공정에 직접 관여하거나 생산 공정을 위한 조건을 조성하는 자금이 포함됩니다(예: 기계 및 장비, 전송 장치, 차량, 건물, 구조물 등). 고정 비 생산 자산은 기업의 대차 대조표에있는 가계 및 문화 시설입니다. 그것들은 장기간의 비산업적 사용의 대상으로서 자연적인 형태를 유지하고 점차 가치를 잃어가고 있습니다. 여기에는 주택 및 공동 서비스, 과학, 의료 등을 위한 기금이 포함됩니다. 이러한 기금은 소비자 가치를 창출하지 않습니다. 고정 생산 자산은 생산 공정 참여 정도에 따라 능동형과 수동형(건물 및 구조물)으로 나뉩니다. 백분율로 표시되는 전체 값에서 서로 다른 OPF 그룹의 비율이 OPF의 구조를 구성합니다. OPF의 활성 부분의 비중은 OPF 구조의 진행성을 특징으로 합니다. 고정 생산 자산을 특성화하기 위해 다양한 지표가 사용됩니다. 고정 생산 자산의 상태 및 역학 지표. 고정 자산의 수령 및 처분에 대한 완전한 그림은 다양한 출처에서 고정 자산 수령 및 다양한 이유로 처분에 대한 데이터가 포함된 대차대조표에 나와 있습니다. 대차 대조표는 모든 고정 자산과 개별 유형 모두에 대해 작성할 수 있습니다. 대차 대조표는 지점, 기업 및 국가 경제 전체에 대해 작성됩니다. 전체 역사적 비용의 고정 자산 대차 대조표의 형식은 다음과 같습니다. Fk \uXNUMXd Fn + V, 어디서 Фк - 연말 자금의 잔존 가치; Фн - 연초 자금의 잔여 가치; P - 연도 중 잔여 가치로 고정 자산 수령; B - 해당 연도 중 잔여 초기 비용으로 고정 자산 처분. 고정 자산 및 개별 유형의 이동 강도는 다음 계수로 계산됩니다. - 수령 계수 - 보고 기간 FC에서 이 기간 말의 총 거래량(Fc)에서 수령한 모든 수령(P)의 몫: 
- 퇴직률 - 특정 기간 동안 퇴직한 모든 고정 자산 가치(B)와 이 기간 시작 시점의 고정 자산 가치(Fn)의 비율: 
잔여 초기 비용의 고정 자산 대차 대조표에서 물체의 수령 및 처분 외에도보고 연도 중에 발생하는 감가 상각으로 인한 고정 자산의 잔여 가치 감소를 고려해야합니다. 잔여 초기 비용에서 FC 잔액의 기초는 평등입니다. 
여기서 Ap - 개조에 대한 감가 상각; - 감가상각 계수는 고정 자산의 감가상각액(I)과 총 비용(F)의 비율로 특정 날짜에 계산됩니다. 
- 100%와 마모 계수의 차이는 자산 수명 계수의 가치를 제공하고 고정 자산의 마모되지 않은 부분의 몫을 반영합니다. 이와 관련하여 유효성 계수를 계산하기 위해 다른 옵션을 사용할 수 있습니다. 
고정 생산 자산의 가용성 및 구조 지표. 매월 말 고정 자산의 가용성은 대차 대조표에 따라 결정되며 평균 연간 비용은 가용성에 대한 월간 데이터의 평균 시간순으로 결정됩니다. OPF 및 자본-노동 비율 사용의 지표. OPF 사용의 일반적인 지표는 자산 수익률입니다. 이 기간 동안 OPF의 평균 비용(F)에 대한 특정 기간에 생산된 제품의 양(O)의 비율입니다. 
자산 수익률은 1 문지름 동안 주어진 기간에 얼마나 많은 생산량이 생산되는지 보여줍니다. 고정 자산의 가치. 자본 집약도(상호)는 1 문지름당 OPF 비용을 특징으로 합니다. 제조된 제품: 
자본 집약도가 감소함에 따라 참여하는 고정 자산으로 구체화된 노동 경제가 있습니다. 생산 중. 자본 생산성과 자본 집약도의 가치는 자본-노동 비율(FV)에 의해 영향을 받습니다. 공식에 따라 계산됩니다 평균 직원 수는 어디에 있습니까? 자본 - 노동 비율은 근로자 작업의 장비 정도를 특성화하는 데 사용됩니다. 고정 생산 자산을 합리적으로 사용하면 사회적 제품의 생산과 국민 소득, 생활 및 물질화 된 노동의 저축이 증가하여 단위 생산량당 총 비용이 감소합니다. 고정 자산의 사용 수준을 높이는 경제적 효과는 사회적 노동 생산성의 증가입니다. 고정 생산 자산의 사용 수준이 증가하면 경제의 노동 생산성이 증가합니다. 12.4. 운전 자본 통계 회전 펀드는 하나의 생산주기 동안 완전히 소비되고 천연 물질 형태를 변경하고 가치를 완제품으로 완전히 이전하는 기업의 펀드입니다. 운전 자본에는 다음이 포함됩니다. - 원료 및 재료. 원자재는 후속 산업 가공에 들어가는 추출 산업 및 농업의 제품이며, 재료는 제품에 주요 부분으로 포함됩니다. 즉, 제품의 기초를 형성합니다. - 생산 공정을 보조하는 데 필요한 보조 재료(윤활제) 또는 제품에 원하는 특성을 부여하기 위해 기본 재료에 부착하는 데 필요한 보조 재료(바니시, 페인트, 광택제 등) - 구매한 반제품; - 자체 생산 반제품; - 연료; - 전기; - 현재 수리를 위한 예비 부품; - 용기 및 용기 재료; - 수명이 10년 미만인 값이 싸고 빨리 마모되는 품목(전체 운전 자본의 약 XNUMX%) - 작업 진행 중 - 시작되었지만 아직 하나의 생산 주기(약 19%)로 완료되지 않은 제품입니다. 기업의 영토 분열과 경제적 독립을 위해서는 원자재와 자재가 생산 비축 형태로 기업에 있어야 합니다. 기업의 원활한 운영에 필요하며 몇 가지 유형이 있습니다. - 생산 재고는 기업 창고에 있고 생산 소비를 목적으로 하지만 아직 생산 공정에 들어가지 않은 원자재, 자재 등입니다. 이러한 자원의 두 번의 연속 수령 사이에 재료 자원에 대한 현재 생산 요구를 중단 없이 충족시키는 현재 재고; 예상치 못한 상황에 대비하여 생성된 보험 주식; 생산 또는 공급이 계절적 특성을 갖는 원자재에 의존하는 기업에서 형성되는 계절적 비축(어류, 농산물 등); 진행중인 작업 재고 및 기업 창고의 완제품 재고. 이러한 유형의 주식은 한 유형에서 다른 유형으로 원활하게 이동할 수 있습니다. 그들은 매우 모바일입니다. 이것은 생산과 소비의 연속적이고 중단되지 않는 과정을 나타냅니다. 다양한 재료 자원의 재고 회전율 비용을 특성화하기 위해 몇 가지 상호 관련된 지표가 사용됩니다. - 회전율은 보고 기간 동안 이러한 유형의 운전자본이 업데이트된 횟수를 보여줍니다(이 비율이 높을수록 기업에 더 좋음). 
