|
|






 Arabic
Arabic Bengali
Bengali Chinese
Chinese English
English French
French German
German Hebrew
Hebrew Hindi
Hindi Italian
Italian Japanese
Japanese Korean
Korean Malay
Malay Polish
Polish Portuguese
Portuguese Spanish
Spanish Turkish
Turkish Ukrainian
Ukrainian Vietnamese
Vietnamese|
강의 요약, 유아용 침대
데이터 베이스. 강의 노트: 간략하게, 가장 중요한
차례
강의 1. 소개 1. 데이터베이스 관리 시스템 데이터베이스 관리 시스템(DBMS) 다음을 허용하는 전문 소프트웨어 제품입니다. 1) 임의로 많은 양의 데이터를 영구적으로 저장합니다(무한하지 않음). 2) 소위 쿼리를 사용하여 어떤 방식으로든 이러한 저장된 데이터를 추출하고 수정합니다. 3) 새로운 데이터베이스를 생성합니다. 즉, 논리적 데이터 구조를 설명하고 구조를 설정합니다. 즉, 프로그래밍 인터페이스를 제공합니다. 4) 여러 사용자가 동시에 저장된 데이터에 액세스합니다(즉, 트랜잭션 관리 메커니즘에 대한 액세스 제공). 따라서, 데이터 베이스 관리 시스템의 제어 하에 있는 데이터 세트입니다. 이제 데이터베이스 관리 시스템은 시장에서 가장 복잡한 소프트웨어 제품이며 그 기반을 형성합니다. 앞으로 기존 데이터베이스 관리 시스템과 객체지향 프로그래밍(OOP) 및 인터넷 기술을 결합하여 개발할 계획입니다. 초기에 DBMS는 계층적 и 네트워크 데이터 모델, 즉 트리 및 그래프 구조에서만 작업할 수 있습니다. 1970년 개발 과정에서 Codd(Codd)가 제안한 데이터베이스 관리 시스템은 다음을 기반으로 합니다. 관계형 데이터 모델. 2. 관계형 데이터베이스 "relational"이라는 용어는 영어 단어 "relation"- "relationship"에서 유래합니다. 가장 일반적인 수학적 의미에서(고전적 집합 대수학 과정에서 기억할 수 있음) 태도 - 세트입니다 R = {(엑스1,..., 엑스n) | 엑스1 ∈ ㄱ1,...,엑스n ∈ An}, 어디 A1,..., ㅏn 데카르트 곱을 구성하는 집합입니다. 이런 식으로, 비율 R 는 집합의 데카르트 곱의 하위 집합입니다.1 x... xAn : ㄹ ⊆ 에이 1 x... xAn. 예를 들어, 숫자 A의 순서 쌍 집합에 대한 엄격한 순서 "보다 큼" 및 "보다 작음"의 이진 관계를 고려하십시오. 1 = A2 = {3, 4, 5}: R> = {(3, 4), (4, 5), (3, 5)} ⊂ A1 x 에이2; R< = {(5, 4), (4, 3), (5, 3)} ⊂ A1 x 에이2. 이러한 관계는 테이블 형식으로 표시될 수 있습니다. "보다 큼" 비율>:
비율 "미만" R<:
따라서 우리는 관계형 데이터베이스에서 다양한 데이터가 관계의 형태로 구성되고 테이블 형태로 표시될 수 있음을 알 수 있습니다. 이 두 관계 R> 그리고 R< 즉, 이러한 관계에 해당하는 테이블은 서로 동일하지 않습니다. 따라서 관계형 데이터베이스의 데이터 표현 형식은 다를 수 있습니다. 이 다른 표현의 가능성은 우리의 경우에 어떻게 나타납니까? 관계 R> 그리고 R< - 이들은 집합이고 집합은 순서가 지정되지 않은 구조입니다. 즉, 이러한 관계에 해당하는 테이블에서 행을 교환할 수 있습니다. 그러나 동시에 이러한 집합의 요소는 순서가 지정된 집합입니다. 이 경우에는 순서가 지정된 숫자 3, 4, 5 쌍으로 열을 교환할 수 없습니다. 따라서 우리는 임의의 행 순서와 고정된 수의 열이 있는 테이블 형식의 관계 표현(수학적 의미에서)이 허용 가능하고 올바른 관계 표현 형식임을 보여주었습니다. 그러나 우리가 관계 R을 고려한다면> 그리고 R< 그들에 포함된 정보의 관점에서 볼 때 그것들은 동등하다는 것이 분명합니다. 따라서 관계형 데이터베이스에서 "관계"의 개념은 일반 수학에서의 관계와 약간 다른 의미를 갖습니다. 즉, 표 형식의 프레젠테이션에서 열별 정렬과 관련이 없습니다. 대신, 소위 "행 - 열 표제" 관계 체계가 도입되었습니다. 즉, 각 열에 표제가 부여된 후 자유롭게 교체할 수 있습니다. 이것이 우리의 R 관계가 보일 것입니다> 그리고 R< 관계형 데이터베이스에서. 엄격한 순서 관계(관계 R 대신>):
엄격한 순서 관계(관계 R 대신<):
두 테이블 관계 모두 새로운 것을 얻습니다(이 경우, 헤더를 추가로 도입함으로써 관계 R> 그리고 R<) 제목. 따라서 테이블에 필요한 헤더를 추가하는 것과 같은 간단한 트릭의 도움으로 관계 R> 그리고 R< 서로 동등해집니다. 따라서 우리는 일반적인 수학적 및 관계적 의미에서 "관계"의 개념이 완전히 일치하지 않으며 동일하지 않다는 결론을 내립니다. 현재 관계형 데이터베이스 관리 시스템은 정보 기술 시장의 기반을 형성하고 있습니다. 다양한 정도의 관계형 모델을 결합하는 방향으로 추가 연구가 진행되고 있습니다. 강의 #2. 누락된 데이터 누락된 데이터를 감지하기 위해 데이터베이스 관리 시스템에는 비어 있는 값(또는 비어 있는 값)과 정의되지 않은 값(또는 Null 값)의 두 가지 값이 설명되어 있습니다. 일부(대부분 상업) 문헌에서 Null 값은 때때로 비어 있거나 Null 값으로 언급되지만 이는 잘못된 것입니다. 공허한 의미와 부정확한 의미의 의미는 근본적으로 다르기 때문에 특정 용어의 사용 맥락을 주의 깊게 관찰할 필요가 있다. 1. 빈 값(빈 값) 빈 값 잘 정의된 데이터 유형에 대해 가능한 많은 값 중 하나일 뿐입니다. 우리는 가장 "자연스러운"즉각적인 것을 나열합니다. 빈 값 (즉, 추가 정보 없이 스스로 할당할 수 있는 빈 값): 1) 0(영) - 숫자 데이터 유형의 경우 null 값이 비어 있습니다. 2) 거짓(잘못) - 부울 데이터 유형에 대한 빈 값입니다. 3) B'' - 가변 길이 문자열에 대한 빈 비트 문자열; 4) "" - 가변 길이의 문자열에 대한 빈 문자열입니다. 위의 경우 기존 값을 각 데이터 유형에 대해 정의된 null 상수와 비교하여 값이 null인지 여부를 확인할 수 있습니다. 그러나 데이터베이스 관리 시스템은 장기 데이터 저장을 위해 구현된 체계로 인해 일정한 길이의 문자열에서만 작동할 수 있습니다. 이 때문에 빈 비트 문자열을 이진 XNUMX의 문자열이라고 할 수 있습니다. 또는 공백이나 다른 제어 문자로 구성된 문자열은 빈 문자열입니다. 다음은 일정한 길이의 빈 문자열의 몇 가지 예입니다. 1) B'0'; 2) B'000'; 삼) ' '. 이 경우 문자열이 비어 있는지 어떻게 알 수 있습니까? 데이터베이스 관리 시스템에서 논리 함수는 비어 있는지 테스트하는 데 사용됩니다. IsEmpty(<식>), 문자 그대로 "비어 먹다"를 의미합니다. 이 술어는 일반적으로 데이터베이스 관리 시스템에 내장되며 모든 유형의 표현식에 적용할 수 있습니다. 데이터베이스 관리 시스템에 이러한 술어가 없는 경우 논리 함수를 직접 작성하여 설계 중인 데이터베이스의 개체 목록에 포함할 수 있습니다. 빈 값이 있는지 여부를 결정하기가 쉽지 않은 또 다른 예를 고려하십시오. 날짜 유형 데이터. 날짜가 01.01.0100 범위에서 다를 수 있는 경우 이 유형의 값은 빈 값으로 간주되어야 합니다. 31.12.9999년 XNUMX월 XNUMX일 이전? 이를 위해 DBMS에 특별 지정이 도입되었습니다. 빈 날짜 상수 {...}, 이 유형의 값이 작성된 경우: {DD. MM. YY} 또는 {YY. MM. DD}. 이 값을 사용하면 값이 비어 있는지 확인할 때 비교가 발생합니다. 이 유형의 표현식에 대한 잘 정의된 "전체" 값으로 가능한 가장 작은 값으로 간주됩니다. 데이터베이스로 작업할 때 null 값은 종종 기본값으로 사용되거나 표현식 값이 누락될 때 사용됩니다. 2. 정의되지 않은 값 (널 값) 워드 null로 나타내기 위해 사용 정의되지 않은 값 데이터베이스에서. null로 이해되는 값을 더 잘 이해하려면 데이터베이스의 일부인 테이블을 고려하십시오.
따라서, 정의되지 않은 값 또는 널 값 - 이: 1) 알 수 없지만 일반적입니다. 즉, 적용 가능한 값입니다. 예를 들어, 우리 데이터베이스의 1980위인 Mr. Khairetdinov는 의심할 여지 없이 일부 여권 데이터(예: XNUMX년에 태어난 사람 및 해당 국가의 시민)를 가지고 있지만 알려지지 않았으므로 데이터베이스에 포함되지 않습니다. . 따라서 Null 값은 테이블의 해당 열에 기록됩니다. 2) 해당 값이 아닙니다. Karamazov (우리 데이터베이스의 2 번)는 단순히 여권 데이터를 가질 수 없습니다. 왜냐하면이 데이터베이스를 만들거나 데이터를 입력 할 당시 그는 어린이 였기 때문입니다. 3) 적용 가능한지 여부를 말할 수 없는 경우 테이블의 셀 값. 예를 들어, 우리가 수집한 데이터베이스에서 세 번째 위치를 차지하는 Mr. Kovalenko는 생년월일을 알지 못하므로 그가 여권 데이터를 가지고 있는지 여부를 확실하게 말할 수 없습니다. 결과적으로 Kovalenko 씨 전용 라인에 있는 두 셀의 값은 Null 값이 됩니다(첫 번째 - 일반적으로 알려지지 않은 값, 두 번째 - 특성이 알려지지 않은 값). 다른 데이터 유형과 마찬가지로 Null 값도 특정 등록. 우리는 그 중 가장 중요한 것을 나열합니다. 1) 시간이 지남에 따라 Null 값에 대한 이해가 변경될 수 있습니다. 예를 들어, 2년 Karamazov(데이터베이스의 2014번)의 경우, 즉 성년에 도달하면 Null 값이 특정하고 잘 정의된 값으로 변경됩니다. 2) Null 값은 모든 유형(숫자, 문자열, 부울, 날짜, 시간 등)의 변수 또는 상수에 할당될 수 있습니다. 3) Null 값을 피연산자로 사용하는 표현식에 대한 연산 결과는 Null 값입니다. 4) 이전 규칙에 대한 예외는 흡수 법칙의 조건에서 결합 및 분리의 연산입니다(흡수 법칙에 대한 자세한 내용은 강의 4번 단락 2 참조). 3. Null 값과 표현식 평가에 대한 일반 규칙 Null 값을 포함하는 표현식에 대한 작업에 대해 자세히 알아보겠습니다. Null 값을 처리하기 위한 일반 규칙(Null 값에 대한 연산 결과가 Null 값임)은 다음 연산에 적용됩니다. 1) 산술로; 2) 비트 단위 부정, 결합 및 분리 연산(흡수 법칙 제외) 3) 문자열 작업(예: 연결 - 문자열 연결) 4) 비교 연산(<, ≤, ≠, ≥, >). 예를 들어 보겠습니다. 다음 작업을 적용한 결과 Null 값을 얻습니다. 3 + Null, 1/ Null, (Ivanov' + '' + Null) ≔ Null 여기에서는 일반적인 평등 대신 다음을 사용합니다. 대체 작업 "≔"는 Null 값으로 작업하는 특수한 특성으로 인해 발생합니다. 다음에서 이 기호는 유사한 상황에서도 사용됩니다. 즉, 와일드카드 문자 오른쪽에 있는 표현식이 목록에서 와일드카드 문자 왼쪽에 있는 표현식을 대체할 수 있습니다. Null 값의 특성은 종종 일부 표현식에서 예상되는 null 대신 Null 값을 생성하는 결과를 낳습니다. 예를 들면 다음과 같습니다. (x - x), y * (x - x), x * 0 ≔ x = Null인 경우 Null입니다. 문제는 예를 들어 표현식 (x - x)에서 값 x = Null을 대입하면 표현식 (Null - Null)과 Null 값을 포함하는 표현식의 값을 계산하기 위한 일반 규칙을 얻는다는 것입니다. 가 적용되고 여기에서 Null 값이 동일한 변수에 해당한다는 사실에 대한 정보가 손실됩니다. 부울 이외의 연산을 계산할 때 Null 값은 다음과 같이 해석된다는 결론을 내릴 수 있습니다. 응용할 수 없는, 따라서 결과도 Null 값입니다. 비교 작업에서 Null 값을 사용하면 예상치 못한 결과가 발생합니다. 예를 들어 다음 표현식은 또한 예상되는 부울 True 또는 False 값 대신 Null 값을 생성합니다. (널 < 널); (없는 ≤ 없는); (널 = 널); (널 ≠ 널); (널 > 널); (널 ≥ 널) ≔ 널; 따라서 우리는 Null 값이 그 자체와 같거나 같지 않다고 말하는 것은 불가능하다는 결론을 내립니다. Null 값이 새로 나타날 때마다 독립적으로 처리되고 Null 값이 다른 알 수 없는 값으로 처리될 때마다 처리됩니다. 여기서 Null 값은 다른 모든 데이터 유형과 근본적으로 다릅니다. 이전에 전달된 모든 값과 해당 유형이 서로 같거나 같지 않다고 말하는 것이 안전하다는 것을 알고 있기 때문입니다. 따라서 Null 값은 일반적인 의미의 변수 값이 아님을 알 수 있습니다. 따라서 결과적으로 다음 예와 같이 부울 True 또는 False 값이 아니라 Null 값을 수신하므로 Null 값을 포함하는 변수 또는 표현식의 값을 비교하는 것이 불가능해집니다. (x < 널); (엑스 ≤ 없는); (x=널); (x ≠ 널); (x > 널); (x ≥ 널) ≔ 널; 따라서 빈 값과 유추하여 Null 값에 대한 표현식을 확인하려면 특수 술어를 사용해야 합니다. IsNull(<식>), 문자 그대로 "널"을 의미합니다. Boolean 함수는 표현식에 Null이 포함되거나 Null과 같으면 True를 반환하고 그렇지 않으면 False를 반환하지만 결코 Null을 반환하지 않습니다. IsNull 조건자는 모든 유형의 변수 및 식에 적용할 수 있습니다. 빈 유형의 표현식에 적용될 때 술어는 항상 False를 리턴합니다. 예를 들면 다음과 같습니다
따라서 실제로 첫 번째 경우에서 IsNull 술어를 XNUMX에서 가져왔을 때 출력이 False로 판명되었음을 알 수 있습니다. 두 번째 및 세 번째를 포함한 모든 경우에 논리 함수의 인수가 Null 값과 같을 때와 네 번째 경우에는 인수 자체가 처음에 Null 값과 같을 때 술어가 True를 반환했습니다. 4. Null 값과 논리 연산 일반적으로 데이터베이스 관리 시스템에서는 부정 ¬, 결합 & 및 분리 ∨의 세 가지 논리 연산만 직접 지원됩니다. 승계 ⇒ 및 등가 ⇔의 연산은 다음과 같이 대입을 사용하여 표현됩니다. (x ⇒ y) ≔ (¬x ∨ y); (x ⇔ y) ≔ (x ⇒ y) & (y ⇒ x); 이러한 대체는 Null 값을 사용할 때 완전히 보존됩니다. 흥미롭게도, 부정 연산자 "¬"를 사용하면 결합 및 분리 ∨ 연산 중 하나를 다음과 같이 표현할 수 있습니다. (x & y) ≔¬ (¬x ∨¬y); (x ∨ y) ≔ ¬(¬x & ¬y); 이러한 대체 및 이전 대체는 Null 값의 영향을 받지 않습니다. 이제 우리는 부정, 결합 및 분리의 논리 연산의 진리표를 제시하지만 일반적인 True 및 False 값 외에도 Null 값도 피연산자로 사용합니다. 편의를 위해 다음 표기법을 소개합니다. True 대신 t, False - f, Null - n 대신에 t를 작성합니다. 1. 부정 더블 엑스.
Null 값을 사용한 부정 연산과 관련하여 다음과 같은 흥미로운 점에 주목할 가치가 있습니다. 1) ¬¬x ≔ x - 이중 부정의 법칙; 2) ¬Null ≔ Null - Null 값은 고정 소수점입니다. 2. 접속 x & y.
이 작업에는 자체 속성도 있습니다. 1) x & y ≔ y & x - 교환성; 2) x & x ≔ x - 멱등 3) False & y ≔ False, 여기서 False는 흡수 요소입니다. 4) True & y ≔ y, 여기서 True는 중립 요소입니다. 3. 분리 x ∨ y.