여기서 o는 물질 자원의 평균 균형입니다. TP - 상용 제품. - 또 다른 상대 지표는 한 회전율의 기간을 일 단위로 특성화하고 기간(T) 대 회전율의 비율을 나타냅니다. 
원자재, 자재, 연료의 특정 소비는 이러한 유형의 운전자본의 평균 소비를 보여줍니다. 특정 소비량은 한 단위의 출력을 제조하기 위한 재료 소비량입니다. 
어디서 - 재료 소비량 (kg, m, pc.); q는 이러한 유형의 제품의 단위 수입니다. - 재료 집약도 - 출력 단위 생산에 소요되는 재료 자원 비용: 
여기서 C - 화폐 단위의 실제 준비금; Q - 가치 측면에서 생산량. 제품의 재료 소비를 줄이는 것은 생산 효율성의 좋은 지표입니다. 회전 자금에는 노동 대상에 의해 형성되는 생산 수단의 부분이 포함됩니다. 재고를 포함하는 운전자본, 이연 비용을 포함한 미완성 제품은 정상화된 운전자본의 일부를 구성합니다. 이연 비용은 새로운 유형의 제품 생산 및 개발의 예상 준비와 관련된 비용입니다. 운전 자본 및 그에 따른 운전 자본 형성의 출처는 승인된 자본, 이익, 안정적인 부채, 단기 은행 대출, 다른 조직에서 조달한 자금, 예산 할당 등입니다. 소비된 운전 자본 비용은 제품 판매 시 즉시 상환됩니다. 이렇게 하면 새 생산 주기를 위해 다시 구매할 수 있습니다. 운전 자본과 고정 자산의 주요 차이점: - 고정 자산의 일부인 요소는 생성되는 제품에 포함되지 않습니다. 고정 자산은 여러 생산 주기와 관련됩니다. 회전 자금은 하나의 생산 주기 내에서 완전히 소비되어 완제품으로 변합니다. - 순환 자산은 한 생산 주기 동안 가치를 완전히 이전하지만 고정 자산 비용은 생산되는 제품 비용에 부분적으로 포함됩니다. - 고정자산은 상품 판매 후 감가상각 기준액에 해당하는 부분에서 원가를 상환하며, 운전자본은 상품 판매 과정에서 즉시 상환합니다. 12.5. 상품 및 서비스 비용 통계 상품 및 서비스 비용 통계는 회계 데이터를 기반으로하며, 그 작업은 총 비용을 계산하고 유형별로 그룹화하고 생산 단위 비용을 결정하는 것입니다. 회계 및 보고 데이터를 분석하는 통계는 이 영역에서 다음과 같은 주요 작업을 해결합니다. - 비용 유형별로 비용 구조를 마스터하고 비용 구조 수정이 비용 역학에 미치는 영향을 보여줍니다. - 생산 비용의 역학 측면에서 생산 작업 수행의 최종 특성; - 비용 가격의 역학에 영향을 미치는 요소를 고려합니다. 그러나 이러한 재화 및 서비스 비용 통계의 문제를 해결하기 위해서는 경제적 범주 및 경제 활동 결과에 영향을 미치는 수단으로서의 비용의 이론적이고 실제적인 내용에 대한 명확한 지식이 필요합니다. 상품 및 서비스 비용은 특정 유형의 상품 및 서비스를 생산 및 판매하는 과정에서 발생하는 모든 유형의 비용뿐만 아니라 제품 생산과 관련된 직접 비용입니다. 상품 및 서비스 비용에는 다음이 포함됩니다. - 재료 비용; - 인건비; - 변동 비용: 재료비, 고정 자산의 감가상각비, 핵심 및 보조 인력의 급여, 상품 및 서비스의 생산 및 판매와 직접 관련된 간접비. 재화와 서비스를 생산하는 각 기업에는 비용이 발생합니다. 제품의 생산 및 판매와 관련된 모든 비용의 화폐적 합계가 생산 비용입니다. 요소별 비용 분류: - 원료 및 재료; - 구매한 부품, 반제품 및 부품; - 보조 재료; - 외부로부터의 연료 및 에너지; - 임금(기본, 추가 등) - 고정 자산의 감가상각 - 기타 현금 비용. 생산원가를 원가항목으로 분류하는 방법에는 두 가지 유형이 있습니다. 용도별: 직접, 한 가지 유형의 비용(모든 임금, 모든 자재 등) 및 장비 유지 관리를 위한 간접 비용. 영향의 특성에 따라 일정하고 가변적입니다. 상수는 생산량에 의존하지 않지만 변수는 생산량에 의존합니다. 생산 원가는 품목 원가 계산에 따라 결정되는 생산 원가로 작용합니다. 생산 비용에 포함 된 비용의 구성은 법률에 의해 설정됩니다. 즉, 국가에서 규제합니다. 비용 통계 연구, 실제 비용이 규범적 비용과 다른 이유 식별 및 판매 가능한 산출물 단위당 생산 비용을 줄이는 가능한 방법의 정당화는 지수 방법을 기반으로 수행됩니다. . 앞서 언급한 바와 같이 지수는 특성을 일반화하는 데 사용되는 지표로, 비교 대상이 되는 재화나 용역이 소비자가치의 특성과 생산기술 측면에서 동일해야 함을 의미한다. 주제 13. 상품 회전율 및 가격 통계 13.1. 회전율 통계 상품 생산 조건에서 재생산 과정의 필요 조건은 상품 교환입니다. 생산자로부터 소비자에게 상품을 가져와서 그의 요구를 충족시키는 것이 무역 분야에서 운영되는 경제 주체의 주요 목표입니다. 상품의 교환은 상품 가치의 척도이자 유통 수단의 역할을 하는 화폐의 도움으로 수행됩니다. 경제 공간에서 생산자에서 소비자로의 상품 이동은 무역의 형태로 발생합니다. 거래 회전율은 금전적 등가물과 교환하여 제품 소유권 이전을 기반으로 하는 구매 및 판매 프로세스입니다. 이 분야에서 경제 통계의 중요한 임무는 통계 연구의 대상으로서의 이직률의 정의, 따라서 그 주제의 정의와 양적 및 질적 분석 방법입니다. 무역 회전율 통계의 주제는 생산자에서 소비자로의 상품 이동과 수량화 할 수있는 화폐 교환의 대량 프로세스 및 현상입니다. 현대 경제 공간의 무역 회전율은 고유 한 일반적인 추세 및 패턴을 가진 개별 경제 주체의 활동 결과를 교환하는 복잡한 경제 과정입니다. 회전율 통계의 목적은 시장성 있는 제품의 유통 과정에 대한 포괄적인 정량적 설명으로, 그것의 발달의 주요 경향과 규칙의 leniye. 무역 통계의 임무는 소유권이 다른 기업의 무역 회전율, 전국 및 지역 전체의 상품 유통 경로에 대한 정보의 수집, 일반화 및 분석입니다. 볼륨, 상품 구조, 회전율 역학 분석. 회전율을 연구할 때 그룹화를 사용하는 것이 편리합니다. 카테고리별로 회전율은 총 및 순, 도매 및 소매로 나뉩니다. 무역의 조직 형태에 따라 소매 및 도매, 조달 및 마케팅 조직의 회전율이 구별됩니다. 상품 유통의 형태에 따르면 회전율은 창고 및 운송입니다. 천연 재료 구성에 따라 회전율은 상품 그룹별로 연구됩니다. 또한 다양한 형태의 소유권을 가진 기업의 회전율을 연구합니다. 무역 통계 분석 방법론에서 무역을 특징 짓는 전체 지표 시스템이 개발되었습니다. 총 회전율은 생산자에서 소비자로 이동하는 과정에서 재화의 모든 판매의 합계입니다. 이 수치는 판매량에 따라 다릅니다. 재판매를 제외하면 순 회전율이 발생합니다. 제품 유통 프로세스 조직의 합리성을 특징 짓는 지표 중 하나는 링크 계수입니다. 순매출액에 대한 총매출액의 비율로 계산됩니다. XNUMX인당 무역 회전율은 해당 기간의 평균 인구에 대한 무역 회전율의 비율로 계산됩니다. 상품 회전율의 중요한 질적 특성은 구조의 지표입니다. 여기에는 개별 제품 또는 그룹 판매의 절대 지표와 상대 지표인 총 매출에서 각 제품 또는 그룹의 점유율(점유율), 두 제품 판매 비율이 포함됩니다. 기간의 시작과 끝의 상품 재고 지표와 평균은 상품 재고로 상품 회전율 제공 지표를 계산할 때 사용됩니다. 공급 일수의 회전율은 기간 시작 시점의 주식 제품과 회전율에 대한 일수의 비율로 계산됩니다. 회전율은 해당 기간의 평균 재고 가치에 대한 특정 기간의 거래량의 비율로 계산됩니다. 상호 지표는 상품 재고의 순환 시간이라고합니다. 지수 방법은 무역 회전율 연구에 널리 사용됩니다. 이 방법을 사용하면 무역 발전의 벡터와 속도를 평가할 수 있습니다. 특정 기간 동안의 회전율 변화는 현재 회전율과 기본 회전율의 비율을 특징으로 합니다. 현재 기간과 비교할 수 있는 이전 기간이 비교 기준으로 선택됩니다. 회전율 지수는 결합으로 인해 기준 기간과 비교하여 현재 기간에 판매 된 상품의 총계, 거래 현금 또는 구매자의 상품 구매 비용의 가치 변화를 특성화하는 상대 지표입니다. 수량 및 가격 변화의 영향. 회전율 통계에서 다음 지표가 계산됩니다. 상품 구조의 변화를 나타내는 지표인 주가 지수는 현재 기간의 개별 제품 또는 그룹의 몫과 기준 몫의 비율로 계산됩니다. 무역 회전율 현지화 지수는 무역 회전율의 비율과 지역 전체의 총 거래량에 대한 요인 기호입니다. XNUMX인당 무역 회전율 지수는 기준 기간에 대한 현재 기간의 XNUMX인당 무역 회전율입니다. 인구 역학의 영향을 제거합니다. 물리적 무역량 지수는 상품 수와 상품 범위의 변화가 상품 비용의 역학에 미치는 영향을 반영합니다. 영토 회전율 지수는 다른 지역의 회전율을 비교하며 한 지역의 평균 XNUMX인당 회전율의 비율로 계산됩니다. 회전율을 연구하는 또 다른 방법은 재화의 공급을 연구하는 방법입니다. 무역의 중요한 특성은 상품 공급의 리듬과 균일성입니다. 공급의 균일성은 일정한 간격으로 동일한 로트의 상품을 수령하는 것입니다. 