특징 : 1) x ∨ y ≔ y ∨ x - 교환성; 2) x ∨ x ≔ x - 멱등성; 3) False ∨ y ≔ y, 여기서 False는 중성 요소입니다. 4) True ∨ y ≔ True, 여기서 True는 흡수 요소입니다. 일반 규칙의 예외는 동작 조건에서 논리 연산의 연결 및 분리 ∨를 계산하는 규칙입니다. 흡수 법칙: (False & y) ≔ (x & False) ≔ False; (참 ∨ y) ≔ (x ∨ 참) ≔ 참; 이러한 추가 규칙은 Null 값을 False 또는 True로 바꿀 때 결과가 여전히 이 값에 의존하지 않도록 공식화됩니다. 이전에 다른 유형의 연산에 대해 표시된 것처럼 부울 연산에서 Null 값을 사용하면 예기치 않은 값이 발생할 수도 있습니다. 예를 들어, 언뜻보기에 논리는 다음과 같습니다. 제XNUMX자의 배제의 법칙 (x ∨ ¬x) 및 반사의 법칙 (x = x), x ≔ Null에 대해 다음을 갖습니다. (x ∨ ¬x), (x = x) ≔ 널. 법이 시행되지 않습니다! 이것은 이전과 같은 방식으로 설명됩니다. Null 값이 표현식으로 대체되면 이 값이 동일한 변수에 의해 보고된다는 정보가 손실되고 Null 값 작업에 대한 일반 규칙이 적용됩니다. 따라서 우리는 결론을 내립니다. Null 값을 피연산자로 사용하여 논리 연산을 수행할 때 이러한 값은 데이터베이스 관리 시스템에 의해 다음과 같이 결정됩니다. 적용 가능하지만 알려지지 않은. 5. Null 값 및 조건 확인 따라서 위의 내용에서 데이터베이스 관리 시스템의 논리에는 Null 값도 가능한 논리 값 중 하나로 간주되기 때문에 두 개의 논리 값(True 및 False)이 아니라 세 개라는 결론을 내릴 수 있습니다. 그래서 흔히 미지의 값, 미지의 값이라고 합니다. 그러나 그럼에도 불구하고 데이터베이스 관리 시스템에서는 XNUMX값 논리만 구현됩니다. 따라서 Null 값이 있는 조건(정의되지 않은 조건)은 시스템에서 True 또는 False로 해석해야 합니다. 기본적으로 DBMS 언어는 Null 값이 False인 조건을 인식합니다. 데이터베이스 관리 시스템에서 조건부 If 및 While 문의 구현에 대한 다음 예를 통해 이를 설명합니다. P이면 A가 아니면 B입니다. 이 항목은 P가 True로 평가되면 조치 A가 수행되고 P가 False 또는 Null로 평가되면 조치 B가 수행됨을 의미합니다. 이제 이 연산자에 부정 연산을 적용하면 다음을 얻습니다. ¬P이면 B, 그렇지 않으면 A입니다. 차례로 이 연산자는 다음을 의미합니다. ¬P가 True로 평가되면 조치 B가 수행되고 ¬P가 False 또는 Null로 평가되면 조치 A가 수행됩니다. 그리고 다시 알 수 있듯이 Null 값이 나타나면 예기치 않은 결과가 발생합니다. 요점은 이 예제의 두 If 문이 동일하지 않다는 것입니다! 그 중 하나는 조건을 부정하고 가지를 재배열함으로써, 즉 표준 연산에 의해 다른 하나로부터 얻어지지만. 이러한 연산자는 일반적으로 동일합니다! 그러나 우리의 예에서 우리는 첫 번째 경우에 조건 P의 Null 값이 명령 B에 해당하고 두 번째 경우-A에 해당한다는 것을 알 수 있습니다. 이제 while 조건문의 동작을 고려하십시오. P가 A를 하는 동안; 비; 이 연산자는 어떻게 작동합니까? P가 True이면 작업 A가 실행되고 P가 False 또는 Null이면 작업 B가 실행됩니다. 그러나 Null 값이 항상 False로 해석되는 것은 아닙니다. 예를 들어 무결성 제약 조건에서 정의되지 않은 조건은 True로 인식됩니다(무결성 제약 조건은 입력 데이터에 부과되고 정확성을 보장하는 조건입니다). 이러한 제약 조건에서 의도적으로 잘못된 데이터만 거부되어야 하기 때문입니다. 그리고 다시, 데이터베이스 관리 시스템에는 특별한 대체 함수 IfNull(무결성 제약 조건, True), Null 값과 정의되지 않은 조건을 명시적으로 표현할 수 있습니다. 이 함수를 사용하여 조건부 If 및 While 문을 다시 작성해 보겠습니다. 1) IfNull( P, False)이면 A가 아니면 B입니다. 2) IfNull(P, False)이 A를 수행하는 동안; 비; 따라서 대체 함수 IfNull(expression 1, expression 2)은 Null 값을 포함하지 않는 경우 첫 번째 표현식의 값을 반환하고 그렇지 않은 경우 두 번째 표현식의 값을 반환합니다. IfNull 함수가 반환하는 표현식의 유형에는 제한이 없습니다. 따라서 이 함수를 사용하면 Null 값 작업에 대한 모든 규칙을 명시적으로 재정의할 수 있습니다. 강의 #3. 관계형 데이터 객체 1. 관계 표현의 표 형식에 대한 요구 사항 1. 관계 표현의 표 형식에 대한 첫 번째 요구 사항은 유한성입니다. 무한 테이블, 관계 또는 데이터의 다른 표현 및 구성으로 작업하는 것은 불편하고, 소비된 노력이 거의 정당화되지 않으며, 더욱이 이 방향은 실질적으로 거의 적용되지 않습니다. 그러나 이 외에도 예상대로 다른 요구 사항이 있습니다. 2. 관계를 나타내는 표의 머리글은 반드시 한 줄로 구성되어야 합니다. 열의 머리글은 고유한 이름을 사용합니다. 다단계 헤더는 허용되지 않습니다. 예를 들면 다음과 같습니다.
모든 다중 계층 제목은 적절한 제목을 선택하여 단일 계층 제목으로 대체됩니다. 이 예에서 지정된 변환 후의 테이블은 다음과 같습니다.
각 열의 이름이 고유하므로 원하는 대로 바꿀 수 있습니다. 즉, 순서가 무의미해집니다. 그리고 이것은 세 번째 속성이기 때문에 매우 중요합니다. 3. 행의 순서는 중요하지 않아야 합니다. 그러나 이 요구 사항도 엄격하게 제한되지 않습니다. 모든 테이블이 필요한 형식으로 쉽게 축소될 수 있기 때문입니다. 예를 들어, 행의 순서를 결정하는 추가 열을 입력할 수 있습니다. 이 경우 줄을 재배열해도 아무 것도 변경되지 않습니다. 다음은 그러한 테이블의 예입니다.
4. 관계를 나타내는 테이블에 중복 행이 없어야 합니다. 테이블에 중복 행이 있는 경우 각 행의 중복 수를 담당하는 추가 열을 도입하여 쉽게 수정할 수 있습니다. 예를 들면 다음과 같습니다.
다음 속성은 관계형 데이터베이스 프로그래밍 및 설계의 모든 원칙의 기초가 되기 때문에 매우 기대됩니다. 5. 모든 열의 데이터는 동일한 유형이어야 합니다. 또한 단순 유형이어야 합니다. 단순 데이터 유형과 복합 데이터 유형이 무엇인지 설명하겠습니다. 단순 데이터 유형은 데이터 값이 비복합, 즉 구성 요소를 포함하지 않는 유형입니다. 따라서 목록, 배열, 트리 또는 이와 유사한 복합 개체가 테이블의 열에 없어야 합니다. 그러한 객체는 복합 데이터 유형 - 관계형 데이터베이스 관리 시스템에서는 그 자체가 독립적인 테이블 관계의 형태로 표시됩니다. 2. 도메인 및 속성 도메인과 속성은 데이터베이스 생성 및 관리 이론의 기본 개념입니다. 그것이 무엇인지 설명합시다. 공식적으로, 속성 도메인 (표시 돔(a)), 여기서 a는 속성이며, 해당 속성 a와 동일한 유형의 유효한 값 집합으로 정의됩니다. 이 유형은 단순해야 합니다. dom(a) ⊆ {x | 유형(x) = 유형(a)}; 속성 (a)는 속성 이름 name(a)과 속성 도메인 dom(a)으로 구성된 순서 쌍으로 차례로 정의됩니다. 즉: a = (이름(a): dom(a)); 이 정의는 일반적인 "," 대신 ":"를 사용합니다(표준 순서 쌍 정의에서와 같이). 이것은 속성의 도메인과 속성의 데이터 유형의 연관을 강조하기 위해 수행됩니다. 다음은 다양한 속성의 몇 가지 예입니다. а1 = (과정: {1, 2, 3, 4, 5}); а2 = (MassaKg: {x | 유형(x) = 실수, x 0}); а3 = (길이Sm: {x | 유형(x) = 실수, x 0}); 속성 a2 그리고3 도메인이 형식적으로 일치합니다. 그러나 이러한 속성의 의미론적 의미는 다릅니다. 왜냐하면 질량과 길이의 값을 비교하는 것은 의미가 없기 때문입니다. 따라서 속성 도메인은 유효한 값의 유형뿐만 아니라 의미론적 의미와도 연관됩니다. 테이블 형식의 관계에서 속성은 테이블의 열 머리글로 표시되며 속성의 도메인은 지정되지 않고 암시됩니다. 다음과 같습니다.
각 헤더가 여기에 있음을 쉽게 알 수 있습니다.1은2은3 관계를 나타내는 테이블의 열은 별도의 속성입니다. 3. 관계의 계획. 명명된 값 튜플 DBMS의 이론과 실제에서 관계 스키마의 개념과 속성에 대한 튜플의 명명된 값은 기본입니다. 데려가자. 관계 체계 (표시 S)는 고유한 이름을 가진 유한한 속성 집합으로 정의됩니다. 예: S = {a | ∈ S}; 관계를 나타내는 각 테이블에서 모든 열 머리글(모든 속성)은 관계의 스키마에 결합됩니다. 관계 스키마의 속성 수는 다음을 결정합니다. 도 그것 관계 집합의 카디널리티로 표시됩니다. |S|. 관계 스키마는 관계 스키마 이름과 연관될 수 있습니다. 표 형식의 관계 표현에서 쉽게 볼 수 있듯이 관계 스키마는 열 머리글 행에 불과합니다.
에스 = {a1은2은3은4} - 이 테이블의 관계 스키마. 관계 이름은 테이블의 도식 제목으로 표시됩니다. 텍스트 형식에서 관계 스키마는 속성 이름의 명명된 목록으로 나타낼 수 있습니다. 예를 들면 다음과 같습니다. 학생(교과서 번호, 성, 이름, 애칭, 생년월일). 여기에서는 표 형식과 같이 속성 도메인이 지정되지 않고 암시됩니다. 관계의 스키마도 비어 있을 수 있다는 정의에서 따릅니다(S = ∅). 사실, 이것은 실제로 데이터베이스 관리 시스템이 빈 관계 스키마의 생성을 허용하지 않기 때문에 이론상으로만 가능합니다. 속성의 명명된 튜플 값 (표시 고마워))은 속성 이름과 속성 값으로 구성된 순서 쌍으로 속성과 유추하여 정의됩니다. 예: t(a) = (이름(a) : x), x ∈ dom(a); 속성 값이 속성 도메인에서 가져온 것을 볼 수 있습니다. 관계의 테이블 형식에서 속성에 대한 튜플의 각 명명된 값은 해당 테이블 셀입니다.
여기서 t(a1), t(아2), t(아3) - 속성 a에 대한 튜플 t의 명명된 값1과2과3. 속성에 대한 명명된 튜플 값의 가장 간단한 예: (과정: 5), (점수: 5); 여기서 Course와 Score는 각각 두 속성의 이름이고 5는 해당 도메인에서 가져온 값 중 하나입니다. 물론 이러한 값은 두 경우 모두 동일하지만 두 경우 모두에서 이러한 값의 집합이 서로 다르기 때문에 의미적으로 다릅니다. 4. 튜플. 튜플 유형 데이터베이스 관리 시스템에서 튜플의 개념은 다양한 속성에 대한 튜플의 명명된 값에 대해 이야기할 때 이전 단락에서 이미 직관적으로 찾을 수 있습니다. 그래서, 튜플 (표시 t, 영어로부터. 튜플 - "튜플") 관계 체계 S가 있는 것은 이 관계 체계 S에 포함된 모든 속성에 대해 이 튜플의 명명된 값 집합으로 정의됩니다. 즉, 속성은 다음에서 가져옵니다. 튜플의 범위, def(t), 즉.: t ≡ t(S) = {t(a) | ∈ def(t) ⊆ S;. 하나 이상의 속성 값이 하나의 속성 이름과 일치하지 않아야 한다는 것이 중요합니다. 관계의 테이블 형식에서 튜플은 테이블의 모든 행이 됩니다. 즉, 다음과 같습니다.
여기 t1(에스) = {t(a1), t(아2), t(아3), t(아4)} 및 t2(에스) = {t(a5), t(아6), t(아7), t(아8)} - 튜플. DBMS의 튜플은 다음과 같이 다릅니다. 유형 정의 영역에 따라 다릅니다. 튜플은 다음과 같이 호출됩니다. 1) 부분적인, 정의 영역이 관계의 스키마에 포함되거나 일치하는 경우, 즉 def(t) ⊆ S. 이것은 데이터베이스 실습에서 일반적인 경우입니다. 2) 완전한, 정의 영역이 완전히 일치하는 경우 관계 체계와 동일합니다. 즉, def(t) = S; 3) 불완전한, 정의 영역이 관계 체계에 완전히 포함된 경우, 즉 def(t) ⊂ S; 4) 어디에도 정의되지 않은, 정의 영역이 빈 집합과 같은 경우, 즉 def(t) = ∅. 예를 들어 설명하겠습니다. 다음 표와 같은 관계가 있다고 가정해 보겠습니다.
여기 t 하자1 = {10, 20, 30}, t2 = {10, 20, 널}, t3 = {널, 널, 널}. 그러면 튜플 t가1 - 정의 영역이 def(t)이므로 완전함1) = {a, b, c} = S. 튜플 t2 - 불완전한, def(t2) = { a, b} ⊂ S. 마지막으로 튜플 t3 - def(t3) = ∅이므로 어디에도 정의되지 않음. 어디에도 정의되지 않은 튜플은 빈 집합이지만 관계 체계와 관련되어 있음에 유의해야 합니다. 때때로 아무데도 정의되지 않은 튜플은 ∅(S)로 표시됩니다. 위의 예에서 이미 보았듯이 이러한 튜플은 Null 값으로만 구성된 테이블 행입니다. 흥미롭게도, 유사한, 즉 같음은 동일한 관계 스키마를 가진 튜플일 뿐입니다. 따라서 예를 들어 서로 다른 관계 체계를 가진 두 개의 아무데도 정의되지 않은 튜플은 예상대로 같지 않을 것입니다. 그들은 그들의 관계 패턴처럼 다를 것입니다. 5. 관계. 관계 유형 그리고 마지막으로 관계를 피라미드의 일종으로 정의하고 이전의 모든 개념으로 구성됩니다. 그래서, 태도 (표시 r, 영어로부터. 관계)와 관계 스키마 S는 동일한 관계 스키마 S를 갖는 필연적으로 유한한 튜플 집합으로 정의됩니다. 따라서: r ≡ r(S) = {t(S) | ∈r}; 관계 체계와 유추하여 관계의 튜플 수를 관계의 힘 집합의 카디널리티로 표시됩니다. |r|. 튜플과 같은 관계는 유형이 다릅니다. 따라서 관계는 다음과 같습니다. 1) 부분적인, 관계에 포함된 튜플에 대해 다음 조건이 충족되는 경우: [def(t) ⊆ S]. 이것은 (튜플과 마찬가지로) 일반적인 경우입니다. 2) 완전한, 만일의 경우 ∀t ∈ r(S) [def(t) = S]; 3) 불완전한, 만약 ∃t ∈ r(S) def(t) ⊂ S; 4) 어디에도 정의되지 않은, 만약 ∀t ∈ r(S) [def(t) = ∅]. 어디에도 정의되지 않은 관계에 특별한 주의를 기울이자. 튜플과 달리 이러한 관계로 작업하려면 약간의 미묘함이 필요합니다. 요점은 아무데도 정의되지 않은 관계가 두 가지 유형이 될 수 있다는 것입니다. 비어 있거나 아무데도 정의되지 않은 단일 튜플을 포함할 수 있습니다(이러한 관계는 {∅(S)}로 표시됨). 유사한 (튜플과의 유추에 의해), 즉, 아마도 같음은 동일한 관계 스키마를 가진 관계일 뿐입니다. 따라서 관계 패턴이 다른 관계는 다릅니다. 표 형식에서 관계는 표의 본문으로, 행 - 열의 표제, 즉 문자 그대로 표제를 포함하는 첫 번째 행과 함께 전체 표가 해당합니다. 강의 4. 관계 대수학. 단항 연산 관계대수학는 짐작할 수 있듯이 관계형 데이터 모델, 즉 관계에 대해 모든 작업이 수행되는 특별한 유형의 대수입니다. 테이블 형식의 관계에는 행, 열 및 행(열의 머리글)이 포함됩니다. 따라서 자연 단항 연산은 특정 행이나 열을 선택하고 열 머리글을 변경하는 작업(속성 이름 바꾸기)입니다. 1. 단항 선택 연산 우리가 살펴볼 첫 번째 단항 연산은 가져오기 작업 - 어떤 원칙에 따라 관계를 나타내는 테이블에서 행을 선택하는 작업, 즉 특정 조건 또는 조건을 충족하는 행-튜플을 선택합니다. 가져오기 연산자 σ로 표시 , 샘플링 조건 - P , 즉 연산자 σ는 항상 튜플 P에 대한 특정 조건으로 취해지며 조건 P 자체는 관계 S의 체계에 따라 작성됩니다. 이 모든 것을 고려하면, 가져오기 작업 관계 r과 관련된 관계 S의 계획은 다음과 같습니다. σ r(S) ≡ σ r = {t(S) |t ∈ r & P t} = {t(S) |t ∈ r & IfNull(P t, False}; 이 연산의 결과는 선택 조건 P t 를 만족하는 원래 관계 피연산자의 튜플 t(S)로 구성된 동일한 관계 스키마 S를 가진 새로운 관계가 될 것입니다. 어떤 종류의 조건을 튜플에 적용하려면 속성 이름 대신 튜플 속성 값을 대체해야 함은 분명합니다. 이 작업이 어떻게 작동하는지 더 잘 이해하기 위해 예를 살펴보겠습니다. 