납품의 리듬은 생산, 판매 및 소비의 계절적, 주기적인 특성을 고려하여 계약에 명시된 납품 조건 및 규모를 준수하는 것입니다. 동시에, 합의된 배송 기간 동안 계약 크기에서 실제 배송의 편차 정도를 나타내는 공급 부정맥 계수가 고려됩니다. 공급 변동 계수는 평균 공급 수준에서 이 평균 수준까지의 실제 공급 표준 편차의 백분율로 계산됩니다. 균일 계수의 역수입니다. 일반적으로 회전율 지표는 정부 및 기업 통계의 요구 사항을 충족합니다. 따라서 무역 회전율의 통계적 특성은 경제적, 사회적 지향성을 갖는다. 13.2. 재고 통계 상품 재고는 생산에서 수령한 순간부터 최종 소비자가 판매하는 순간까지 상품 유통의 영역에 있습니다. 상품 재고는 다양한 유통 경로에 집중되어 있습니다. 각 유형의 상품에 대한 크기는 다음과 같이 결정됩니다. - 상품의 특징; - 상품 구색; - 생산 조건; - 운송 조건; - 보관 조건; - 수요의 성격. 상업 활동의 효율성을 높이는 데 가장 중요한 것은 상품 재고의 운영 조작, 국가, 기업 및 조직 전반에 걸친 합리적인 분배에 속합니다. 통계에서 재고 순환률 지표 시스템은 주로 회전율 지표(재고 회전율) - N으로 계산됩니다. 이 지표는 주어진 거래량(TO)의 비율로 계산됩니다. 이 기간 동안의 평균 재고 W 값으로 기간: 
즉, 해당 기간 동안 평균적으로 재고가 몇 번이나 돌아갔는지 나타냅니다. 그 역수는 상품 재고 순환 시간의 지표입니다(일 단위) - t. 이 지표는 평균 재고 대 일일 회전율의 비율로 결정됩니다. 
여기서 D는 기간의 일 수입니다. 통계에서는 주요 추세와 유통 시간의 추가 가속화 기회를 식별하기 위해 주식의 역학과 순환 속도에 대한 연구에 많은 관심을 기울입니다. 상품 주식 지표의 역학 연구는 지수 방법을 기반으로 수행됩니다. 상품 재고의 총량 지수는 특정 기간 동안 상품 재고의 변화를 나타냅니다. 
여기서 3은 XNUMX일 공급량입니다. 분자와 분모의 차이(?31D1 -?30D0)는 적립금 가치의 절대적 증가 또는 감소를 나타냅니다. 개별 상품 그룹의 재고 변화가 총 재고량의 역학에 미치는 영향은 일 단위의 주가 지수를 사용하여 정량적으로 측정됩니다. 
동시에 분자는 보고 기간의 상품 재고량, 분모 - 상품 재고의 가용성이 기준 수준으로 유지되는 경우 보고 기간에 상품 재고량이 얼마인지를 보여주는 조건부 값 기간. 차이(?D131 -?D031)는 일 단위 수준의 변화로 인한 주식의 증가 또는 감소를 나타냅니다. 개별 상품 판매 변경이 상품 재고 총량의 역학에 미치는 영향은 야간 회전율 지수를 사용하여 계산됩니다. 
분자와 분모의 차이(?Z'1D0 -?Z'0D0)는 회전율의 증가로 인한 재고의 증가 또는 감소를 나타냅니다. 지수 사이에는 다음과 같은 관계가 있습니다. 
상품 주식의 역학을 연구하는 데 특히 중요한 것은 비교 가능한 가격을 사용하여 가격 변동의 영향을 고려하지 않고 주식의 역학을 특성화하는 주식의 물리적 볼륨 지수를 계산하는 것입니다. 이론적으로 그 구성은 다음과 같습니다. 
재고 통계에서 상품 공급의 균일성에 대한 평가도 고려해야합니다. 이 제품 또는 해당 제품이 동일한 기간 동안 얼마나 균등하게(동일한 배치로) 공급되는지 보여줍니다. 공급 균일성 분석은 일반적으로 15일의 맥락에서 분기의 변동 지표를 사용하여 수행됩니다. 도매 무역의 균형은 상품 자원의 가용성과 그 가치의 변화를 기반으로 합니다. 대차 대조표에는 다음이 반영됩니다. - 보고 기간 시작 시점의 상품 재고 - 출처별 상품 수령 - 상품 자원의 소비(공급 영역에서 인하, 재평가 또는 기타 매개변수로 인한 손실로 인한 행위에 의한 상각). 보고 기간 말의 재고를 반영합니다. 상품 공급에 대한 모든 데이터를 합산하면 총 회전율 방법을 사용하여 잔액을 작성할 수 있습니다. 도랑 및 순 회전율 방법에 따라 모든 상품의 공급에 대한 데이터를 요약하면 시스템 내 릴리스(회전율)를 뺀 값입니다. 재고 통계를 분석할 때 소매 거래 통계는 구성 요소로 간주됩니다. 소매 회전율 통계 작업에는 기업의 소매 회전율에 대한 데이터 수집, 소매 회전율 지표 개발(국가, 지역, 기업 그룹에 대한 합계, 기업당 평균, 특정 유형의 제품에 대한 합계, XNUMX인당 평균)이 포함됩니다. 소매 회전율의 역학에 대한 요인의 영향 분석. 소매 거래에는 다음이 포함됩니다.
소매 회전율을 연구할 때 회전율 작업의 수행을 분석하는 것이 좋습니다. 
소매 회전율의 역학의 계절적 측면은 계절성 지수를 사용하여 연구되고 또한 소매 회전율의 발전 패턴이 드러납니다. 분석을 위해 시간과 공간에서 비교할 수 있는 데이터만 가져옵니다. 시간 비교 가능성은 비교 지표가 동일한 기간 동안 취해진 것을 의미합니다. 공간에서의 비교 가능성은 기업 활동 영역, 조직 구조 및 전문 분야의 변화를 고려해야 할 필요성을 의미합니다. 소매 회전율 발전의 일반적인 추세를 식별하기 위해 다음과 같은 방법이 사용됩니다. 이동 평균법; 분석적 정렬 방법. 상품 재고의 역학을 분석 할 때 인구 수요의 양과 구조, 인구 소득의 양과 구조, 상품 회전율 지표의 변화의 영향을 고려해야합니다. 13.3. 상품 및 서비스 품질에 대한 통계 분석 지난 XNUMX년의 시장 동향은 제품(작업, 서비스)의 품질에 대한 요구 사항 수준을 크게 증가시켰습니다. 최대 품질 향상의 문제는 매우 관련이 있습니다. 저품질 상품 및 서비스 생산으로 인한 손실은 수백만 달러로 측정됩니다. 경제의 현재 단계에서 품질 관리 방법의 중요성은 분석가에 의해 중요하다고 평가됩니다. 모든 제조 공정에 대해 제조된 제품이 의도한 목적을 충족시키는 제품 성능 한계를 설정할 필요가 있습니다. 제품 품질의 주요 "적"은 다음 지표입니다. - 계획된 제품 사양의 값과의 편차; - 계획된 사양의 값에 비해 제품의 실제 특성의 변동성이 너무 높습니다. 생산 프로세스 디버깅의 초기 단계에서 실험 설계 방법은 종종 생산 품질의 이 두 지표를 최적화하는 데 사용됩니다. 일반적으로 생산에 사용되는 모든 기계 또는 기계는 생산되는 제품의 품질에 영향을 미치는 조정을 허용합니다. 설정을 변경하여 엔지니어는 최대 효과를 달성하고 제품 품질을 개선하는 데 가장 중요한 역할을 하는 요소를 찾아냅니다. 이 문제에서 중요한 점은 상품의 품질을 확인하는 것입니다. 생산에서 받은 상품, 특히 식품의 품질이 관리되며 현재 통계 보고에는 다음 데이터가 반영됩니다. 생산 또는 기타 출처에서 받은 상품; 사실 확인; 전체 입학에서 확인된 비율; 공급자에게 반환; 인증을 통과하지 못한 사람의 비율. 통계에서 개별 및 일반 계수가 계산됩니다. 예를 들어 개별 등급 계수는 각 제품 또는 구색 하위 그룹에 대해 결정됩니다. 
일반 등급 지수를 구성할 때 판매된 상품 수의 실제 회전율은 공동 측정 가중치 역할을 합니다. 제품의 현재 품질 관리는 생산 과정에서 수행됩니다. 이를 위해 품질 관리 방법과 같은 특수 절차가 설계되었습니다. 미국, 독일, 일본에서는 특히 집중적인 품질 관리 방법이 사용됩니다. 현재 품질 관리에 대한 일반적인 접근 방식은 다음과 같습니다. 생산 과정에서 주어진 양의 제품 샘플은 제조된 제품 또는 들어오는 원자재에서 선택됩니다. 그 후, 이 샘플에서 계획된 사양의 샘플 값의 평균값 및 변동성의 차트를 특별히 안을 댄 종이에 플롯하고 계획 값과의 근접 정도를 고려합니다. 차트에 샘플링된 값의 추세가 표시되거나 샘플링된 값이 지정된 한계를 벗어나면 프로세스가 통제 불능 상태로 간주되고 장애의 원인을 찾기 위해 필요한 조치가 취해집니다. 이러한 특수 차트를 Shewhart 관리도라고 합니다. 범위 플롯을 고려하는 것도 유용합니다. 범위는 샘플의 최대값과 최소값의 차이입니다. 이 특성의 실용적인 가치는 변동성의 척도 역할을 한다는 것입니다. 범위 그래프에서 점의 위치에 따라 제품 품질의 무작위성 또는 체계적 편차에 대한 결정이 내려집니다. 제조 품질 관리 엔지니어는 또 다른 일반적인 문제에 직면해 있습니다. 이는 전체 배치의 품질이 허용 가능한 수준인지 높은 확신을 갖고 말할 수 있도록 배치에서 검사해야 하는 항목의 수를 결정하는 것입니다. 이를 위해 필요한 품질을 보장하는 샘플링 절차가 개발됩니다. 샘플링 절차는 모든 제품을 검사하지 않고 제품 배치가 특정 사양을 충족하는지 여부를 결정해야 할 때 사용됩니다. 이러한 절차를 통계적 수용 통제라고 합니다. 제품의 전체 또는 전체 검사보다 샘플링의 명백한 이점은 전체 로트가 아닌 샘플만 연구하는 데 시간과 재정적 비용이 적게 든다는 것입니다. 마지막으로, 생산 관리의 관점에서 무작위 통제에 근거한 전체 로트 또는 선적의 거부는 제조업체와 공급업체가 더 엄격한 품질 표준을 준수하도록 강요합니다. 모집단에서 특정 크기의 반복 표본을 추출하고 연구된 제품 특성의 평균값을 계산하면 이러한 평균값의 분포가 특정 평균값과 표준 오차가 있는 정규 분포에 접근하게 됩니다. 그러나 실제로 표본 분포의 평균과 표준 오차를 추정하기 위해 모집단에서 반복 표본을 추출할 필요는 없습니다. 주어진 모집단에 얼마나 많은 변동성(표준 편차 또는 시그마)이 있는지에 대한 적절한 추정치가 주어지면 평균의 표본 분포를 추론할 수 있습니다. 이미 이 정보는 주어진 사양과 비교하여 품질의 일부 변화를 감지하는 데 필요한 샘플 크기를 계산하기에 충분합니다. 일반적으로 사양은 허용되는 값의 범위를 지정합니다. 이 구간의 하한을 공차 하한이라고 하고 상한을 공차 상한이라고 합니다. 그들 사이의 차이를 공차 범위라고 합니다. 제조 공정의 적합성을 나타내는 가장 간단한 지표는 잠재적 적합성입니다. 공정 범위에 대한 공차 범위의 비율로 정의됩니다. 규칙 6을 사용할 때 이 지표는 다음과 같이 표현할 수 있습니다. 