다음 관계 체계가 주어집니다. S: 세션(성적번호, 성, 과목, 학년). 다음과 같이 선택 조건을 취하자. P = (주제 = '컴퓨터 과학' 및 평가 > 3). "Computer Science" 과목을 최소 XNUMX점 통과한 학생에 대한 정보를 포함하는 튜플을 초기 관계 피연산자에서 추출해야 합니다. 또한 이 관계에서 다음 튜플이 주어집니다. t0(S) ∈ r(S): {(성적 번호: 100), (성: 'Ivanov'), (주제: '데이터베이스'), (점수: 5)}; 튜플 t에 선택 조건 적용하기0, 우리는 다음을 얻습니다: P t0 = ('데이터베이스' = '컴퓨터 과학' 및 5 > 3); 이 특정 튜플에서 선택 조건이 충족되지 않습니다. 일반적으로 이 특정 샘플의 결과 σ<과목 = '컴퓨터 과학' 및 학년 > 3 > 세션 선택 조건을 충족하는 행이 남아 있는 "세션" 테이블이 있습니다. 2. 단항 투영 연산 우리가 공부할 또 다른 표준 단항 연산은 투영 연산입니다. 투영 작업 어떤 속성에 따라 관계를 나타내는 테이블에서 열을 선택하는 작업입니다. 즉, 기계는 투영에 지정된 원래 피연산자 관계의 속성(즉, 문자 그대로 해당 열)을 선택합니다. 투영 연산자 [S'] 또는 π로 표시 . 여기서 S'는 관계 S의 원래 스키마, 즉 일부 열의 하위 스키마입니다. 이것은 무엇을 의미 하는가? 이는 투영 조건이 충족된 S'에 해당 속성만 남아 있기 때문에 S'가 S보다 더 적은 속성을 가짐을 의미합니다. 그리고 관계 r(S' )을 나타내는 테이블에는 테이블 r(S)만큼 행이 있고 나머지 속성에 해당하는 것만 남아 있기 때문에 열은 적습니다. 따라서 관계 r(S)에 적용된 투영 연산자 π< S'>는 원래의 튜플의 투영 t(S) [S' ]로 구성된 다른 관계 체계 r(S')을 가진 새로운 관계를 생성합니다. 관계. 이러한 튜플 프로젝션은 어떻게 정의됩니까? 투사 하위 회로 S'에 대한 원래 관계 r(S)의 튜플 t(S)는 다음 공식에 의해 결정됩니다. t(S) [S'] = {t(a)|a ∈ def(t) ∩ S'}, S' ⊆S. 중복 튜플은 결과에서 제외된다는 점에 유의하는 것이 중요합니다. 즉, 새 튜플을 나타내는 테이블에 중복 행이 없습니다. 위의 모든 사항을 염두에 두고 데이터베이스 관리 시스템 측면에서 투영 작업은 다음과 같습니다. 파이 r(S) ≡ π r ≡ r(S) [S'] ≡ r [S' ] = {t(S) [S'] | ∈ r}; 가져오기 작업이 작동하는 방식을 보여주는 예를 살펴보겠습니다. 관계 "세션"과 이 관계의 체계가 주어졌다고 하자: S: 세션(교과서 번호, 성, 과목, 학년); 이 체계의 두 가지 속성, 즉 학생의 "성적부 #" 및 "성"에만 관심이 있으므로 S' 하위 스키마는 다음과 같습니다. S': (기록부 번호, 성). 초기 관계 r(S)를 하위 회로 S'에 투영해야 합니다. 다음으로 튜플 t가 주어집니다.0(S) 원래 관계에서: t0(S) ∈ r(S): {(성적 번호: 100), (성: 'Ivanov'), (주제: '데이터베이스'), (점수: 5)}; 따라서 주어진 하위 회로 S'에 대한 이 튜플의 투영은 다음과 같습니다. t0(S) S': {(계좌번호: 100), (성: 'Ivanov')}; 테이블 측면에서 프로젝션 작업에 대해 이야기하는 경우 원래 관계의 프로젝션 세션 [성적 번호, 성]은 성적부 번호와 성을 제외한 모든 열이 삭제되는 세션 테이블입니다. 또한 모든 중복 행도 제거되었습니다. 3. 단항 이름 바꾸기 연산 그리고 우리가 살펴볼 마지막 단항 연산은 속성 이름 바꾸기 작업. 관계를 테이블로 이야기하면 전체 또는 일부 열의 이름을 변경하기 위해 이름 바꾸기 작업이 필요합니다. 이름 바꾸기 연산자 ρ<φ>, 여기서 φ - 이름 바꾸기 기능. 이 함수는 스키마 속성 이름 S와 Ŝ 사이에 일대일 대응을 설정합니다. 여기서 각각 S는 원래 관계의 스키마이고 Ŝ는 이름이 변경된 속성이 있는 관계의 스키마입니다. 따라서 관계 r(S)에 적용된 연산자 ρ<φ>는 이름이 변경된 속성만 있는 원래 관계의 튜플로 구성된 스키마 Ŝ와 새로운 관계를 제공합니다. 데이터베이스 관리 시스템 측면에서 속성 이름 변경 작업을 작성해 보겠습니다. ρ<φ> r(S) ≡ ρ<φ>r = {ρ<φ> t(S)| ∈ r}; 다음은 이 작업을 사용하는 예입니다. 다음과 같은 방식으로 이미 우리에게 친숙한 Session 관계를 고려해 보겠습니다. S: 세션(교과서 번호, 성, 과목, 학년); 기존 속성 대신 보고 싶은 다른 속성 이름을 사용하여 새로운 관계 스키마 Ŝ를 도입하겠습니다. Ŝ : (번호 ZK, 성, 주제, 점수); 예를 들어 데이터베이스 고객이 기본 관계에서 다른 이름을 보고 싶어했습니다. 이 순서를 구현하려면 다음 이름 바꾸기 기능을 설계해야 합니다. φ : (계좌번호, 성, 과목, 학년) → (ZK번호, 성, 과목, 점수); 실제로 두 개의 속성만 이름을 바꾸면 되므로 현재 함수 대신 다음 이름 바꾸기 함수를 작성하는 것이 좋습니다. φ : (기록부 수, 등급) → (No. ZK, 점수); 또한 Session 관계에 속한 이미 친숙한 튜플도 제공합니다. t0(S) ∈ r(S): {(성적 번호: 100), (성: 'Ivanov'), (주제: '데이터베이스'), (점수: 5)}; 이 튜플에 이름 바꾸기 연산자를 적용합니다. ρ<φ>t0(S): {(ZK#: 100), (성: 'Ivanov'), (제목: '데이터베이스'), (점수: 5)}; 따라서 이것은 속성의 이름이 변경된 관계의 튜플 중 하나입니다. 표로 표현하면 비율 ρ < 성적부 번호, 등급 → "아니. ZK, 스코어 > 세션 - 이것은 지정된 속성의 이름을 변경하여 "세션" 관계 테이블에서 얻은 새 테이블입니다. 4. 단항 연산의 속성 다른 연산과 마찬가지로 단항 연산에는 특정 속성이 있습니다. 그 중 가장 중요한 것을 생각해 봅시다. 선택, 투영 및 이름 변경의 단항 연산의 첫 번째 속성은 관계의 카디널리티 비율을 특성화하는 속성입니다. (카디널리티는 하나 또는 다른 관계의 튜플 수임을 기억하십시오.) 여기에서 초기 관계와 하나 또는 다른 작업을 적용한 결과 얻은 관계를 각각 고려하고 있음이 분명합니다. 단항 연산의 모든 속성은 정의에서 직접 따르므로 쉽게 설명할 수 있고 원하는 경우 독립적으로 추론할 수도 있습니다. 그래서 : 1) 전력 비율: a) 선택 작업의 경우: | σ r |≤ |r|; b) 투영 작업의 경우: | r[S'] | ≤ |r|; c) 이름 바꾸기 작업의 경우: | ρ<φ>r | = |r|; 전체적으로 두 연산자, 즉 선택 연산자와 투영 연산자의 경우 원래 관계의 힘 - 피연산자는 해당 연산을 적용하여 원래 관계에서 얻은 관계의 힘보다 큽니다. 이는 이 두 가지 선택 및 프로젝트 작업에 수반되는 선택에서 선택 조건을 충족하지 않는 일부 행 또는 열이 제외되기 때문입니다. 모든 행 또는 열이 조건을 만족하는 경우 거듭제곱(즉, 튜플의 수)의 감소가 없으므로 수식의 부등식이 엄격하지 않습니다. 이름 변경 작업의 경우 이름을 변경할 때 관계에서 튜플이 제외되지 않기 때문에 관계의 힘은 변경되지 않습니다. 2) 멱등 속성: a) 샘플링 작업의 경우: σ σ r = σ ; b) 투영 작업의 경우: r [S'] [S'] = r [S']; c) 이름 변경 작업의 경우 일반적으로 멱등 속성이 적용되지 않습니다. 이 속성은 관계에 동일한 연산자를 두 번 연속으로 적용하는 것은 한 번 적용하는 것과 동일함을 의미합니다. 일반적으로 관계 속성의 이름을 바꾸는 작업의 경우 이 속성을 적용할 수 있지만 특별한 예약 및 조건이 있습니다. 멱등성의 속성은 표현식의 형식을 단순화하고 보다 경제적이고 실제적인 형식으로 가져오기 위해 매우 자주 사용됩니다. 그리고 우리가 고려할 마지막 속성은 단조성의 속성입니다. 어떤 조건에서도 세 연산자 모두 단조롭다는 점은 흥미롭습니다. 3) 단조성 속성: a) 가져오기 작업의 경우: r1 ⊆ r2 ⇒σ 아르 자형1 ⇒ σ 아르 자형2; b) 투영 작업의 경우: r1 ⊆ r2 ⇒ r1[에스'] ⊆ r2 [에스']; c) 이름 바꾸기 작업의 경우: r1 ⊆ r2 ⇒ ρ<φ>r1 ⊆ ρ<φ>r2; 관계 대수에서 단조성의 개념은 일반 일반 대수의 동일한 개념과 유사합니다. 명확히 하자: 초기에 관계 r1 그리고 r2 r ⊆ r2, 그러면 세 가지 선택, 투영 또는 이름 바꾸기 연산자 중 하나를 적용한 후에도 이 관계가 유지됩니다. 강의 번호 5. 관계 대수학. 이진 연산 1. 합집합, 교집합, 차이의 연산 모든 작업에는 표현과 동작이 의미를 잃지 않도록 준수해야 하는 고유한 적용 가능성 규칙이 있습니다. 합집합, 교집합, 차이의 이진 집합이론적 연산은 반드시 동일한 관계 스키마를 갖는 두 관계에만 적용될 수 있다. 이러한 이진 연산의 결과는 연산 조건을 충족하지만 피연산자와 동일한 관계 체계를 갖는 튜플로 구성된 관계가 됩니다. 1. 결과 노동 조합 운영 두 관계 r1(S) 및 r2(S) 새로운 관계가 있을 것입니다 r3(S) 관계 튜플로 구성된 r1(S) 및 r2(S) 원래 관계 중 하나 이상에 속하고 관계 스키마가 동일한 것. 따라서 두 관계의 교집합은 다음과 같습니다. r3(에스) = r1(에) r2(S) = {t(S) | ∈r1 ∪∈r2}; 명확성을 위해 다음은 표와 관련된 예입니다. 두 가지 관계가 주어집니다. r1(에스):
r2(에스):
우리는 첫 번째와 두 번째 관계의 체계가 동일하다는 것을 알 수 있습니다. 단지 서로 다른 수의 튜플이 있을 뿐입니다. 이 두 관계의 합집합은 관계 r이 됩니다.3(S), 다음 표에 해당합니다. r3(S) = r1(에) r2(에스):
따라서 릴레이션 S의 스키마는 변경되지 않고 튜플의 수만 증가했습니다. 2. 다음 이진 연산에 대한 고려로 넘어 갑시다. 교차로 작업 두 가지 관계. 학교 기하학에서 알 수 있듯이 결과 관계에는 두 관계 r에 동시에 존재하는 원래 관계의 튜플만 포함됩니다.1(S) 및 r2(S) (다시, 동일한 관계 패턴에 유의하십시오). 두 관계의 교차 작업은 다음과 같습니다. r4(에스) = r1(S) ∩r2(S) = {t(S) | ∈ r1 & ∈ r2}; 그리고 다시 테이블 형태로 제시된 관계에 대한 이 작업의 영향을 고려하십시오. r1(에스):
r2(에스):
관계의 교집합에 의한 연산의 정의에 따르면 r1(S) 및 r2(S) 새로운 관계가 있을 것입니다 r4(S), 테이블 보기는 다음과 같습니다. r4(에스) = r1(S) ∩r2(에스):
실제로 첫 번째 및 두 번째 초기 관계의 튜플을 살펴보면 그 중 하나의 공통된 항목이 있습니다. {b, 2}. 새로운 관계 r의 유일한 튜플이 되었습니다.4(에스). 3. 차분 연산 두 개의 관계는 이전 작업과 유사한 방식으로 정의됩니다. 이전 작업에서와 같이 피연산자 관계는 동일한 관계 체계를 가져야 하며 결과 관계는 두 번째 관계에 없는 첫 번째 관계의 모든 튜플을 포함합니다. r5(에스) = r1(중)\r2(S) = {t(S) | ∈ r1 & t ∉ r2}; 이미 잘 알려진 관계 r1(S) 및 r2(S), 다음과 같은 표 보기에서: r1(에스):
r2(에스):
두 관계의 교집합 연산에서 두 피연산자를 모두 고려할 것입니다. 그런 다음 이 정의에 따라 결과 관계 r5(S)는 다음과 같습니다. r5(에스) = r1(중)\r2(에스):
고려되는 이진 연산은 기본이고 다른 연산, 더 복잡한 연산은 이를 기반으로 합니다. 2. 데카르트 곱과 자연 조인 연산 데카르트 곱 연산과 자연 조인 연산은 곱 유형의 이진 연산이며 앞에서 논의한 두 관계 연산의 합집합을 기반으로 합니다. 데카르트 곱 연산의 동작이 많은 사람들에게 친숙해 보일 수 있지만, 첫 번째 연산보다 더 일반적인 경우이므로 자연 곱 연산부터 시작하겠습니다. 따라서 자연 조인 작업을 고려하십시오. 이 작업의 피연산자는 합집합, 교차 및 이름 변경의 세 가지 이진 연산과 달리 다른 체계와의 관계가 될 수 있다는 점에 즉시 유의해야 합니다. 우리가 다른 관계 체계를 가진 두 개의 관계를 고려한다면 r1(S1) 및 r2(S2), 그들의 천연 화합물 새로운 관계 r이있을 것입니다3(S3), 이는 관계 체계의 교차점과 일치하는 피연산자의 튜플로만 구성됩니다. 따라서 새로운 관계의 계획은 연결, "접착"이기 때문에 원래 관계의 관계 계획보다 클 것입니다. 그건 그렇고,이 "접착"이 발생하는 두 피연산자 관계에서 동일한 튜플을 호출합니다 연결 가능한. 데이터베이스 관리 시스템의 공식 언어로 자연 조인 작업의 정의를 작성해 보겠습니다. r3(S3) = r1(S1)xr2(S2) = {t(에스1 ∪S2) | t[에스1] ∈r1 &t(S2) ∈r2}; 자연스러운 연결의 작업인 "접착"을 잘 보여주는 예를 살펴보겠습니다. 두 관계 r1(S1) 및 r2(S2), 표 형식의 표현에서 각각 다음과 같습니다. r1(S1):
r2(S2):
우리는 이러한 관계가 계획 S의 교차점에서 일치하는 튜플을 가지고 있음을 알 수 있습니다.1 그리고 S2 처지. 다음과 같이 나열해 보겠습니다. 1) 관계 r의 튜플 {a, 1}1(S1)는 관계 r의 튜플 {1, x}와 일치합니다.2(S2); 2) r의 튜플 {b, 1}1(S1) 또한 r의 튜플 {1, x}와 일치합니다.2(S2); 3) 튜플 {c, 3}은 튜플 {3, z}와 일치합니다. 따라서 자연 조인에서 새 관계 r3(S3)는 이 튜플에 정확히 "접착"하여 얻습니다. 그래서 r3(S3) 테이블 보기에서 다음과 같이 표시됩니다. r3(S3) = r1(S1)xr2(S2):
그것은 정의에 의해 밝혀졌습니다 : 계획 S3 계획 S와 일치하지 않습니다1, 계획 S와 함께도2, 우리는 자연 조인을 얻기 위해 튜플을 교차하여 두 개의 원래 스키마를 "접착"했습니다. 자연 조인 연산을 적용할 때 튜플이 어떻게 조인되는지 도식적으로 보여드리겠습니다. 관계 r1 조건부 형식이 있습니다.
그리고 비율 r2 - 보다:
그러면 그들의 자연스러운 연결은 다음과 같을 것입니다.
우리는 관계 피연산자의 "접착"이 예를 고려하여 이전에 제공한 것과 동일한 체계에 따라 발생함을 알 수 있습니다. 운전 데카르트 연결 자연 조인 작업의 특별한 경우입니다. 보다 구체적으로, 관계에 대한 데카르트 곱 연산의 영향을 고려할 때, 우리는 이 경우 교차하지 않는 관계 체계에 대해서만 이야기할 수 있다고 의도적으로 규정합니다. 두 연산을 모두 적용한 결과 피연산자 관계 스키마의 합집합과 동일한 스키마 관계가 얻어지고 피연산자의 스키마는 어떤 경우에도 교차하지 않아야 하기 때문에 가능한 모든 쌍의 튜플만 두 관계의 데카르트 곱에 속합니다. 따라서 전술한 내용을 기반으로 데카르트 곱 연산에 대한 수학 공식을 작성합니다. r4(S4) = r1(S1)xr2(S2) = {t(에스1 ∪ ㅅ2) | t[S1] ∈r1 &t(S2) ∈r2}, 에스1 ∩ 에스2= ∅; 이제 데카르트 곱 연산을 적용할 때 결과 관계 스키마가 어떻게 보이는지 보여주는 예를 살펴보겠습니다. 두 관계 r1(S1) 및 r2(S2), 다음과 같이 표 형식으로 표시됩니다. r1(S1):
r2(S2):
그래서 우리는 관계 r의 튜플이 하나도 없다는 것을 알 수 있습니다.1(S1) 및 r2(S2), 실제로 교차점에서 일치하지 않습니다. 따라서 결과 관계 r에서4(S4) 첫 번째 및 두 번째 피연산자 관계의 모든 가능한 튜플 쌍이 떨어집니다. 얻다: r4(S4) = r1(S1)xr2(S2):
우리는 새로운 관계 체계 r을 얻었습니다.4(S4) 이전의 경우와 같이 튜플을 "접착"하는 것이 아니라 원래 체계의 교차점에서 일치하지 않는 가능한 모든 다른 튜플 쌍의 열거에 의한 것입니다. 다시 자연 조인의 경우와 같이 데카르트 곱 연산의 개략적인 예를 제시합니다. 하자 r1 다음과 같이 설정합니다.
그리고 비율 r2 주어진:
그러면 이들의 데카르트 곱은 다음과 같이 개략적으로 나타낼 수 있습니다.