이 비율은 분포의 평균값이 명목, 즉 프로세스가 중앙에 있는 경우 공차 한계 내에 속하는 정규 분포 곡선 범위의 비율을 나타냅니다. 많은 국가에서 통계적 품질 관리 방법이 도입되기 전에 일반적인 생산 공정 품질은 약 Cp = 0,67이었습니다. 따라서 전체 제품의 33%가 허용 한계를 벗어났습니다. 이상적으로는 Cp = 1인 경우가 좋습니다. 즉, 허용 오차 범위를 벗어나는 제품이 거의 없거나 전혀 없는 공정 적합성 수준을 달성하려는 경우입니다. 낮은 제품 품질과 관련된 클레임 비용을 고려하면 높은 공정 적합성은 일반적으로 낮은 제품 비용을 초래한다는 점에 유의해야 합니다. 높은 제품 품질을 달성하면 생산 비용이 증가하지만 품질 저하, 시장 점유율 상실 등으로 인한 비용이 품질 관리 비용보다 훨씬 클 수 있다는 점을 항상 기억해야 합니다. 통계에 따르면 현재 대부분의 비즈니스는 레벨 3에서 운영되고 있습니다. 이는 엄청난 수의 오류를 수반하며, 그 중 상당수는 비즈니스 손실뿐만 아니라 인명 피해로 이어집니다. 오늘날 많은 기업은 퍼센트 단위로 측정되는 품질 수준이 더 이상 허용되지 않는다고 결정하고 자본 증가에 중점을 두지 않고 XNUMX분의 XNUMX 수준에서 품질 분야의 벤치마크를 설정합니다. 투자, 그러나 생산 관리 프로세스 개선에. 손실을 최소화하면 새로운 자본 투자도 최소화할 수 있다는 사실이 많은 사람들에게 분명해지고 있습니다. 현재 수준의 기술은 이전 수준의 허용 가능한 제품 품질을 제거합니다. 이제 비즈니스는 거의 완벽한 품질을 요구합니다. 13.4. 시장 인프라 통계 시장 - 전자 제품으로 채워진 가장 복잡한 장치에서 간단한 빵 한 덩어리에 이르기까지 다양한 상품이 거래되는 많은 거래가 이루어지는 판매자와 구매자 간의 접촉을 제공하는 경제 관계 시스템, 뿐만 아니라 광범위한 산업 및 소비자 서비스. 시장에는 자체 인프라가 있으며 이를 분석하면 기능 및 개발 프로세스를 보다 관리하기 쉽고 경제적으로 만들 수 있습니다. 시장 인프라 - 판매자와 구매자, 상품 유통, 광고, 금전 교환, 시장 기업의 금융 및 경제 활동과 같은 주요 시장 프로세스를 조직적이고 물질적으로 지원하는 일련의 상호 연결된 기관 및 수단. 시장 인프라에는 다음이 포함됩니다. - 무역 창고 및 관리 건물 및 장비 - 광고 장비; - 컴퓨터 및 기타 정보 및 컴퓨팅 장비 - 무역 및 현금 장비, 서비스 장비 - 통신 수단 및 차량 - 노동 자원. 인프라 전체와 그 요소는 유형, 품질 및 감가상각을 고려하여 금전적 측면에서 측정할 수 있습니다. 기반 시설의 개별 요소와 그 유형은 자연 단위로 측정됩니다. 통계는 시장의 기반 시설을 독립적인 주제로 연구합니다. 시장 인프라 통계의 주제는 판매, 무역 및 서비스, 전자 컴퓨팅 및 정보 장비, 차량 및 기타 유형의 지원을 포함한 물질적 및 기술적 잠재력과 노동 조건을 포함하여 대량 현상 및 형성 및 기능 프로세스입니다. 정량적으로 표현할 수 있는 시장 활동. 인프라와 그 요소를 연구하는 것의 필요성과 중요성은 시장 과정에서 인프라가 수행하는 중요한 역할에 따라 결정됩니다. 주 통계의 경우 소유권 형태에 관계없이 시장 기반 시설은 국가의 부와 생산 잠재력의 일부입니다. 결과적으로 기업가의 경우 인프라를 연구해야 할 필요성은 본질적으로 마케팅 기능을 수행하고 시장 프로세스를 구현하기 위한 조직 및 기술 도구라는 사실 때문입니다. 시장 기반 시설 통계의 주요 목표는 재료 및 기술 기반의 상태와 능력을 평가하고, 상품의 이동 및 서비스 판매를 보장할 가능성을 연구하고, 사용 효과를 특성화하는 것입니다. 인프라 및 해당 요소의 작업, 목표 및 특성의 구현은 통계 지표 시스템을 사용하여 수행됩니다. 여기에는 다음이 포함됩니다. - 무역 기업, 대량 취사 및 서비스에 의한 고정 자산 사용의 효율성: 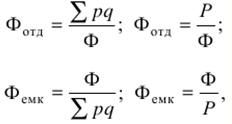
어디서 Fodd - 자산 수익률; Femk - 자본 집약도; - 고정 자산 비용; ?pq - 회전율; - 이익; - 기업의 규모, 무역 단위: 상점 및 서비스 기업 - 면적(대량 케이터링 기업의 경우 - 방문자를 위한 장소 수, 창고의 경우 - 면적 또는 용량): 
여기서 M은 기업의 면적, m2입니다. S는 소비자 수입니다. k - 기업의 능력; - 처리량에 대한 거래 형태의 진보성의 영향 계수. 각 양식에 할당된 전문가가 소비한 소비자 시간 포인트의 산술 가중 평균으로 계산되며(전통적인 양식은 XNUMX과 같음) 회전율에서 각 양식이 차지하는 몫에 가중치를 둡니다. 
여기서 W - 저장 용량; Z - 상품 재고; - 창고 1m2당 상품 재고 배치에 대한 밀도 표준; V는 창고에서 불균일 한 상품 수령 계수입니다. K는 저장 공간 용적 사용에 대한 규범 계수입니다. h - 창고 높이; Mskl - 창고를 위한 영역. Мtot - 창고의 총 면적; - 기업의 전체 면적에서 거래소 (방문객 홀) 면적의 몫 : 
여기서 Mtz는 거래 층의 면적입니다. Mtot - 상점의 전체 영역; - 기업의 처리량: 
- 양방향 마케팅의 경우 - 상업 활동과 관련된 웹사이트의 수 - 전자 상점의 수; - 구매자가 상품 구매에 소요한 시간: 무역 기업으로 가는 도중, 서비스 대기열에서, 상품 선택 시, 상품 출시 시, 결제 노드에서(서비스 기업에서: 수신 및 서비스 제공을 위한 주문의 발행 또는 실행을 위해 제품의 제조 및 수리를 위한 주문을 하는 단계; - 보편적, 전문화 및 혼합 기업의 총 수에서 수와 점유율: 
여기서 Nsp는 전문 기업의 수입니다. Mtot - 기업의 총 수; - 무역 기업의 밀도 계수: 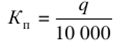
(인구 10명당 기업의 수 또는 그 면적, 위치 등) - 차량 수, 통신 수단, 기업(기업)당 정보 및 컴퓨터 기술 또는 1만 루블. 회전율; - 직원 수(전체, 전문 분야 및 직위별), 기업당 직원 수, 1m2(무역 바닥 포함), 직원당 회전율 - 장비, 메커니즘 및 기타 장비(금전 등록기 포함)의 수: 유형 및 유형별, 기업별, 1만 루블당. 회전율. 13.5. 가격 통계 가격 통계 - 산업, 농업, 건설, 다양한 서비스에 대한 관세 등 다양한 경제 부문의 가격을 연구하는 경제 통계 섹션 중 하나입니다. 가격 통계는 수준, 구조, 변화 패턴, 역학, 가격 및 관세 등록 원칙 및 방법 연구, 가격 변동 및 비율 연구, 정보 프로세스 및 인구 화폐 소득의 색인화를 연구합니다. 가격 통계는 소비자 물가 지수가 인구의 다양한 사회 집단의 양, 소비 구조 및 실질 소득 수준에 미치는 영향을 평가하는 문제에 특별한 관심을 기울이고 장소를 고려하여 특정 조건의 가격 문제를 탐구합니다. , 경제 발전의 시간과 기간. 가격 통계 연구에는 통계적 관찰, 관찰 요약 및 그룹화, 얻은 일반화된 자료 및 지표 분석의 세 단계가 있습니다. 가격 등록은 두 가지 방법으로 수행할 수 있습니다. 국가가 정한 안정적인 물가를 조건으로 통계회계를 적용하였다. 시장경제로의 전환과 함께 국내경제는 대표통계와 비교가능성의 원칙에 따라 유동경제 국가에서 사용하는 표본추출법을 사용하기 시작하였다. XNUMX단계에서는 대표 데이터를 체계화하고 일반화한다. 통계 연구의 세 번째 단계에서는 가격에 대한 요약 통계 자료를 분석하고 추세 및 패턴을 식별하고 특성 및 평가를 제공합니다. 가격에 대한 통계적 연구 과정에서 가격 수준과 그 역학이 계산됩니다. 물가 수준은 소비자 속성이 유사한 상품 및 상업 유형의 전체 측면에서 특정 영역에서 특정 기간 동안 가격 상태를 특성화하는 일반적인 지표입니다. 가격 수준은 사용 가능한 변동을 보여주며 평균 값으로 나타납니다. 개별, 평균 및 일반화된 가격 수준을 할당하는 것이 가능합니다. 개별 물가 수준은 상품 단위에 대해 시장에서 지불하는 금액입니다. 평균 가격은 시간이나 공간에 따라 변하는 가격에 대해 동종 제품 그룹의 가격에 대한 일반화된 특성입니다. 평균 가격은 특정 기간(월, 분기, 연도), 지역(주어진 제품 유형에 대한 가격 수준의 개별 지역 단위 차이 있음), 상품 그룹(상품의 평균 가격)으로 계산됩니다. 다양한 카테고리 및 품종). 가격의 경제 및 통계 분석에는 다양한 통계 방법이 사용되며 그 중 지수 방법이 특별한 위치를 차지합니다. 다양한 유형의 동적 및 지역 지수가 가격 통계에 널리 사용됩니다. 첫 번째는 시간이 지남에 따라 특정 유형의 가격(구매, 도매, 소매 등) 수준의 변화를 특성화하는 역할을 하고, 두 번째는 비율, 서로 다른 동일한 상품의 동시에 존재하는 가격 수준의 차이 정도를 표현하는 역할을 합니다. 도시, 경제 지역, 사회 단체. 모든 제품에 대한 가격의 역학을 나타내려면 비교 기간(또는 특정 날짜)에 대한 가격을 갖는 것으로 충분합니다. 기존 가격에 대한 새로운 가격의 단순한 비율은 주어진 상품의 가격 변화의 방향뿐만 아니라 변화의 정도를 확립하는 것을 가능하게합니다. 이러한 상대 가치를 일반적으로 개별 물가 지수(i = p1 / p0 )라고 합니다. 가격 지수의 일반적인 유형은 총계와 조화 평균입니다. 대부분의 가격 지수는 현재 기간 가중치가 있는 집계 공식을 사용하여 계산됩니다. 