이런 식으로 데카르트 곱 연산을 적용할 때 결과 관계가 얻어집니다. 3. 이진 연산의 속성 합집합, 교집합, 차, 데카르트 곱, 자연 조인의 이항 연산에 대한 위의 정의에서 속성이 따릅니다. 1. 단항 연산의 경우와 같이 첫 번째 속성은 다음을 보여줍니다. 전력비 처지: 1) 통합 작업의 경우: |r1 ∪r2| ≤ |r1| + |r2|; 2) 교차 작업의 경우: |r1 ∩r2 | ≤ 분(|r1|, |r2|); 3) 차이 연산의 경우: |r1 \아르 자형2| ≤ |r1|; 4) 데카르트 곱 연산의 경우: |r1 xr2| = |r1| |r2|; 5) 자연 조인 작업의 경우: |r1 xr2| ≤ |r1| |r2|. 거듭제곱의 비율은 하나 또는 다른 작업을 적용한 후 관계의 튜플 수가 어떻게 변경되는지를 특징으로 합니다. 그래서 우리는 무엇을 볼 수 있습니까? 힘 협회들 두 관계 r1 그리고 r2 원래 관계 피연산자의 카디널리티 합보다 작습니다. 왜 이런 일이 발생합니까? 문제는 병합할 때 일치하는 튜플이 사라지고 서로 겹친다는 것입니다. 따라서 이 작업을 거친 후 고려한 예를 참조하면 첫 번째 관계에는 두 개의 튜플이 있었고 두 번째에는 2개의 튜플이 있었고 결과에는 XNUMX개, 즉 XNUMX개 미만(합 관계 피연산자의 카디널리티 ). 일치하는 튜플 {b, XNUMX}에 의해 이러한 관계는 "함께 연결"됩니다. 결과 전력 교차로 두 관계가 원래 피연산자 관계의 최소 카디널리티보다 작거나 같습니다. 이 작업의 정의를 살펴보겠습니다. 두 초기 관계에 있는 튜플만 결과 관계에 들어갑니다. 이것은 새로운 관계의 카디널리티가 튜플 수가 둘 중 가장 작은 관계 피연산자의 카디널리티를 초과할 수 없음을 의미합니다. 그리고 결과의 거듭제곱은 이 최소 카디널리티와 같을 수 있습니다. 낮은 카디널리티를 가진 관계의 모든 튜플이 두 번째 관계 피연산자의 일부 튜플과 일치하는 경우 항상 허용되기 때문입니다. 수술의 경우 차이 모든 것이 아주 사소합니다. 실제로, 두 번째 관계에도 존재하는 모든 튜플이 첫 번째 관계 피연산자에서 "차감"되면 해당 수(및 결과적으로 해당 전력)가 감소합니다. 첫 번째 릴레이션의 단일 튜플이 두 번째 릴레이션의 어떤 튜플과도 일치하지 않는 경우, 즉 "빼기"할 항목이 없는 경우, 그 힘은 감소하지 않습니다. 흥미롭게도 수술을 하면 데카르트 곱 결과 관계의 거듭제곱은 두 피연산자 관계의 거듭제곱의 곱과 정확히 같습니다. 이것은 원래 관계의 모든 가능한 튜플 쌍이 결과에 기록되고 아무 것도 제외되지 않기 때문에 발생하는 것이 분명합니다. 그리고 마지막으로 수술 자연스러운 연결 그 힘이 원래의 두 관계의 힘의 곱보다 크거나 같은 관계가 얻어진다. 다시 말하지만, 이것은 피연산자 관계가 일치하는 튜플에 의해 "함께 연결"되고 일치하지 않는 것은 결과에서 완전히 제외되기 때문에 발생합니다. 2. 멱등성 속성: 1) 합집합 연산: r ∪ r = r; 2) 교차 연산의 경우: r ∩ r = r; 3) 차분 연산의 경우: r \ r ≠ r; 4) 데카르트 곱 연산의 경우(일반적인 경우 속성이 적용되지 않음) 5) 자연 조인 연산의 경우: rxr = r. 흥미롭게도 멱등성의 속성은 위의 모든 연산에 해당되지 않으며 데카르트 곱의 연산에는 전혀 적용되지 않습니다. 실제로 어떤 관계도 결합하거나 교차하거나 자연스럽게 연결하면 변경되지 않습니다. 그러나 정확히 동일한 관계에서 빼면 결과는 빈 관계가 됩니다. 3. 교환 속성: 1) 통합 작업의 경우: r1 ∪r2 = r2 ∪r1; 2) 교차 작업의 경우: r ∩ r = r ∩ r; 3) 차이 연산의 경우: r1 \아르 자형2 ≠2 \아르 자형1; 4) 데카르트 곱 연산의 경우: r1 xr2 = r2 xr1; 5) 자연 조인 작업의 경우: r1 xr2 = r2 xr1. commutativity 속성은 차분 연산을 제외한 모든 연산에 대해 유지됩니다. 이것은 그들의 구성(튜플)이 장소에서 관계를 재배열해도 변하지 않기 때문에 이해하기 쉽습니다. 그리고 차분 연산을 적용할 때 피연산자 관계 중 어느 것이 먼저 오는가가 중요합니다. 그 이유는 어떤 관계가 참조로 간주될 튜플, 즉 제외를 위해 다른 튜플이 비교될 튜플에 달려 있기 때문입니다. 4. 연관성 속성: 1) 통합 작업의 경우: (r1 ∪r2)∪r3 = r1 ∪(r2 ∪r3); 2) 교차 작업의 경우: (r1 ∩r2)∩r3 = r1 ∩(r2 ∩r3); 3) 차이 연산의 경우: (r1 \아르 자형2)\아르 자형3 ≠1 \(아르 자형2 \아르 자형3); 4) 데카르트 곱 연산의 경우: (r1 xr2)xr3 = r1 x(r2 xr3); 5) 자연 조인 작업의 경우: (r1 xr2)xr3 = r1 x(r2 xr3). 그리고 다시 차이점 연산을 제외한 모든 연산에 대해 속성이 실행되는 것을 볼 수 있습니다. 이는 가환성 속성을 적용한 경우와 동일하게 설명됩니다. 대체로 합집합, 교집합, 차등 및 자연 조인의 연산은 피연산자 관계의 순서에 상관하지 않습니다. 그러나 관계가 서로 "제거"되면 질서가 지배적인 역할을 합니다. 위의 속성과 추론을 기반으로 다음과 같은 결론을 도출할 수 있습니다. 마지막 세 속성, 즉 멱등성, 교환성 및 결합성 속성은 두 관계의 차이 연산을 제외하고 우리가 고려한 모든 연산에 대해 참입니다. , 표시된 세 가지 속성 중 어느 것도 전혀 충족되지 않았으며 한 경우에만 해당 속성이 적용되지 않는 것으로 확인되었습니다. 4. 연결 작업 옵션 선택, 투영, 이름 변경의 단항 연산과 합집합, 교집합, 차분, 데카르트 곱 및 자연 조인의 이항 연산을 기본으로 사용합니다(모두 일반적으로 연결 작업), 우리는 위의 개념과 정의를 사용하여 파생된 새로운 연산을 도입할 수 있습니다. 이 활동을 컴파일이라고 합니다. 조인 작업 옵션. 조인 작업의 첫 번째 변형은 작업입니다. 내부 연결 지정된 연결 조건에 따라. 특정 조건에 의한 내부 조인의 연산은 데카르트 곱과 선택 연산의 파생 연산으로 정의됩니다. 이 작업의 공식 정의를 작성합니다. r1(S1) 엑스 P r2(S2) = σ (아르 자형1 xr2), 에스1 ∩ 에스2 = ∅; 여기서 P = P<S1 ∪ ㅅ2> - 원래 관계 피연산자의 두 체계의 결합에 부과되는 조건. 이 조건에 의해 튜플이 관계 r에서 선택됩니다.1 그리고 r2 결과 관계로. 내부 조인 작업은 다른 관계 스키마의 관계에 적용될 수 있습니다. 이러한 계획은 무엇이든 될 수 있지만 어떤 경우에도 교차해서는 안됩니다. 내부 조인 연산의 결과인 원래 피연산자 관계의 튜플을 호출합니다. 결합 가능한 튜플. 내부 조인 작업의 작업을 시각적으로 설명하기 위해 다음 예제를 제공합니다. 두 개의 관계 r이 주어집니다.1(S1) 및 r2(S2) 다른 관계 체계: r1(S1):
r2(S2):
다음 표는 P = (b1 = b2) 조건에서 내부 조인 연산을 적용한 결과를 보여줍니다. r1(S1) 엑스 P r2(S2):
따라서 관계를 나타내는 두 테이블의 "접착"이 내부 조인 작업 P = (b1 = b2)의 조건이 충족되는 튜플에 대해 실제로 정확하게 발생했음을 알 수 있습니다. 이제 이미 도입된 내부 조인 작업을 기반으로 작업을 소개할 수 있습니다. 왼쪽 외부 조인 и 오른쪽 외부 조인. 설명하자. 왼쪽 외부 조인 작업의 결과는 왼쪽 소스 관계 피연산자의 조인할 수 없는 튜플로 완료된 내부 조인의 결과입니다. 유사하게, 우측 외부 조인 연산의 결과는 우측 소스 릴레이션 피연산자의 조인 불가 튜플로 완료된 내부 조인 연산의 결과로 정의됩니다. 왼쪽 및 오른쪽 외부 조인 작업의 결과 관계가 어떻게 보충되는지에 대한 질문이 상당히 예상됩니다. 한 관계 피연산자의 튜플은 다른 관계 피연산자의 스키마에서 보완됩니다. 널 값. 이러한 방식으로 도입된 왼쪽 및 오른쪽 외부 결합 작업은 내부 결합 작업에서 파생된 작업이라는 점에 유의할 필요가 있습니다. 왼쪽 및 오른쪽 외부 조인 작업에 대한 일반 공식을 작성하기 위해 몇 가지 추가 구성을 수행합니다. 두 개의 관계 r이 주어집니다.1(S1) 및 r2(S2) 다른 관계 체계 S1 그리고 S2, 서로 교차하지 않습니다. 왼쪽 및 오른쪽 내부 조인 연산이 도함수라고 이미 규정했기 때문에 왼쪽 외부 조인 연산을 결정하기 위해 다음과 같은 보조 공식을 얻을 수 있습니다. 1) ㄹ3 (S2 ∪ ㅅ1) ≔ r1(S1) 엑스 Pr2(S2); r 3 (S2 ∪ ㅅ1)는 단순히 관계 r의 내부 조인의 결과입니다.1(S1) 및 r2(S2). 왼쪽 외부 조인은 내부 조인 작업에서 파생된 작업이므로 이를 사용하여 구성을 시작합니다. 2) ㄹ4(S1) ≔ r 3(S2 ∪S1) [에스1]; 따라서 단항 투영 연산의 도움으로 왼쪽 초기 관계 피연산자 r의 결합 가능한 모든 튜플을 선택했습니다.1(S1). 결과는 r로 지정됩니다.4(S1) 사용 편의성을 위해 3) ㄹ5 (S1) ≔ r1(S1)\아르 자형4(S1); 여기 r1(S1)은 왼쪽 소스 관계 피연산자의 모든 튜플이고 r4(S1) - 연결된 자체 튜플. 따라서 r에 대한 차이의 이진 연산을 사용하여5(S1) 왼쪽 피연산자 관계의 결합 불가능한 모든 튜플을 얻었습니다. 4) ㄹ6(S2)≔{∅(에스2)}; {∅(에스2)} 스키마(S2) 하나의 튜플만 포함하고 Null 값으로 구성됩니다. 편의상 이 비율을 r로 표시했습니다.6(S2); 5) ㄹ7 (S2 ∪ ㅅ1) ≔ r5(S1)xr6(S2); 여기서 우리는 왼쪽 피연산자 관계(r5(S1)) 두 번째 관계 피연산자 S2 Null 값, 즉 Cartesian은 이러한 동일한 결합 불가능한 튜플로 구성된 관계에 관계 r을 곱했습니다.6(S2) 단락 XNUMX에서 정의 6) ㄹ1(S1) →x P r2(S2) ≔ (r1 x P r2)∪r7 (S2 ∪ ㅅ1); 이것은 왼쪽 외부 조인, 볼 수 있는 것처럼 원래 관계 피연산자 r의 데카르트 곱의 합집합에 의해 얻어집니다.1 그리고 r2 및 관계 r7 (S2 ∪ S1) 단락 XNUMX에 정의. 이제 왼쪽 외부 조인의 작업뿐만 아니라 유추를 통해 오른쪽 외부 조인의 작업을 결정하는 데 필요한 모든 계산이 있습니다. 그래서: 1) 운영 왼쪽 외부 조인 엄격한 형태로 다음과 같이 보입니다. r1(S1) →x P r2(S2) ≔ (r1 x P r2) ∪ [(r1 \(아르 자형1 x P r2) [에스1]) x {∅(S2)}]; 2) 운영 오른쪽 외부 조인 왼쪽 외부 조인 작업과 유사한 방식으로 정의되며 다음 형식을 갖습니다. r1(S1) →x P r2(S2) ≔ (r1 x P r2) ∪ [(r2 \(아르 자형1 x P r2) [에스2]) x {∅(S1)}]; 이 두 파생 작업에는 언급할 가치가 있는 속성이 두 개뿐입니다. 1. 교환성의 속성: 1) 왼쪽 외부 조인 작업의 경우: r1(S1) →x P r2(S2) ≠2(S2) →x P r1(S1); 2) 오른쪽 외부 조인 작업의 경우: r1(S1) ←x P r2(S2) ≠2(S2) ←x P r1(S1) 따라서 일반적으로 이러한 작업에 대해 교환성 속성이 충족되지 않지만 왼쪽 및 오른쪽 외부 조인의 작업은 서로 반대입니다. 즉, 다음이 참입니다. 1) 왼쪽 외부 조인 작업의 경우: r1(S1) →x P r2(S2) = r2(S2) →x P r1(S1); 2) 오른쪽 외부 조인 작업의 경우: r1(S1) ←x P r2(S2) = r2(S2) ←x Pr1(S1). 2. 왼쪽 및 오른쪽 외부 조인 작업의 주요 속성은 복원하다 특정 조인 작업의 최종 결과에 따른 초기 관계 피연산자, 즉 다음이 수행됩니다. 1) 왼쪽 외부 조인 작업의 경우: r1(S1) = (r1 →x P r2) [에스1]; 2) 오른쪽 외부 조인 작업의 경우: r2(S2) = (r1 ←x P r2) [에스2]. 따라서 우리는 첫 번째 원래 관계 피연산자가 왼쪽-오른쪽 조인 연산의 결과에서 복원될 수 있음을 알 수 있습니다. 보다 구체적으로 이 조인의 결과(r1 xr2) 계획 S에 대한 투영의 단항 연산1,[에스1]. 그리고 마찬가지로 오른쪽 외부 조인(r1 xr2) 관계 S의 계획에 투영의 단항 연산2. 왼쪽 및 오른쪽 외부 조인 작업의 작업을 보다 자세히 고려하기 위해 예를 들어 보겠습니다. 이미 친숙한 관계 r을 소개하겠습니다.1(S1) 및 r2(S2) 다른 관계 체계: r1(S1):
r2(S2):
왼쪽 관계 피연산자 r의 결합 불가능한 튜플2(S2)는 튜플 {d, 4}입니다. 정의에 따라 두 개의 원래 피연산자 관계의 내부 연결 결과를 보완해야 하는 것은 바로 그들입니다. 관계 r의 내부 조인 조건1(S1) 및 r2(S2) P = (b1 = b2)도 그대로 둡니다. 그럼 수술 결과 왼쪽 외부 조인 다음 테이블이 있을 것입니다: r1(S1) →x P r2(S2):
실제로 우리가 볼 수 있듯이 왼쪽 외부 조인 작업의 영향으로 내부 조인 작업의 결과가 왼쪽의 조인 불가능한 튜플, 즉 우리의 경우 첫 번째 관계로 보충되었습니다. 피연산자. 정의에 따라 두 번째(오른쪽) 소스 관계 피연산자의 체계에 대한 튜플의 보충은 Null 값의 도움으로 발생했습니다. 그리고 결과와 비슷하게 오른쪽 외부 조인 이전과 동일하게 원래 관계-피연산자 r의 조건 P = (b1 = b2)1(S1) 및 r2(S2)는 다음 표입니다. r1(S1) ←x P r2(S2):
실제로 이 경우 내부 조인 작업의 결과는 오른쪽의 조인할 수 없는 튜플로 보충되어야 합니다. 이 경우에는 두 번째 초기 관계 피연산자입니다. 이러한 튜플은 보기 어렵지 않으므로 두 번째 관계 r에서2(S2) 하나, 즉 {2, y}. 다음으로 오른쪽 외부 조인 작업의 정의에 따라 첫 번째 피연산자의 체계에서 첫 번째(왼쪽) 피연산자의 튜플을 Null 값으로 보완합니다. 마지막으로 위의 조인 작업의 세 번째 버전을 살펴보겠습니다. 전체 외부 조인 작업. 이 연산은 내부 조인 연산에서 파생된 연산일 뿐만 아니라 왼쪽과 오른쪽 외부 조인 연산의 합집합으로도 볼 수 있습니다. 전체 외부 조인 작업 왼쪽 및 오른쪽 초기 피연산자 관계 모두의 조인 불가능한 튜플을 사용하여 동일한 내부 조인(왼쪽 및 오른쪽 외부 조인 정의의 경우와 같이)을 완료한 결과로 정의됩니다. 이 정의에 따라 이 정의의 공식 형식을 제공합니다. r1(S1) ←x P r2(S2) = (r1 →x P r2)∪(r1 ←x P r2); 전체 외부 조인 작업도 왼쪽 및 오른쪽 외부 조인 작업과 유사한 속성을 가지고 있습니다. 완전 외부 조인 연산(결국 좌우 외부 조인 연산의 합집합으로 정의됨)의 원래 상호적 특성으로 인해 다음을 수행합니다. 가환성 속성: r1(S1) ←x P r2(S2)=r2(S2) ← x P r1(S1); 그리고 조인 작업에 대한 옵션에 대한 고려를 완료하기 위해 전체 외부 조인 작업의 작업을 설명하는 예를 살펴보겠습니다. 우리는 두 가지 관계 r을 소개합니다1(S1) 및 r2(S2) 및 조인 조건. 하자 r1(S1)
r2(S2):
그리고 관계의 연결 조건 r1(S1) 및 r2(S2)는 이전 예에서와 같이 P = (b1 = b2)입니다. 그런 다음 관계 r의 전체 외부 조인 작업의 결과1(S1) 및 r2(S2) 조건 P = (b1 = b2)에 의해 다음 테이블이 생성됩니다. r1(S1) ←x P r2(S2):
따라서 전체 외부 조인 작업이 왼쪽 및 오른쪽 외부 조인 작업 결과의 합집합으로 정의를 명확하게 정당화한다는 것을 알 수 있습니다. 내부 조인 작업의 결과 관계는 왼쪽(첫 번째, r1(S1)), 오른쪽(두 번째, r2(S2)) 원래 관계 피연산자의. 5. 파생 작업 따라서 우리는 관계 대수의 XNUMX가지 원래 연산인 선택, 투영, 이름 바꾸기 및 이진 연산의 단항 연산에서 파생된 조인 연산의 다양한 변형, 즉 내부 조인, 왼쪽, 오른쪽 및 완전 외부 조인 연산을 고려했습니다. 합집합, 교집합, 차이, 데카르트 곱과 자연적 연결. 그러나 이러한 원래 작업에도 파생 작업의 예가 있습니다. 1. 예를 들어, 운영 교차로 두 비율은 동일한 두 비율의 차이 연산의 도함수입니다. 보여줍시다. 교차 연산은 다음 공식으로 표현할 수 있습니다. r1(S) ∩r2(에스) = r1 \아르 자형1 \아르 자형2 또는 동일한 결과를 제공합니다. r1(S) ∩r2(에스) = r2 \아르 자형2 \아르 자형1; 2. 또 다른 예로, XNUMX개의 원래 연산에서 기본 연산의 파생물은 연산입니다. 자연스러운 연결. 가장 일반적인 형태에서 이 연산은 데카르트 곱의 이진 연산과 속성 선택, 투영 및 이름 바꾸기의 단항 연산에서 파생됩니다. 그러나 차례로 내부 조인 연산은 관계의 데카르트 곱의 동일한 연산의 파생 연산입니다. 따라서 자연 조인 연산이 파생 연산임을 보여주기 위해 다음 예를 고려하십시오. 자연 및 내부 조인 작업에 대한 이전 예를 비교해 보겠습니다. 두 개의 관계 r이 주어집니다.1(S1) 및 r2(S2) 피연산자 역할을 합니다. 그들은 평등합니다: r1(S1):