여기서 P1과 po는 현재 및 기준 기간의 상품 가격입니다. d1 - 현재 기간의 제품 수. 이 지수의 각 부분에는 명확한 경제적 내용이 있습니다. ?Р1д1 - 현재 기간의 판매(또는 제조) 제품의 실제 수량, ?Р0Ч1 - 현재 기간의 제품 가격에서 조건부 판매량(생산) 기준 기간. 총물가지수는 물리적으로 판매(생산)된 제품의 수량에 대한 데이터가 보고된 모든 경우에 계산됩니다. 제품 회계가 비용 형태로만 수행되는 경우 가격 지수 계산은 평균 조화 지수 공식에 따라 수행됩니다. 
여기서 나는 = p1/p0 경제적 내용 측면에서 이러한 가격 지수는 동일합니다. 두 가지 형태의 지수는 평균 물가 수준의 상대적인 변화를 특징으로 합니다. 지수의 형식을 선택할 때 우선 완전하거나 선택적인 회계를 기반으로 얻은보고의 특정 상품에 대한 가격 책정의 세부 사항과 초기 데이터의 가용성에서 진행됩니다. 가격 지수는 특정 유형의 전체 가격 세트와 개별 부품 모두에 대해 계산됩니다. 실제로 연간 지수는 분기별 및 월별과 같이 더 짧은 기간 동안뿐만 아니라 각 유형의 가격에 대해 계산됩니다. 가격 역학 분석에는 지수와 함께 동적 가격 계열, 평균 그룹 가격, 비용 데이터 및 개별 상품 유형의 가격 구조가 널리 사용됩니다. 평균 가격을 계산하는 다양한 방법이 사용되며 선택은 정보의 가용성에 따라 다릅니다. 여러 경제적 계산을 위해 평균 그룹 가격이 널리 사용됩니다(예: 모든 유형 및 품종의 고기 1톤 가격). 가중 산술 평균 또는 가중 조화 평균으로 계산할 수 있습니다. 또한 평균 그룹 가격은 각 제품 유형의 가격 수준과 판매 구조(판매량에서 각 제품 유형의 점유율)에 따라 다릅니다. 물가 수준은 인구 소득의 구매력과 불가분의 관계에 있습니다. 즉, 화폐 소득에 해당하는 상품으로 측정되고 상대 물가 수준을 나타내는 값입니다. 화폐 소득의 구매력은 XNUMX인당 평균 화폐 소득, 평균 임금, 평균 연금 등의 금액에 대해 얼마든지 상품을 구매할 수 있는 능력을 나타냅니다. 계산은 전체 인구 및 개별 사회 집단 모두에 대해 수행할 수 있습니다. 국가 전체 또는 개별 지역: 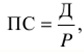
여기서 PS - 구매력; D - XNUMX인당 현금 소득; P - 상품의 평균 가격. 따라서 가격은 재화의 가치를 화폐단위로 나타내고 구매력은 재화로 표현되는 화폐의 가치, 즉 하나의 화폐단위로 얼마나 많은 재화를 살 수 있는지를 나타낸다. 루블화의 구매력이 높아짐에 따라 소비자 물가 수준만을 사용할 필요가 있으며, 화폐의 구매력은 상품의 종류와 품질, 가격 구조와 암시장의 부재는 변함이 없습니다. 가격 수준은 새로운 유형의 상품의 출현, 오래된 상품의 소멸, 소비 구조에서 개별 상품의 점유율 변화, 계절적 가격 변동과 같은 다양한 구색 변화의 영향을 받습니다. 문학 1. Eliseeva I.I., Yuzbashev M.M. 일반 통계 이론: 교과서. 엠., 1998. 2. Efimova M.R., Petrova E.V., Rumyantsev V.N. 통계의 일반 이론. 엠., 1996, 2002. 3. 사회경제통계학과 / Ed. MG 나사로프. 엠., 2000. 4. 통계의 일반 이론: 교과서 / Ed. 스피리나, O.E. 바티나. 엠., 1994. 5. 통계 일반 이론: 교과서 / Ed. O.E. 바티나. 스피린. 5판. 엠., 1999. 6. 통계 이론 워크샵: 교과서 / Ed. 교수 슈모일로바. 엠., 1998, 2000. 7. Sidenko A.V., Popov G.Yu., Matveeva V.M. 통계: 교과서. 엠., 2000. 8. 사회경제적 통계: 교과서 / Ed. 비아이 바쉬카토프. 엠., 2002. 9. 재화 및 용역의 통계: 교과서 / Ed. 아이케이 벨랴프스키. 엠., 2002. 10. 기업의 경제학과 통계 / Ed. SD 일리엔코바. 엠., 2000. 참고 사항 1. 통계 이론: 교과서 / Ed. 교수 R.A. 슈모일로바. 3, 에드. 개정 M., 2001. S. 260. 2. 사회경제통계학과 : 대학교과서 / Ed. 교수 MG 나사로프. M., 2000. S. 407. 3. 경제통계 : 교과서 / Ed. 유.엔. 이바노바. 2nd ed., 추가. M., 2002. S. 480. 4. Zherebin VM, Ermakova N.A. 인구의 생활 수준 - 오늘날 이해되는 바와 같이 // 통계에 대한 질문. 2000. No. 8. P. 4. 5. 사회통계: 교과서 / Ed. 아이.아이. 엘리제바. M., 1997. S. 69-70. 저자: 네가노바 L.M.
정원의 꽃을 솎아내는 기계
02.05.2024 고급 적외선 현미경
02.05.2024 곤충용 에어트랩
01.05.2024
▪ 사이트의 Wonders of Nature 섹션. 기사 선택 ▪ 기사 플로팅 전원이 있는 4개의 트랜지스터 증폭기. 무선 전자 및 전기 공학 백과사전
홈페이지 | 도서관 | 조항 | 사이트 맵 | 사이트 리뷰
www.diagram.com.ua |





 다른 기사 보기 섹션
다른 기사 보기 섹션 