r2(S2):
앞에서 이미 받은 것처럼 이러한 관계의 자연스러운 조인 작업의 결과는 다음 형식의 테이블이 됩니다. r3(S3) ≔ r1(S1)xr2(S2):
그리고 동일한 관계 r의 내부 조인 결과1(S1) 및 r2(S2) 조건 P = (b1 = b2)에 의해 다음 테이블이 생성됩니다. r4(S4) ≔ r1(S1) 엑스 P r2(S2):
이 두 결과를 비교해 보겠습니다. 결과로 나오는 새로운 관계 r3(S3) 및 r4(S4). 자연스러운 조인 연산은 내부 조인 연산을 통해 표현되는 것이 분명하지만 가장 중요한 것은 특별한 형태의 조인 조건으로 표현된다. 내부 조인 연산의 파생물로서 자연 조인 연산의 동작을 설명하는 수학 공식을 작성해 보겠습니다. r1(S1)xr2(S2) = { ρ<ϕ1> 아르1 x E ρ< ϕ2>r2}[에스1 ∪ ㅅ2], 여기서 E - 연결 상태 튜플; E= ∀a ∈S1 ∩ 에스2 [IsNull(b1) 및 IsNull(2) ∪b1 = b2]; b1 = φ1 (이름(a)), b2 = φ2 (이름(a)); 여기 중 하나가 있습니다 함수 이름 바꾸기 ϕ1 동일하고 또 다른 이름 변경 기능(즉, ϕ2) 스키마가 교차하는 속성의 이름을 바꿉니다. 튜플에 대한 연결 조건 E는 Null 값의 발생 가능성을 고려하여 일반적인 형식으로 작성됩니다. 내부 조인 연산(위에서 언급한 바와 같이)은 두 관계의 데카르트 곱과 단항 선택 연산의 파생 연산이기 때문입니다. 6. 관계 대수의 표현 앞에서 살펴본 관계대수의 표현과 연산이 다양한 데이터베이스의 실제 운용에 어떻게 활용될 수 있는지 보여드리겠습니다. 예를 들어 상용 데이터베이스의 일부를 마음대로 사용할 수 있다고 가정해 보겠습니다. 공급업체(공급 업체 코드, 공급업체 이름, 공급업체 도시); 도구(도구 코드, 도구 이름,...); 배달(공급 업체 코드, 부품 코드); 밑줄 친 속성 이름[1]은 각각 고유한 관계에 있는 핵심(즉, 식별) 속성입니다. 이 데이터베이스의 개발자이자 이 주제에 대한 정보 관리자로서 이러한 공급자가 도구를 제공하지 않는 경우 공급자의 이름(공급자 이름)과 위치(공급자 도시)를 얻으라는 명령을 받았다고 가정합니다. 총칭 "플라이어". 매우 큰 데이터베이스에서 이 요구 사항을 충족하는 모든 공급업체를 결정하기 위해 관계 대수에 대한 몇 가지 표현을 작성합니다. 1. 우리는 "공급자"와 "공급자" 관계의 자연스러운 연결을 형성하여 각 공급자와 자신이 공급하는 부품의 코드를 일치시킵니다. 새로운 관계 - 자연 조인 연산의 적용 결과 - 추가 적용의 편의를 위해 r로 표시됩니다.1. 공급자 x 소모품 ≔ r1 (공급업체 코드, 공급업체 이름, 공급업체 도시, 괄호 안에 이 자연 조인 작업과 관련된 관계의 모든 속성을 나열했습니다. "Vendor ID" 속성이 중복된 것을 볼 수 있지만 트랜잭션 요약 레코드에서 각 속성 이름은 한 번만 나타나야 합니다. 공급자 x 소모품 ≔ r1 (공급자 코드, 공급자 이름, 공급자 도시, 기기 코드); 2. 다시 우리는 자연스러운 연결을 형성하지만, 이번에는 단락 XNUMX에서 얻은 관계와 도구 관계를 형성합니다. 이 도구의 이름을 이전 단락에서 얻은 각 도구 코드와 일치시키기 위해 이 작업을 수행합니다. r1 x 도구 [도구 코드, 도구 이름] ≔ r2 (공급업체 코드, 공급업체 이름, 공급업체 도시, 결과 결과는 r로 표시됩니다.2, 중복 속성은 제외됩니다. r1 x 도구 [도구 코드, 도구 이름] ≔ r2 (공급자 코드, 공급자 이름, 공급자 도시, 기기 코드, 기기 이름); 도구 관계에서 "도구 코드"와 "도구 이름"이라는 두 가지 속성만 가져옵니다. 이를 위해 우리는 관계 r의 표기법에서 볼 수 있듯이2, 단항 투영 연산 적용: 도구 [도구 코드, 도구 이름], 즉, 도구 관계가 테이블로 표시되는 경우 이 투영 작업의 결과는 제목이 "도구 코드" 및 "도구"인 처음 두 열이 됩니다. 이름" 각각 ". 우리가 이미 고려한 처음 두 단계는 매우 일반적입니다. 즉, 다른 요청을 구현하는 데 사용할 수 있습니다. 그러나 다음 두 요점은 차례로 우리 앞에 놓인 특정 작업을 달성하기 위한 구체적인 단계를 나타냅니다. 3. 비율 r과 관련하여 <"Tool name" = "Pliers"> 조건에 따라 단항 선택 연산을 작성합니다.2이전 단락에서 얻었습니다. 그리고 우리는 이러한 속성의 모든 값을 얻기 위해 단항 투영 연산 [공급자 코드, 공급자 이름, 공급자 도시]를 이 연산의 결과에 적용합니다. 주문하다. 그래서 : (σ<도구 이름 = "플라이어"> r2) [공급자 코드, 공급자 이름, 공급자 도시] ≔ r3 (공급업체 코드, 공급업체 이름, 공급업체 도시, 도구 코드, 도구 이름). 결과 비율에서 r로 표시3, 해당 공급업체(모든 식별 데이터 포함)만이 일반 이름이 "플라이어"인 도구를 제공하는 것으로 나타났습니다. 그러나 명령에 따라 그러한 도구를 제공하지 않는 공급자를 골라내야 합니다. 따라서 알고리즘의 다음 단계로 넘어가서 우리가 찾고 있는 정보를 제공할 관계 대수의 마지막 표현을 적어 보겠습니다. 4. 먼저 "공급자" 비율과 비율 r의 차이를 알아보겠습니다.3, 그리고 이 이진 연산을 적용한 후 "Supplier Name" 및 "Supplier City" 속성에 단항 투영 연산을 적용합니다. (공급업체\r3) [공급자명,공급자 도시] ≔ r4 (공급자 코드, 공급자 이름, 공급자 도시); 결과는 r로 표시됩니다.4, 이 관계에는 주문 조건에 해당하는 원래 "공급자" 관계의 튜플만 포함됩니다. 그래서 우리는 관계 대수의 표현식과 연산을 사용하여 임의의 데이터베이스로 모든 종류의 작업을 수행하고 다양한 명령을 수행하는 방법을 보여주었습니다. 강의 6. SQL 언어 먼저 약간의 역사적 배경을 설명하겠습니다. 데이터베이스와 상호 작용하도록 설계된 SQL 언어는 1970년대 중반에 등장했습니다. (첫 번째 간행물은 1974년으로 거슬러 올라갑니다) 실험적인 관계형 데이터베이스 관리 시스템 프로젝트의 일부로 IBM에서 개발했습니다. 언어의 원래 이름은 SEQUEL(Structured English 쿼리 언어) - 이 언어의 본질을 부분적으로만 반영했습니다. 처음에 발명 직후와 SQL 언어의 주요 작동 기간 동안 그 이름은 "Structured Query Language"로 번역되는 Structured Query Language 구의 약어였습니다. 물론, 언어는 주로 사용자가 편리하고 이해할 수 있는 관계형 데이터베이스에 대한 쿼리의 공식화에 중점을 두었습니다. 그러나 실제로 거의 처음부터 쿼리를 공식화하고 데이터베이스를 조작하는 수단 외에도 다음과 같은 기능을 제공하는 완전한 데이터베이스 언어였습니다. 1) 데이터베이스 스키마를 정의하고 조작하는 수단; 2) 무결성 제약 및 트리거를 정의하기 위한 수단(나중에 언급됨) 3) 데이터베이스 보기를 정의하는 수단; 4) 요청의 효율적인 실행을 지원하는 물리 계층 구조를 정의하는 수단; 5) 관계 및 해당 분야에 대한 액세스 권한을 부여하는 수단. 이 언어는 병렬 트랜잭션 측면에서 데이터베이스 개체에 대한 액세스를 명시적으로 동기화하는 수단이 부족했습니다. 처음부터 필요한 동기화가 데이터베이스 관리 시스템에 의해 암시적으로 수행된다고 가정했습니다. 현재 SQL은 더 이상 약어가 아니라 독립 언어의 이름입니다. 또한 현재 구조화된 쿼리 언어는 모든 상용 관계형 데이터베이스 관리 시스템과 원래 관계형 접근 방식에 기반하지 않은 거의 모든 DBMS에 구현됩니다. 모든 제조 회사는 구현이 SQL 표준을 준수한다고 주장하며 실제로 구조적 쿼리 언어의 구현된 방언은 매우 가깝습니다. 이것은 즉시 달성되지 않았습니다. 기존의 SQL 방언을 비교하기 어렵게 만드는 대부분의 최신 상용 데이터베이스 관리 시스템의 특징은 언어에 대한 균일한 설명이 없다는 것입니다. 일반적으로 설명은 다양한 설명서에 흩어져 있으며 구조화된 쿼리 언어와 직접 관련이 없는 시스템별 언어 기능에 대한 설명과 혼합되어 있습니다. 그럼에도 불구하고 데이터베이스 스키마 결정, 데이터 가져오기 및 조작, 데이터 액세스 권한 부여, 프로그래밍 언어에 SQL 포함 지원, 동적 SQL 문을 포함하는 SQL 문의 기본 집합은 상용 분야에서 잘 확립되어 있다고 말할 수 있습니다. 구현 및 어느 정도 표준을 준수합니다. 시간이 지남에 따라 Structured Query Language에 대한 작업을 통해 데이터 검색 문의 구문 및 의미 체계의 명확한 표준화, 데이터 조작 및 데이터베이스 무결성 제약 조건 수정을 위한 표준을 달성할 수 있었습니다. 즉시 검사된 SQL 무결성 제약 조건의 하위 집합인 관계 및 소위 무결성 검사 제약 조건의 기본 및 외래 키를 정의하기 위한 수단이 지정되었습니다. 외래 키를 정의하는 도구를 사용하면 소위 데이터베이스의 참조 무결성 요구 사항을 쉽게 공식화할 수 있습니다(나중에 설명함). 관계형 데이터베이스에서 흔히 볼 수 있는 이 요구 사항은 SQL 무결성 제약 조건의 일반적인 메커니즘을 기반으로 공식화될 수도 있지만 외래 키 개념을 기반으로 하는 공식화는 더 간단하고 이해하기 쉽습니다. 따라서 이 모든 것을 고려하여 현재 구조화된 쿼리 언어는 기존의 표준에도 불구하고 구조화된 쿼리 언어의 다양한 방언이 구현되어 있기 때문에 현재 하나의 언어 이름이 아니라 전체 언어 클래스의 이름입니다. 물론 하나의 공통 기반을 갖는 다양한 데이터베이스 관리 시스템에서. 1. Select 문은 Structured Query Language의 기본 문입니다. SQL 구조화된 쿼리 언어의 중심 위치는 데이터베이스 작업 시 가장 많이 요구되는 작업인 쿼리를 구현하는 Select 문이 차지합니다. Select 연산자는 관계형 및 의사 관계형 대수식을 모두 평가합니다. 이 과정에서 우리는 이미 다룬 관계 대수의 단항 및 이진 연산의 구현과 소위 하위 쿼리를 사용한 쿼리의 구현에 대해 고려할 것입니다. 그건 그렇고, 관계 대수 연산으로 작업하는 경우 결과 관계에 중복 튜플이 나타날 수 있다는 점에 유의해야 합니다. 구조화된 쿼리 언어의 규칙에서 관계에 중복 행이 존재하는 것을 엄격히 금지하지 않으므로(일반 관계 대수와 달리) 결과에서 중복을 제외할 필요가 없습니다. 이제 Select 문의 기본 구조를 살펴보겠습니다. 매우 간단하며 다음과 같은 표준 필수 문구가 포함되어 있습니다. 선택 ... 에서 ... 어디... ; 각 줄의 줄임표 대신 특정 데이터베이스의 관계, 속성 및 조건과 해당 데이터베이스에 대한 작업이 있어야 합니다. 가장 일반적인 경우 기본 Select 구조는 다음과 같아야 합니다. 선택 일부 속성 선택 ~ 그런 관계에서 어디에 샘플링 튜플을 위한 이런저런 조건으로 따라서 우리는 관계 체계(일부 열의 머리글)에서 속성을 선택하고 어떤 관계(보다시피 몇 가지가 있을 수 있음)에서 선택하고 마지막으로 중지하는 조건에 따라 특정 튜플에 대한 우리의 선택. 속성 참조는 해당 이름을 사용하여 작성된다는 점에 유의하는 것이 중요합니다. 따라서 다음이 얻어진다. 작업 알고리즘 이 기본 Select 문: 1) 관계에서 튜플을 선택하기 위한 조건이 기억됩니다. 2) 어떤 튜플이 지정된 속성을 만족하는지 확인합니다. 이러한 튜플은 기억됩니다. 3) Select 문의 기본 구조의 첫 번째 줄에 나열된 속성과 해당 값이 출력됩니다. (테이블 형식의 관계에 대해 이야기하면 테이블의 해당 열이 표시되고 머리글이 필수 속성으로 나열됩니다. 물론 열은 완전히 표시되지 않으며 각 열에는 해당 튜플만 표시됩니다. 명명된 조건을 만족하는 것은 유지됩니다.) 예를 고려해보십시오. 다음 관계식 r이 주어집니다.1, 일부 서점 데이터베이스의 일부로:
Select 문과 함께 다음 표현식도 주어진다고 가정합니다. 선택 책의 제목, 책의 저자 ~ r1 어디에 책 가격 > 200; 이 연산자의 결과는 다음과 같은 튜플 조각이 됩니다. (휴대전화, S. King). (다음에서 우리는 이 기본 구조를 사용하는 쿼리 구현의 많은 예를 고려하고 그 응용을 매우 자세히 연구할 것입니다.) 2. 구조화된 쿼리 언어의 단항 연산 이 섹션에서는 이미 친숙한 선택, 프로젝션 및 이름 바꾸기의 단항 연산이 Select 연산자를 사용하여 구조화된 쿼리 언어로 구현되는 방법을 고려할 것입니다. 이전에 개별 연산으로만 작업할 수 있었다면 일반적인 경우에 단일 Select 연산자로도 단일 연산이 아니라 전체 관계 대수식을 정의할 수 있다는 점에 유의하는 것이 중요합니다. 따라서 구조화된 쿼리 언어로 된 단항 연산의 표현 분석을 직접 진행해 보겠습니다. 1. 샘플링 작업. SQL의 선택 작업은 다음 형식의 Select 문으로 구현됩니다. 선택 모든 속성 ~ 관계 이름 어디에 선택 조건; 여기에서 "모든 속성"을 쓰는 대신 "*" 기호를 사용할 수 있습니다. 구조화된 쿼리 언어 이론에서 이 아이콘은 관계 스키마에서 모든 속성을 선택하는 것을 의미합니다. 여기(그리고 다른 모든 연산 구현에서) 선택 조건은 not (not), and (and), or (or) 표준 접속사가 있는 논리적 표현으로 작성됩니다. 관계 속성은 이름으로 참조됩니다. 예를 들어보겠습니다. 다음 관계 체계를 정의합시다. 학업 성과(성적부 번호, 학기, 과목 코드, 등급, 날짜); 여기서 앞서 언급했듯이 밑줄 친 속성이 관계 키를 형성합니다. 단항 선택 연산을 구현하는 다음 형식의 Select 문을 작성해 보겠습니다. 선택하다 * 학업 성적부터 여기서 Gradebook # = 100 및 Semester = 6; 이 진술의 결과로 기계는 여섯 번째 학기 동안 기록 번호 XNUMX으로 학생의 진행 상황을 표시 할 것이 분명합니다. 2. 프로젝션 작업. Structured Query Language의 프로젝션 작업은 가져오기 작업보다 구현하기가 훨씬 쉽습니다. 투영 작업을 적용할 때 행이 선택되지 않고(선택 작업을 적용할 때와 같이) 열이 선택된다는 점을 기억하십시오. 따라서 외부 조건을 지정하지 않고 원하는 열(즉, 속성 이름)의 헤더를 나열하는 것으로 충분합니다. 전체적으로 다음 형식의 연산자를 얻습니다. 선택 속성 이름 목록 ~ 관계 이름; 이 문을 적용한 후 기계는 이 Select 문의 첫 번째 줄에 이름이 지정된 관계 테이블의 열을 반환합니다. 앞에서 언급했듯이 결과 관계에서 중복 행과 열을 제외할 필요는 없습니다. 그러나 주문이나 작업에서 중복을 제거해야 하는 경우 구조화된 쿼리 언어의 특수 옵션을 사용해야 합니다. 뚜렷한. 이 옵션은 관계에서 중복 튜플을 자동으로 제거하도록 설정합니다. 이 옵션을 적용하면 Select 문은 다음과 같이 표시됩니다. 선택 속성 이름의 고유 목록 ~ 관계 이름; SQL에는 표현식의 선택적 요소에 대한 특별한 표기법(대괄호 [...])이 있습니다. 따라서 가장 일반적인 형태의 투영 작업은 다음과 같습니다. 선택 [고유] 속성 이름 목록 ~ 관계 이름; 그러나 작업을 적용한 결과가 중복을 포함하지 않도록 보장되거나 중복이 여전히 허용되는 경우 옵션 뚜렷한 기록을 어지럽히지 않도록 지정하지 않는 것이 좋습니다. 중복이 없을 때 XNUMX% 신뢰 가능성을 보여주는 예를 살펴보겠습니다. 우리에게 이미 알려진 관계 계획이 주어집니다. 학업 성과(성적부 번호, 학기, 과목 코드, 등급, 날짜). 다음 Select 문이 주어집니다. 선택 성적부 번호, 학기, 과목 코드 ~ 학업 성과; 여기서 연산자가 반환한 세 가지 속성이 관계의 키를 형성한다는 것을 쉽게 알 수 있습니다. 그렇기 때문에 옵션 뚜렷한 중복이 없다는 것이 보장되기 때문에 중복됩니다. 이는 고유 제약 조건이라는 키에 대한 요구 사항을 따릅니다. 나중에 이 속성에 대해 더 자세히 살펴보겠지만 속성이 키인 경우 중복되지 않습니다. 3. 이름 바꾸기 작업. 구조화된 쿼리 언어에서 속성 이름을 바꾸는 작업은 매우 간단합니다. 즉, 실제로 다음과 같은 알고리즘으로 구현된다. 1) Select 구문의 속성 이름 목록에서 이름을 변경해야 하는 속성이 나열됩니다. 2) 지정된 각 속성에 추가되는 특수 키워드 3) as라는 단어가 나올 때마다 해당 속성의 이름이 표시되며 원래 이름을 변경해야 합니다. 따라서 위의 모든 사항을 고려하면 속성 이름 바꾸기 작업에 해당하는 명령문이 다음과 같이 표시됩니다. 선택 속성 이름 1을 새 속성 이름 1로,... ~ 관계 이름; 이 연산자가 어떻게 작동하는지 예제를 통해 보여드리겠습니다. 우리에게 이미 친숙한 관계 체계가 주어집니다. 학업 성과(성적부 번호, 학기, 과목 코드,등급, 날짜); 일부 속성의 이름을 변경하라는 명령이 있습니다. 즉, "계정 장부 번호" 대신 "계정 번호"가 있어야 하고 "점수" 대신 "점수"가 있어야 합니다. 이 이름 바꾸기 작업을 구현하는 Select 문이 다음과 같이 보일지 적어 보겠습니다. 선택 기록 번호로 기록 장부, 학기, 과목 코드, 점수로 학년, 날짜 ~ 학업 성과; 따라서 이 연산자를 적용한 결과는 두 속성의 이름이 원래 "성취" 관계 스키마와 다른 새로운 관계 스키마가 됩니다. 3. 구조화된 쿼리 언어의 이진 연산 단항 연산과 마찬가지로 이진 연산도 구조화된 쿼리 언어 또는 SQL로 자체 구현됩니다. 따라서 이미 전달한 이진 연산, 즉 합집합, 교집합, 차분, 데카르트 곱, 자연 조인, 내부 및 왼쪽, 오른쪽, 완전 외부 조인의 연산을 이 언어로 구현하는 것을 고려해 보겠습니다. 1. 조합운영. 두 관계를 결합하는 작업을 구현하려면 두 개의 Select 연산자를 동시에 사용해야 하며, 각 연산자는 원래 관계-피연산자 중 하나에 해당합니다. 그리고 이 두 가지 기본 Select 문에 특별한 작업을 적용해야 합니다. 노동 조합. 위의 모든 사항을 고려하여 구조화된 쿼리 언어의 의미를 사용하여 통합 작업이 어떻게 보이는지 적어 보겠습니다. 선택 관계 1의 속성 이름 나열 ~ 관계 이름 1 노동 조합 선택 관계 2의 속성 이름 나열 ~ 관계 이름 2; 조인되는 두 관계의 속성 이름 목록은 호환 가능한 유형의 속성을 참조해야 하며 일관된 순서로 나열되어야 한다는 점에 유의하는 것이 중요합니다. 이 요구 사항이 충족되지 않으면 요청을 이행할 수 없으며 컴퓨터에 오류 메시지가 표시됩니다. 그러나 흥미로운 점은 이러한 관계에서 속성 이름 자체가 다를 수 있다는 것입니다. 이 경우 결과 관계에는 첫 번째 Select 문에 지정된 속성 이름이 할당됩니다. 또한 Union 연산을 사용하면 결과 관계에서 모든 중복 튜플이 자동으로 제외된다는 것을 알아야 합니다. 따라서 최종 결과에서 모든 중복 행을 보존해야 하는 경우 Union 연산 대신 이 연산의 수정을 사용해야 합니다. 유니온 올. 이 경우 두 관계를 결합하는 작업은 다음과 같습니다. 선택 관계 1의 속성 이름 나열 ~ 관계 이름 1 유니온 올 선택 관계 2의 속성 이름 나열 ~ 관계 이름 2; 이 경우 결과 관계에서 중복 튜플이 제거되지 않습니다. Select 문의 선택적 요소 및 옵션에 대해 앞에서 언급한 표기법을 사용하여 구조화된 쿼리 언어에서 두 관계를 결합하는 작업의 가장 일반적인 형식을 작성합니다. 선택 관계 1의 속성 이름 나열 ~ 관계 이름 1 연합 [전체] 선택 관계 2의 속성 이름 나열 ~ 관계 이름 2; 2. 교차로 운영. 구조화된 쿼리 언어에서 교차 연산과 두 관계의 차이 연산은 유사한 방식으로 구현됩니다(방법이 단순할수록 경제적이고 관련성이 높으므로 가장 간단한 표현 방법을 고려합니다. 수요). 그래서, 우리는 다음을 사용하여 교차 연산을 구현하는 방법을 분석할 것입니다. 열쇠. 이 방법은 두 개의 Select 구성 요소의 참여를 포함하지만 동일하지 않습니다(공집합 연산의 표현에서와 같이). 그 중 하나는 말하자면 "하위 구성", "하위 순환"입니다. 이러한 연산자는 일반적으로 하위 쿼리. 따라서 두 가지 관계 체계(R1 그리고 R2), 대략적으로 다음과 같이 정의됩니다. R1 (열쇠,...) 그리고 R2 (열쇠,...); 이 작업을 기록할 때 특수 옵션도 사용합니다. in, 문자 그대로 "안에" 또는 (이 특별한 경우와 같이) "포함된"을 의미합니다. 따라서 위의 모든 사항을 고려하여 구조화된 쿼리 언어를 사용하는 두 관계의 교차 연산은 다음과 같이 작성됩니다. 선택 * ~ R1 어디에 키 입력 (선택 ключ R에서2); 따라서 이 경우 하위 쿼리가 괄호 안의 연산자임을 알 수 있습니다. 우리의 경우이 하위 쿼리는 관계 R의 키 값 목록을 반환합니다.2. 그리고 다음과 같이 연산자 표기법, 선택 조건 분석에서 관계 R의 해당 튜플만 결과 관계에 속합니다.1, 키가 관계 R의 키 목록에 포함되어 있습니다.2. 즉, 최종 릴레이션에서 두 릴레이션의 교집합 정의를 상기하면 두 릴레이션에 속하는 튜플만 남게 됩니다. 3. 차분 연산. 앞서 언급했듯이 두 관계의 차분의 단항 연산은 교집합 연산과 유사하게 구현됩니다. 여기에서는 Select 연산자가 있는 기본 쿼리 외에 보조 쿼리인 소위 하위 쿼리가 사용됩니다. 그러나 이전 연산의 구현과 달리 차분 연산을 구현할 때 다른 키워드를 사용해야 합니다. 하지에, 문자 그대로 번역에서 "포함되지 않음" 또는 (고려 중인 우리의 경우 번역하는 것이 적절함) - "포함되지 않음"을 의미합니다. 따라서 이전 예에서와 같이 두 가지 관계 체계(R1 그리고 R2), 대략적으로 다음과 같이 주어집니다. R1 (열쇠,...) 그리고 R2 (열쇠,...); 보시다시피 이러한 관계의 속성 중에서 키 속성이 다시 설정됩니다. 따라서 구조화된 쿼리 언어에서 차분 연산을 나타내는 다음 형식을 얻습니다. 선택하다 * ~ R1 어디에 ключ 하지에 (선택 ключ ~ R2); 따라서 관계 R의 튜플만1, 그 키가 관계 R의 키 목록에 포함되지 않음2. 표기법을 문자 그대로 고려하면 실제로 관계 R에서1 비율 R을 "빼기"2. 여기에서 우리는 이 연산자의 선택 조건이 올바르게 작성되었으며(결국 두 관계의 차이 정의가 수행됨) 교차 연산 구현의 경우와 같이 키 사용이 완전히 정당화된다는 결론을 내립니다. . 우리가 본 "핵심 방법"의 두 가지 용도가 가장 일반적입니다. 이것으로 관계를 나타내는 연산자 구성에서 키 사용에 대한 연구를 마칩니다. 관계 대수의 모든 나머지 이진 연산은 다른 방식으로 작성됩니다. 4. 데카르트 곱 연산 이전 강의에서 기억하듯이, 두 관계 피연산자의 데카르트 곱은 속성에 대한 튜플의 명명된 값의 가능한 모든 쌍의 집합으로 구성됩니다. 따라서 구조화된 쿼리 언어에서 데카르트 곱 연산은 키워드로 표시되는 교차 조인을 사용하여 구현됩니다. 교차 결합, 문자 그대로 "교차 조인" 또는 "교차 조인"으로 번역됩니다. 구조화된 쿼리 언어의 데카르트 곱 연산을 나타내는 구조에는 Select 연산자가 하나만 있으며 형식은 다음과 같습니다. 선택하다 * ~ R1 교차 결합 R2 여기 R1 그리고 R2 - 초기 관계의 이름 - 피연산자. 옵션 교차 결합 결과 관계가 관계 R의 모든 튜플 쌍에 해당하는 모든 속성(연산자의 첫 번째 줄에 "*" 기호가 포함되어 있기 때문에 all)을 포함하도록 합니다.1 그리고 R2. 데카르트 곱 연산 구현의 한 가지 기능을 기억하는 것이 매우 중요합니다. 이 기능은 데카르트 곱의 이진 연산 정의의 결과입니다. 기억하세요: r4(S4) = r1(S1)xr2(S2) = {t(에스1 ∪ ㅅ2) | t[에스1] ∈r1 &t(S2) ∈r2}, 에스1 ∩ 에스2= ∅; 위의 정의에서 알 수 있듯이 튜플 쌍은 반드시 교차하지 않는 관계 체계로 형성됩니다. 따라서 SQL 구조화된 쿼리 언어로 작업할 때 초기 피연산자 관계에 일치하는 속성 이름이 없어야 한다고 항상 규정됩니다. 그러나 이러한 관계의 이름이 여전히 동일한 경우 속성 이름 변경 작업을 사용하여 현재 상황을 쉽게 해결할 수 있습니다. as, 앞서 언급한 것입니다. 동일한 속성 이름을 가진 두 관계의 데카르트 곱을 찾아야 하는 예를 살펴보겠습니다. 따라서 다음과 같은 관계가 주어집니다. R1 (A,B), R2 (기원전); 우리는 R 속성이1.B 및 R2.B는 이름이 같습니다. 이를 염두에 두고 구조화된 쿼리 언어에서 이 데카르트 곱 연산을 구현하는 Select 문은 다음과 같습니다. 선택 에이, 알1.B as 지하 1층, 우2.B as 지하 2층, C ~ R1 교차 결합 R2; 따라서 이름 바꾸기 옵션을 사용하면 시스템은 두 개의 원래 피연산자 관계의 일치하는 이름에 대한 "질문"을 갖지 않습니다. 5. 내부 조인 작업 얼핏 보면 자연 조인 연산보다 내부 조인 연산을 고려하는 것이 이상하게 보일 수 있습니다. 이진 연산을 수행할 때 모든 것이 반대였기 때문입니다. 그러나 구조화된 쿼리 언어의 연산 표현을 분석하면 자연 조인 연산이 내부 조인 연산의 특수한 경우라는 결론에 도달할 수 있습니다. 그렇기 때문에 이러한 작업을 순서대로 고려하는 것이 합리적입니다. 따라서 먼저 이전에 살펴본 내부 조인 작업의 정의를 상기해 보겠습니다. r1(S1) 엑스 P r2(S2) = σ (아르 자형1 xr2), 에스1 ∩ S2 = ∅. 우리에게 이 정의에서 고려되는 관계-피연산자 S의 체계가 특히 중요합니다.1 그리고 S2 교차하지 않아야 합니다. 구조화된 쿼리 언어에서 내부 조인 작업을 구현하기 위해 특별한 옵션이 있습니다. 내부 결합, 영어에서 문자 그대로 "내부 조인" 또는 "내부 조인"으로 번역됩니다. 내부 조인 작업의 경우 Select 문은 다음과 같습니다. 선택하다 * ~ R1 내부 결합 R2; 여기에서 이전과 같이 R1 그리고 R2 - 초기 관계의 이름 - 피연산자. 이 연산을 구현할 때 관계 피연산자의 체계가 교차할 수 없어야 합니다. 6. 자연 조인 작업 이미 말했듯이 자연 조인 연산은 내부 조인 연산의 특별한 경우입니다. 왜요? 예, 자연 조인의 동작 중에 원래 피연산자 관계의 튜플이 특별한 조건에 따라 조인되기 때문입니다. 즉, 관계-피연산자의 교차점에서 튜플의 평등 조건에 의해 내부 조인 연산의 동작으로 이러한 상황이 허용될 수 없습니다. 우리가 고려하고 있는 자연 조인 연산은 내부 조인 연산의 특수한 경우이므로 이전에 고려한 연산과 동일한 옵션을 사용하여 구현합니다. 내부 결합. 그러나 자연 조인 작업을 위해 Select 연산자를 컴파일할 때 스키마의 교차점에서 초기 관계 피연산자의 튜플이 동일한 조건을 고려해야 하기 때문에 표시된 옵션 외에, 키워드가 적용된 on. 영어로 번역하면 문자 그대로 "on"을 의미하며 우리의 의미와 관련하여 "subject to"로 번역 될 수 있습니다. 자연 조인 작업을 수행하기 위한 Select 문의 일반적인 형식은 다음과 같습니다. 선택하다 * ~ 관계 이름 1 내부 결합 관계 이름 2 on 튜플 평등 조건; 예를 고려해보십시오. 두 가지 관계가 주어집니다. R1 (A, B, C), R2 (B, C, D); 이러한 관계의 자연스러운 조인 작업은 다음 연산자를 사용하여 구현할 수 있습니다. 선택 에이, 알1.B, R1.CD ~ R1 내부 결합 R2 on R1.B=R2.B 및 R1.C=R2.C 이 작업의 결과로 Select 연산자의 첫 번째 줄에 지정된 특성이 지정된 교차점에서 동일한 튜플에 해당하며 결과에 표시됩니다. 여기서 우리는 이름뿐만 아니라 공통 속성 B와 C를 언급하고 있다는 점에 유의해야 합니다. 이것은 데카르트 곱 연산을 구현하는 경우와 같은 이유가 아니라 그들이 참조하는 관계가 명확하지 않기 때문에 수행되어야 합니다. 흥미롭게도 조인 조건(R1.B=R2.B 및 R1.C=R2.C) 결합된 Null 값 관계의 공유 속성이 허용되지 않는다고 가정합니다. 이것은 처음부터 구조적 쿼리 언어 시스템에 내장되어 있습니다. 7. 왼쪽 외부 조인 작업 왼쪽 외부 조인 연산의 SQL 구조적 쿼리 언어 표현은 키워드를 대체하여 자연 조인 연산의 구현에서 얻습니다. 안의 키워드당 왼쪽 바깥쪽. 따라서 구조화된 쿼리의 언어로 이 작업은 다음과 같이 작성됩니다. 선택하다 * ~ 관계 이름 1 왼쪽 외부 조인 관계 이름 2 on 튜플 평등 조건; 8. 오른쪽 외부 조인 작업 구조적 쿼리 언어에서 오른쪽 외부 조인 연산에 대한 표현식은 키워드를 대체하여 자연 조인 연산을 수행하여 얻은 것입니다. 안의 키워드당 오른쪽 외부. 따라서 SQL 구조화된 쿼리 언어에서 오른쪽 외부 조인의 작업은 다음과 같이 작성됩니다. 선택하다 * ~ 관계 이름 1 오른쪽 외부 조인 관계 이름 2 on 튜플 평등 조건; 9. 전체 외부 조인 작업 전체 외부 조인 연산에 대한 구조적 쿼리 언어 표현식은 앞의 두 경우와 같이 키워드를 대체하여 자연 조인 연산에 대한 표현식에서 얻습니다. 안의 키워드당 풀 아우터. 따라서 구조화된 쿼리의 언어로 이 작업은 다음과 같이 작성됩니다. 선택하다 * ~ 관계 이름 1 전체 외부 조인 관계 이름 2 on 튜플 평등 조건; 이러한 옵션이 SQL 구조화된 쿼리 언어의 의미론에 내장되어 있는 것이 매우 편리합니다. 그렇지 않으면 각 프로그래머가 이를 독립적으로 출력하고 각각의 새 데이터베이스에 입력해야 하기 때문입니다. 4. 하위 쿼리 사용 다룬 자료에서 알 수 있듯이 구조화된 쿼리 언어에서 "하위 쿼리"라는 개념은 기본 개념이며 상당히 광범위하게 적용할 수 있습니다(때로는 SQL 쿼리라고도 합니다. 실제로 프로그래밍 및 데이터베이스 작업은 다양한 관련 작업을 해결하기 위한 하위 쿼리 시스템을 컴파일하는 것을 보여줍니다. 이는 구조화된 정보로 작업하는 다른 방법에 비해 훨씬 더 보람 있는 활동입니다. 그리고 사용. 모든 교육 기관에서 사용할 수 있는 특정 데이터베이스의 다음 조각이 있다고 가정합니다. 항목(아이템 코드, 상품명); 학생(레코드 북 번호, 성명); 세션(과목 코드, 성적부 번호, 등급); "Databases"라는 주제에 대한 학생의 성적부 번호, 성 및 이니셜, 등급을 나타내는 명령문을 반환하는 SQL 쿼리를 공식화해 보겠습니다. 대학은 이러한 정보를 항상 적시에 수신해야 하므로 다음 쿼리는 아마도 이러한 데이터베이스를 사용하는 가장 인기 있는 프로그래밍 단위일 것입니다. 편의를 위해 "Last Name", "First Name" 및 "Patronymic" 속성이 Null 값을 허용하지 않고 비어 있지 않다고 추가로 가정하겠습니다. 이 요구 사항은 매우 이해할 수 있고 논리적입니다. 왜냐하면 신입생에 대한 데이터의 첫 번째 데이터가 교육 기관의 데이터베이스에 입력되는 것은 그의 성, 이름 및 후원에 대한 데이터이기 때문입니다. 그리고 학생에 대한 데이터가 포함된 그러한 데이터베이스에는 항목이 있을 수 없지만 동시에 그의 이름은 알려져 있지 않다는 것은 말할 필요도 없습니다. "Items" 관계 스키마의 "Item Name" 속성은 키이므로 정의에서 다음과 같이(나중에 자세히 설명) 모든 항목 이름은 고유합니다. 이것은 또한 교육 기관에서 가르치는 모든 과목이 다른 이름을 가져야 하고 다른 이름을 가져야 하기 때문에 키의 표현을 설명하지 않고도 이해할 수 있습니다. 이제 연산자 자체의 텍스트 컴파일을 시작하기 전에 진행하면서 유용할 두 가지 함수를 소개하겠습니다. 먼저 함수가 필요합니다. 정돈, Trim("문자열")로 작성됩니다. 즉, 이 함수에 대한 인수는 문자열입니다. 이 기능은 무엇을 합니까? 그들은 이 줄의 시작과 끝에 공백 없이 인수 자체를 반환합니다. 즉, 이 함수는 예를 들어 다음과 같은 경우에 사용됩니다. 몇 개의 추가 공간 가치가 있습니다. 그리고 두 번째로, Left(문자열, 숫자)로 쓰여진 Left 함수, 즉 이미 두 개의 인수로 구성된 함수이며 그 중 하나는 이전과 같이 문자열입니다. 두 번째 인수는 숫자로, 문자열의 왼쪽에서 결과로 출력되어야 하는 문자 수를 나타냅니다. 예를 들어 작업 결과는 다음과 같습니다. 왼쪽("미하일, 1") + "." + 왼쪽("지노비에비치, 1") 이니셜 "M.Z."가 됩니다. 쿼리에서 이 함수를 사용할 학생의 이니셜을 표시하는 것입니다. 이제 원하는 쿼리 컴파일을 시작하겠습니다. 먼저 작은 보조 쿼리를 만들어 주 쿼리에서 사용합니다. 선택 성적부 번호, 학년 ~ 세션 어디에 품목 코드 = (선택 아이템 코드 ~ 사물 어디에 항목 이름 = "데이터베이스") as "추정" 데이터베이스 "; 여기에서 as 옵션을 사용한다는 것은 이 쿼리에 "Database Estimates"라는 별칭을 지정했음을 의미합니다. 이 요청에 대한 추가 작업의 편의를 위해 이 작업을 수행했습니다. 다음으로 이 쿼리에서 하위 쿼리는 다음과 같습니다. 선택 아이템 코드 ~ 사물 어디에 항목 이름 = "데이터베이스"; "세션" 관계에서 고려 중인 주제, 즉 데이터베이스와 관련된 튜플을 선택할 수 있습니다. 흥미롭게도 이 내부 하위 쿼리는 "항목 이름" 속성이 "항목" 관계의 키이므로, 즉 모든 값이 고유하기 때문에 하나의 값만 반환할 수 있습니다. 그리고 전체 쿼리 "Scores "Database"를 사용하면 하위 쿼리에 지정된 조건, 즉 "Database"라는 주제에 대한 정보를 충족하는 학생(그들의 성적부 번호 및 성적)에 대한 "세션" 관계 데이터를 선택할 수 있습니다. 이제 이미 수신된 결과를 사용하여 기본 요청을 수행합니다. 선택 재학생. 기록 책 번호, 정돈 (성) + " " + 좌회전 (이름, 1) + "." + 좌회전 (가부장적, 1) + "."as 전체 이름, "데이터베이스"를 추정합니다. 등급 ~ 학생 내부 결합 ( 선택 성적부 번호, 학년 ~ 세션 어디에 품목 코드 = (선택 아이템 코드 ~ 사물 어디에 항목 이름 = "데이터베이스") ) 같이 "추정" 데이터베이스 ". on 재학생. 성적부 # = "데이터베이스" 성적. 책 번호를 기록합니다. 따라서 먼저 쿼리가 완료된 후 표시해야 하는 속성을 나열합니다. "성적부 번호" 속성은 "성", "이름" 및 "패트로니믹" 속성인 학생 관계에서 가져온 것임을 언급해야 합니다. 사실, 마지막 두 속성은 완전히 추론되지 않고 첫 글자만 추론됩니다. 또한 앞에서 입력한 '데이터베이스 점수' 쿼리의 '점수' 속성도 언급합니다. "Students" 관계와 쿼리 "Database grades"의 내부 조인에서 이러한 모든 속성을 선택합니다. 이 내부 조인은 우리가 볼 수 있듯이 레코드 북의 숫자가 동일한 조건에서 가져옵니다. 이 내부 조인 작업의 결과로 학생 관계에 성적이 추가됩니다. 조건에 따른 "Last Name", "First Name" 및 "Patronymic" 속성은 Null 값을 허용하지 않고 비어 있지 않기 때문에 "Name" 속성을 반환하는 계산 공식(정돈 (성) + " " + 좌회전 (이름, 1) + "." + 좌회전 (가부장적, 1) + "."as Full name)은 각각 추가 확인이 필요하지 않으며 단순화되었습니다. 강의 번호 7. 기본 관계 우리가 이미 알고 있듯이 데이터베이스는 일종의 컨테이너와 같으며 주요 목적은 관계의 형태로 제공되는 데이터를 저장하는 것입니다. 관계는 성격과 구조에 따라 다음과 같이 나뉩니다. 1) 기본 관계; 2) 가상 관계. 기본 보기 관계는 독립적인 데이터만 포함하며 다른 데이터베이스 관계로 표현할 수 없습니다. 상용 데이터베이스 관리 시스템에서 기본 관계는 일반적으로 간단히 테이블 가상 관계의 개념에 해당하는 표현과 대조됩니다. 이 과정에서 우리는 기본적인 관계, 그들과 함께 작업하는 주요 기술 및 원칙에 대해서만 자세히 고려할 것입니다. 1. 기본 데이터 유형 관계와 같은 데이터 유형은 다음과 같이 나뉩니다. 기본 и 가상. (가상 데이터 유형에 대해서는 잠시 후에 이야기할 것이며 이 주제에 대해서는 별도의 장을 할애할 것입니다.) 기본 데이터 유형 - 이들은 데이터베이스 관리 시스템에서 초기에 정의된, 즉 기본적으로 존재하는 모든 데이터 유형입니다(기본 데이터 유형을 통과한 직후 분석할 사용자 정의 데이터 유형과 반대). 실제 기본 데이터 유형을 고려하기 전에 일반적으로 어떤 유형의 데이터가 있는지 나열합니다. 1) 수치 데이터; 2) 논리적 데이터; 3) 문자열 데이터; 4) 날짜와 시간을 정의하는 데이터; 5) 식별 데이터. 기본적으로 데이터베이스 관리 시스템은 가장 일반적인 몇 가지 데이터 유형을 도입했으며 각 데이터 유형은 나열된 데이터 유형 중 하나에 속합니다. 전화합시다. 1. 있음 수치 데이터 유형이 구별됩니다. 1) 정수. 이 키워드는 일반적으로 정수 데이터 유형을 나타냅니다. 2) 실제 데이터 유형에 해당하는 실제; 3) 십진수(n, m). 이것은 XNUMX진수 데이터 유형입니다. 또한 표기법에서 n은 숫자의 총 자릿수를 고정하는 숫자이고 m은 소수점 이하 자릿수를 나타냅니다. 4) 화폐 데이터 유형의 편리한 데이터 표현을 위해 특별히 도입된 화폐 또는 화폐. 2. 있음 논리적 데이터 유형은 일반적으로 하나의 기본 유형만 할당합니다. 이 유형은 논리입니다. 3. 끈 데이터 유형에는 XNUMX가지 기본 유형이 있습니다(물론 가장 일반적인 유형을 의미함). 1) 비트(n). 고정 길이가 n인 비트 문자열입니다. 2) 바비트(n). 이들은 또한 비트 문자열이지만 n 비트를 초과하지 않는 가변 길이를 가집니다. 3) 문자(n). 이들은 일정한 길이가 n인 문자열입니다. 4) 바르차르(n). 가변 길이가 n자를 초과하지 않는 문자열입니다. 4. 유형 날짜와 시간 다음과 같은 기본 데이터 유형이 포함됩니다. 1) 날짜 - 날짜 데이터 유형; 2) 시간 - 하루 중 시간을 나타내는 데이터 유형. 3) 날짜-시간은 날짜와 시간을 모두 나타내는 데이터 유형입니다. 5. 식별 데이터 유형에는 데이터베이스 관리 시스템에 기본적으로 포함되는 하나의 유형, 즉 GUID(Globally Unique Identifier)만 포함됩니다. 모든 기본 데이터 유형에는 다양한 데이터 표현 범위의 변형이 있을 수 있습니다. 예를 들어, XNUMX바이트 정수 데이터 유형의 변형은 XNUMX바이트(bigint) 및 XNUMX바이트(smallint) 데이터 유형일 수 있습니다. 기본 GUID 데이터 유형에 대해 별도로 이야기합시다. 이 유형은 소위 글로벌 고유 식별자의 XNUMX바이트 값을 저장하기 위한 것입니다. 이 식별자의 모든 다른 값은 특수 내장 함수가 호출될 때 자동으로 생성됩니다. 신규 아이디(). 이 지정은 문자 그대로 "새로운 식별자 값"을 의미하는 완전한 영어 구문 New Identification에서 유래합니다. 특정 컴퓨터에서 생성된 각 식별자 값은 제조된 모든 컴퓨터 내에서 고유합니다. GUID 식별자는 특히 데이터베이스 복제를 구성하는 데 사용됩니다(예: 일부 기존 데이터베이스의 복사본을 생성할 때). 이러한 GUID는 다른 기본 유형과 함께 데이터베이스 개발자가 사용할 수 있습니다. GUID 유형과 다른 기본 유형 사이의 중간 위치는 다른 특수 기본 유형인 유형이 차지합니다. 카운터. 이 유형의 데이터를 지정하기 위해 특수 키워드가 사용됩니다. 카운터(x0, Δx), 문자 그대로 영어에서 번역되어 "카운터"를 의미합니다. 매개변수 x0 초기 값을 설정하고 ∆x - 증가 단계. 이 Counter 유형의 값은 반드시 정수입니다. 이 기본 데이터 유형으로 작업하는 데는 매우 흥미로운 기능이 많이 포함되어 있습니다. 예를 들어, 이 카운터 유형의 값은 설정되지 않습니다. 다른 모든 데이터 유형으로 작업할 때 익숙하기 때문에 글로벌 고유 식별자 유형의 값과 마찬가지로 요청 시 생성됩니다. 테이블을 정의할 때만 카운터 유형을 지정할 수 있는 것도 이례적입니다. 이 유형은 코드에서 사용할 수 없습니다. 또한 테이블을 정의할 때 하나의 열에 대해서만 카운터 유형을 지정할 수 있음을 기억해야 합니다. 행이 삽입되면 카운터 데이터 값이 자동으로 생성됩니다. 또한 이 생성은 반복 없이 수행되므로 카운터는 항상 각 라인을 고유하게 식별합니다. 그러나 이것은 카운터 데이터가 포함된 테이블로 작업할 때 약간의 불편을 야기합니다. 예를 들어, 테이블이 제공하는 관계의 데이터가 변경되어 삭제 또는 교환해야 하는 경우, 특히 경험이 없는 프로그래머가 작업 중인 경우 카운터 값이 쉽게 "카드를 혼동"할 수 있습니다. 그러한 상황을 보여주는 예를 들어보겠습니다. XNUMX개의 행이 입력된 일부 관계를 나타내는 다음 표가 주어집니다.
카운터는 자동으로 각 새 줄에 고유한 이름을 부여했습니다. 이제 테이블에서 두 번째와 네 번째 줄을 제거한 다음 한 줄을 추가해 보겠습니다. 이러한 작업을 수행하면 원본 테이블이 다음과 같이 변환됩니다.
따라서 카운터는 고유한 이름과 함께 두 번째 및 네 번째 줄을 제거하고 예상한 대로 새 줄에 "재할당"하지 않았습니다. 또한 데이터베이스 관리 시스템은 한 테이블에서 동시에 여러 카운터를 선언할 수 없는 것처럼 카운터 값을 수동으로 변경할 수 없습니다. 일반적으로 카운터는 서로게이트, 즉 테이블의 인공 키로 사용됩니다. 초당 한 값의 생성 속도로 100바이트 카운터의 고유한 값이 XNUMX년 이상 지속된다는 사실이 흥미롭습니다. 계산 방법을 보여 드리겠습니다. 1년 = 365일 * 24시간 * 60초 * 60초 < 366일 * 24시간 * 60초 * 60초 < 225 c. 1초 > 2-25 년 24*8 값 / 1 값/초 = 232 c > 27 년 > 100년. 2. 사용자 정의 데이터 유형 사용자 정의 데이터 유형은 원래 데이터베이스 관리 시스템에 구축되지 않았으며 기본 데이터 유형으로 선언되지 않았다는 점에서 모든 기본 유형과 다릅니다. 이 유형은 자신의 요청 및 요구 사항에 따라 모든 사용자 및 데이터베이스 프로그래머가 만들 수 있습니다. 따라서 사용자 정의 데이터 유형은 일부 기본 유형의 하위 유형입니다. 즉, 허용되는 값 집합에 일부 제한이 있는 기본 유형입니다. 의사 코드 표기법에서 사용자 지정 데이터 형식은 다음 표준 문을 사용하여 생성됩니다. 하위 유형 만들기 하위 유형 이름 타입 기본 유형 이름 As 하위 유형 제약 조건; 따라서 첫 번째 줄에는 새로운 사용자 정의 데이터 형식의 이름을 지정해야 하고 두 번째 줄에는 기존 기본 데이터 형식 중 어떤 형식을 모델로 삼아 자체적으로 생성하는지, 마지막으로 세 번째 줄에는 - 기본 데이터 유형의 값 집합에 대한 기존 제한 사항에 추가해야 하는 제한 사항 - 샘플. 하위 유형 제약 조건은 정의되는 하위 유형의 이름에 따라 조건으로 작성됩니다. Create 문의 작동 방식을 더 잘 이해하려면 다음 예를 고려하십시오. 예를 들어 메일에서 작업하기 위해 고유한 특수 데이터 유형을 만들어야 한다고 가정합니다. 우편번호와 같은 데이터로 작업하는 유형입니다. 우리의 숫자는 양수만 가능하다는 점에서 일반 십진수 XNUMX자리 숫자와 다릅니다. 필요한 하위 유형을 생성하는 연산자를 작성해 보겠습니다. 하위 유형 만들기 우편 번호 타입 십진수(6, 0) As 우편번호 > 0. 소수(6, 0)를 선택한 이유는 무엇입니까? 인덱스의 일반적인 형태를 상기하면, 그러한 숫자는 XNUMX에서 XNUMX까지 XNUMX개의 정수로 구성되어야 함을 알 수 있습니다. 이것이 우리가 기본 데이터 유형으로 XNUMX진수 유형을 취한 이유입니다. 일반적으로 기본 데이터 유형에 부과된 조건, 즉 하위 유형 제약 조건은 논리적 연결 not, and, or, 그리고 일반적으로 임의의 복잡성의 표현일 수 있습니다. 이러한 방식으로 정의된 사용자 정의 데이터 하위 유형은 프로그램 코드에서 그리고 테이블 열에 데이터 유형을 정의할 때 다른 기본 데이터 유형과 함께 자유롭게 사용할 수 있습니다. 즉, 기본 데이터 유형과 사용자 데이터 유형은 작업할 때 완전히 동일합니다. 시각적 개발 환경에서는 다른 기본 데이터 유형과 함께 유효한 유형 목록에 나타납니다. 우리 자신의 새로운 데이터베이스를 설계할 때 문서화되지 않은(사용자 정의된) 데이터 유형이 필요할 가능성은 상당히 높습니다. 실제로 기본적으로 가장 일반적인 작업을 해결하는 데 각각 적합한 가장 일반적인 데이터 유형만 데이터베이스 관리 시스템에 재봉됩니다. 주제 데이터베이스를 컴파일할 때 자신의 데이터 유형을 디자인하지 않고는 거의 불가능합니다. 그러나 흥미롭게도 같은 확률로 코드를 어지럽히고 복잡하게 만들지 않기 위해 우리가 만든 하위 유형을 제거해야 할 수도 있습니다. 이를 위해 데이터베이스 관리 시스템에는 일반적으로 특수 연산자가 내장되어 있습니다. 드롭, 이는 "제거"를 의미합니다. 불필요한 사용자 정의 유형을 제거하기 위한 이 연산자의 일반적인 형식은 다음과 같습니다. 하위 유형 삭제 사용자 정의 유형의 이름; 사용자 정의 데이터 유형은 일반적으로 충분히 일반적인 하위 유형에 권장됩니다. 3. 기본값 데이터베이스 관리 시스템은 임의의 기본값을 만들거나 기본값이라고도 하는 기능을 가질 수 있습니다. 거의 모든 작업에서 불변의 기본값인 상수를 도입해야 하기 때문에 모든 프로그래밍 환경에서 이 작업은 상당히 큰 비중을 차지합니다. 데이터베이스 관리 시스템에서 디폴트를 생성하기 위해 사용자 정의 데이터 유형의 통과에서 이미 우리에게 친숙한 함수가 사용됩니다 만들기. 기본값을 생성하는 경우에만 추가 키워드도 사용 디폴트 값, 이는 "기본값"을 의미합니다. 즉, 기존 데이터베이스에 기본값을 생성하려면 다음 명령문을 사용해야 합니다. 기본값 생성 기본 이름 As 상수 표현; 이 연산자를 적용할 때 상수 값 대신에 기본값이나 표현식으로 만들고자 하는 값이나 표현식을 작성해야 한다는 것은 분명합니다. 물론 데이터베이스에서 사용하는 것이 편리한 이름으로 결정하고 연산자의 첫 번째 줄에 이 이름을 작성해야 합니다. 이 특정 경우에 이 Create 문은 Microsoft SQL Server 시스템에 내장된 Transact-SQL 구문을 따릅니다. 그래서 우리는 무엇을 가지고 있습니까? 기본값은 객체와 마찬가지로 데이터베이스에 저장된 명명된 상수라고 추론했습니다. 시각적 개발 환경에서 기본값은 강조 표시된 기본값 목록에 나타납니다. 다음은 기본값을 만드는 예입니다. 데이터베이스의 올바른 작동을 위해 무언가의 무제한 수명을 의미하는 값 기능이 필요하다고 가정합니다. 그런 다음 이 데이터베이스의 값 목록에 이 요구 사항을 충족하는 기본값을 입력해야 합니다. 코드 텍스트에서 이 다소 성가신 표현을 만날 때마다 다시 작성하는 것이 매우 불편하기 때문에 필요할 수 있습니다. 그렇기 때문에 위의 Create 문을 사용하여 무언가의 무제한 수명을 의미하는 기본값을 생성합니다. 기본값 생성 "시간 제한 없음" As ‘9999-12-31 23: 59:59’ 여기서도 Transact-SQL 구문을 사용하여 날짜-시간 상수(이 경우 '9999-12-31 23:59:59')의 값을 특정 방향의 문자열로 작성하였다. 문자열을 날짜/시간 값으로 해석하는 것은 문자열이 사용되는 컨텍스트에 따라 결정됩니다. 예를 들어, 우리의 특별한 경우에는 먼저 연도의 제한 값이 상수 줄에 기록된 다음 시간이 기록됩니다. 그러나 모든 유용성을 위해 사용자 정의 데이터 유형과 같은 기본값은 때때로 제거를 요구할 수도 있습니다. 데이터베이스 관리 시스템에는 일반적으로 더 이상 필요하지 않은 사용자 정의 데이터 유형을 제거하는 연산자와 유사한 특수 내장 술어가 있습니다. 이것은 술어입니다 드롭 연산자 자체는 다음과 같습니다. 기본값 삭제 기본 이름; 4. 가상 속성 데이터베이스 관리 시스템의 모든 속성은 (관계와 절대적으로 유추하여) 기본 속성과 가상 속성으로 나뉩니다. 소위 기본 속성 두 번 이상 사용해야 하는 저장된 속성이므로 저장하는 것이 좋습니다. 그리고 차례로, 가상 속성 저장되지 않고 계산된 속성입니다. 무슨 뜻인가요? 이것은 소위 가상 속성의 값이 실제로 저장되지 않고 주어진 공식을 통해 즉석에서 기본 속성을 통해 계산된다는 것을 의미합니다. 이 경우 계산된 가상 속성의 도메인이 자동으로 결정됩니다. 두 개의 속성은 일반, 기본, 세 번째 속성은 가상인 관계를 정의하는 테이블의 예를 들어 보겠습니다. 특별히 입력된 공식에 따라 계산됩니다.
따라서 "Weight Kg" 및 "Price Rub per Kg" 속성은 일반 값을 가지며 데이터베이스에 저장되기 때문에 기본 속성임을 알 수 있습니다. 그러나 "비용" 속성은 계산 공식에 의해 설정되고 실제로 데이터베이스에 저장되지 않기 때문에 가상 속성입니다. 가상 속성은 그 속성상 기본값을 가질 수 없으며 일반적으로 가상 속성의 기본값이라는 개념 자체가 의미가 없으므로 적용할 수 없다는 점에 주목하는 것이 흥미로웠습니다. 또한 가상 속성의 영역은 자동으로 결정되지만 계산된 값의 유형을 기존 유형에서 다른 유형으로 변경해야 하는 경우도 있음을 알아야 합니다. 이를 위해 데이터베이스 관리 시스템의 언어에는 계산된 표현식의 유형을 재정의할 수 있는 특별한 Convert 술어가 있습니다. Convert는 소위 명시적 유형 변환 함수입니다. 다음과 같이 작성됩니다. 개 심자 (데이터 유형, 표현식); Convert 함수의 두 번째 인수인 표현식은 함수의 첫 번째 인수로 유형을 나타내는 데이터로 계산되어 출력됩니다. 예를 들어보겠습니다. "2 * 2" 표현식의 값을 계산해야 하지만 이것을 정수 "4"가 아니라 문자열로 출력해야 한다고 가정합니다. 이 작업을 수행하기 위해 다음 변환 함수를 작성합니다. 개 심자 (Char(1), 2 * 2). 따라서 우리는 Convert 함수의 이 표기법이 우리가 필요로 하는 결과를 정확히 제공한다는 것을 알 수 있습니다. 5. 키의 개념 기본 관계의 스키마를 선언할 때 여러 키를 선언할 수 있습니다. 우리는 전에 이것을 여러 번 겪었습니다. 마지막으로, 관계 키가 무엇인지에 대해 더 자세히 이야기할 때입니다. 일반적인 구문과 대략적인 정의에 국한되지 않습니다. 따라서 관계 키에 대해 엄밀히 정의해 보겠습니다. 관계 스키마 키 선언된 하나 이상의 속성으로 구성된 원래 스키마의 하위 스키마입니다. 독창성 조건 관계 튜플의 값. 유일성 조건이 무엇인지 이해하기 위해, 또는 소위 말하는 것처럼, 고유 제약, 튜플의 정의와 튜플을 하위 회로에 투영하는 단항 연산부터 시작하겠습니다. 가져오자: t = t(S) = {t(a) | a ∈ def( t) ⊆ S} - 튜플의 정의, t(S) [S' ] = {t(a) | a ∈ def (t) ∩ S'}, S' ⊆ S는 단항 투영 연산의 정의입니다. 하위 스키마에 대한 튜플의 투영은 테이블 행의 하위 문자열에 해당한다는 것이 분명합니다. 그렇다면 핵심 속성 고유성 제약 조건은 정확히 무엇입니까? 관계 S의 체계에 대한 키 K의 선언은 우리가 이미 말했듯이 다음과 같은 불변 조건의 공식화로 이어집니다. 고유성 제약 다음과 같이 표시됩니다. 인보이스 < K → 에스 > r(S): Inv < K → S > r(S) = ∀t1, 티2 ∈r(t 1[K]=t2 [케이] → t 1(에스) = t2(S)), K ⊆ S; 따라서 키 K의 이 고유성 제약 Inv < K → S > r(S)는 두 개의 튜플이 t1 и의 t2, 관계 r(S)에 속하는 키 K에 대한 투영이 동일하면 이는 필연적으로 이 두 튜플의 동일성과 관계 S의 전체 스키마에 대한 투영의 동일성을 수반합니다. 다시 말해 모든 값은 키 속성에 속하는 튜플의 관계는 고유하고 고유합니다. 그리고 관계 키에 대한 두 번째 중요한 요구 사항은 중복 요구 사항. 무슨 뜻인가요? 이 요구 사항은 키의 엄격한 하위 집합이 고유할 필요가 없음을 의미합니다. 직관적인 수준에서 핵심 속성은 관계의 각 튜플을 고유하고 정확하게 식별하는 관계 속성이라는 것이 분명합니다. 예를 들어, 테이블에 의해 주어진 다음 관계에서:
주요 속성은 "Gradebook #" 속성입니다. 다른 학생은 동일한 성적부 번호를 가질 수 없기 때문입니다. 즉, 이 속성에는 고유한 제약 조건이 적용됩니다. 어떤 관계의 스키마에서도 다양한 키가 발생할 수 있다는 점은 흥미롭습니다. 주요 유형의 키를 나열합니다. 1) 간단한 키 하나 이상의 속성으로 구성된 키입니다. 예를 들어, 특정 과목에 대한 시험 시트에서 간단한 키는 모든 학생을 고유하게 식별할 수 있는 신용 카드 번호입니다. 2) 복합 키 둘 이상의 속성으로 구성된 키입니다. 예를 들어, 교실 목록의 복합 키는 건물 번호와 교실 번호입니다. 결국 이러한 속성 중 하나로 각 청중을 고유하게 식별하는 것은 불가능하며 전체, 즉 복합 키를 사용하여 이를 수행하는 것은 매우 쉽습니다. 3) 슈퍼 키 모든 키의 상위 집합입니다. 따라서 관계 자체의 스키마는 확실히 슈퍼키입니다. 이것으로부터 우리는 이론적으로 모든 관계가 적어도 하나의 키를 가지고 있으며 그 중 여러 개를 가질 수 있다는 결론을 내릴 수 있습니다. 그러나 일반 키 대신 슈퍼키를 선언하는 것은 자동으로 적용되는 고유성 제약 조건을 완화해야 하므로 논리적으로 불법입니다. 결국 슈퍼 키는 고유한 속성을 가지고 있지만 비중복 속성이 없습니다. 4) 기본 키 기본 관계가 정의될 때 가장 먼저 선언된 키일 뿐입니다. 하나의 기본 키만 선언하는 것이 중요합니다. 또한 기본 키 속성은 null 값을 사용할 수 없습니다. 의사 코드 항목에서 기본 관계를 만들 때 기본 키는 다음과 같이 표시됩니다. 기본 키 대괄호 안에는 이 키인 속성의 이름이 있습니다. 5) 후보 키 기본 키 다음에 선언된 다른 모든 키입니다. 후보 키와 기본 키의 주요 차이점은 무엇입니까? 첫째, 여러 후보 키가 있을 수 있지만 기본 키는 위에서 언급한 대로 하나만 될 수 있습니다. 둘째, 기본 키의 속성이 Null 값을 사용할 수 없는 경우 이 조건이 후보 키의 속성에 부과되지 않습니다. 의사 코드에서 기본 관계를 정의할 때 단어를 사용하여 후보 키를 선언합니다. 후보 키 다음 대괄호 안에는 기본 키를 선언하는 경우와 같이 주어진 후보 키인 속성의 이름이 표시됩니다. 6) 외부 키 동일하거나 다른 기본 관계의 기본 또는 후보 키를 참조하는 기본 관계에서 선언된 키입니다. 이 경우 외래 키가 참조하는 관계를 참조(또는 부모의) 태도. 외래 키를 포함하는 관계를 호출합니다. 어린이. 의사 코드에서 외래 키는 다음과 같이 표시됩니다. 외래 키, 이 단어 바로 뒤의 괄호 안에는 외래키인 이 관계의 속성명을 표시하고 그 뒤에 키워드를 쓴다. 참조 ("참조") 기본 관계의 이름과 이 특정 외래 키가 참조하는 속성의 이름을 지정합니다. 또한 기본 관계를 만들 때 각 외래 키에 대해 다음과 같은 조건이 작성됩니다. 참조 무결성 제약 조건, 그러나 우리는 이것에 대해 나중에 자세히 이야기할 것입니다. 강의 #8 이 강의의 주제는 기본 관계 생성 연산자에 대한 상당히 상세한 논의가 될 것입니다. 의사 코드 기록에서 연산자 자체를 분석하고 모든 구성 요소와 작업을 분석하고 수정 방법, 즉 기본 관계를 변경하는 방법을 분석합니다. 1. 금속 언어 기호 기본 관계 생성 연산자를 의사 코드로 작성하는 데 사용되는 구문 구성을 설명할 때 다양한 방법이 사용됩니다. 금속 언어 기호. 이들은 모든 종류의 여는 대괄호와 닫는 대괄호, 점과 쉼표의 다양한 조합, 한마디로 각각 고유한 의미를 갖고 프로그래머가 코드를 더 쉽게 작성할 수 있도록 하는 기호입니다. 기본 관계의 설계에 가장 많이 사용되는 주요 금속 기호의 의미를 소개하고 설명하겠습니다. 그래서: 1) 금속 언어 문자 "{}". 중괄호의 구문 구조는 다음과 같습니다. 의무적 인 구문 단위. 기본 관계를 정의할 때 필수 요소는 예를 들어 기본 속성입니다. 기본 속성을 선언하지 않으면 관계를 설계할 수 없습니다. 따라서 의사 코드에서 기본 관계 생성 연산자를 작성할 때 기본 속성은 중괄호 안에 나열됩니다. 2) 금속 언어 기호 "[]". 이 경우에는 반대입니다. 대괄호로 묶인 구문 구조는 다음을 나타냅니다. 선택 과목 구문 요소. 기본 관계 생성 연산자의 선택적 구문 단위는 차례로 기본, 후보 및 외래 키의 가상 속성입니다. 물론 여기에도 미묘함이 있지만 기본 관계를 생성하기 위한 연산자 설계로 직접 진행할 때 나중에 이에 대해 이야기하겠습니다. 3) 금속 언어 기호 "|". 이 기호는 말 그대로 "또는", 수학의 유사한 기호처럼. 이 금속 언어 기호의 사용은 이 기호로 각각 분리된 둘 이상의 구성 중에서 선택해야 함을 의미합니다. 4) 금속 언어 기호 "...". 구문 단위 바로 뒤에 생략 부호가 있으면 다음과 같은 가능성이 있음을 의미합니다. 되풀이 금속 언어 기호 앞에 오는 이러한 구문 요소; 5) 금속 언어 기호 ",..". 이 기호는 이전 기호와 거의 같은 의미입니다. 금속 언어 기호 ",.."를 사용할 때만, 반복 구문 구조가 발생합니다 쉼표로 구분훨씬 더 편리한 경우가 많습니다. 이를 염두에 두고 다음 두 구문 구조의 동등성에 대해 이야기할 수 있습니다. 단위 [, 단위]... и 단위,.. ; 2. 의사코드 항목에서 기본 관계를 생성하는 예 이제 기본 관계 생성 연산자를 의사 코드로 작성할 때 사용되는 주요 금속 언어 기호의 의미를 설명했으므로 이 연산자 자체에 대한 실제 고려를 진행할 수 있습니다. 위의 참조에서 알 수 있듯이 의사 코드 항목에서 기본 관계를 생성하는 연산자에는 기본 및 가상 속성, 기본, 후보 및 외래 키의 선언이 포함됩니다. 또한 위에서 보여주고 설명할 것처럼 이 연산자는 속성 값 제약 조건과 튜플 제약 조건은 물론 소위 참조 무결성 제약 조건도 다룹니다. 처음 두 개의 제약 조건, 즉 속성 값 제약 조건과 튜플 제약 조건은 특수 예약어 뒤에 선언됩니다. 검사. 참조 무결성 제약 조건은 두 가지 유형이 있습니다. 업데이트 중, 이는 "업데이트할 때"를 의미하며, 삭제시, "삭제 중"을 의미합니다. 무슨 뜻인가요? 즉, 외래 키가 참조하는 관계의 속성을 업데이트하거나 삭제할 때 상태 무결성이 유지되어야 합니다. (이에 대해서는 나중에 더 이야기하겠습니다.) 기본 관계 생성 연산자 자체는 이미 연구된 우리가 사용하는 연산자입니다. 만들기, 기본 관계를 생성하기 위해서만 키워드가 추가됩니다. 테이블 ("태도"). 물론 관계 자체가 더 크고 이전에 논의된 모든 구성과 새로운 추가 구성을 포함하기 때문에 생성 연산자는 상당히 인상적일 것입니다. 따라서 기본 관계를 생성하는 데 사용되는 연산자의 일반적인 형식을 의사 코드로 작성해 보겠습니다. 표 만들기 기본 관계 이름 { 기본 속성 이름 기본 속성 값 유형 검사 (속성값 제한) {널 | Null이 아님} 디폴트 값 (기본값) },.. [가상 속성 이름 as (계산식) ],.. [,검사 (튜플 제약)] [,기본 키 (속성 이름,..)] [,후보 키 (속성 이름,..)]... [,외래 키 (속성 이름,..) 참조 참조 관계 이름(속성 이름,..) 업데이트 시 { 제한 | 캐스케이드 | Null 설정} 삭제 시 { 제한 | 캐스케이드 | Null 설정} ] ... 따라서 해당 구문 구조 뒤에 금속 언어 기호 ",.."가 있기 때문에 몇 가지 기본 및 가상 속성, 후보 및 외래 키를 선언할 수 있음을 알 수 있습니다. 기본 키를 선언한 후에는 이 기호가 존재하지 않습니다. 앞서 언급한 기본 관계가 기본 키를 하나만 허용하기 때문입니다. 다음으로 선언 메커니즘을 자세히 살펴보겠습니다. 기본 속성. 기본 관계 생성 연산자에서 속성을 설명할 때 일반적으로 이름, 유형, 값에 대한 제한, Null 값 유효성 플래그 및 기본값이 지정됩니다. 속성의 유형과 값 제약 조건이 해당 도메인, 즉 문자 그대로 해당 특정 속성에 대한 유효한 값 집합을 결정한다는 것을 쉽게 알 수 있습니다. 속성 값 제한 속성 이름에 따라 조건으로 작성됩니다. 다음은 이 자료를 더 쉽게 이해할 수 있는 작은 예입니다. 표 만들기 기본 관계 이름 코스 정수 검사 (1 <= 코스 및 코스 <= 5; 여기서 "1 <= Heading and Heading <= 5" 조건은 정수 데이터 유형의 정의와 함께 속성의 허용된 값 집합, 즉 문자 그대로 해당 도메인을 실제로 완전히 조건화합니다. Null 값 허용 플래그(Null | Null 아님)는 속성 값 중 Null 값의 출현을 금지(Null 아님)하거나 반대로 허용(Null)합니다. 방금 논의한 예를 보면 Null 유효성 플래그를 적용하는 메커니즘은 다음과 같습니다. 표 만들기 기본 관계 이름 코스 정수 검사 (1 <= 코스 및 코스 <= 5); 널이 아님; 따라서 학생의 과정 번호는 null이 될 수 없으며 데이터베이스 컴파일러에 알 수 없으며 존재할 수 없습니다. 기본값 (디폴트 값 (기본값))은 속성 값이 insert 문에 명시적으로 설정되지 않은 경우 관계에 튜플을 삽입할 때 사용됩니다. 특정 속성에 대한 Null 값이 유효하다고 선언되는 한 기본값은 Null 값일 수도 있다는 점에 주목하는 것이 좋습니다. 이제 정의를 고려하십시오. 가상 속성 기본 관계 생성 연산자에서. 앞에서 말했듯이 가상 속성을 설정하는 것은 다른 기본 속성을 통한 계산 공식을 설정하는 것입니다. 가상 속성 "Cost Rub"를 선언하는 예를 살펴보겠습니다. 기본 속성 "중량 Kg" 및 "Kg당 가격 문지름"에 따라 수식 형태로. 표 만들기 기본 관계 이름 무게, kg 기본 속성 값 유형 무게 Kg 검사 (속성값 Weight Kg의 제한) 널이 아님 디폴트 값 (기본값) 가격, 문질러. kg 당 기본 속성 Price Rub의 값 유형입니다. kg 당 검사 (Kg당 Price Rub. 속성 값의 제한) 널이 아님 디폴트 값 (기본값) ... 비용, 문질러. as (무게 Kg * Kg당 가격 문지름) 조금 전에 속성 이름에 종속된 조건으로 작성된 속성 제약 조건을 살펴보았습니다. 이제 기본 관계를 생성할 때 선언된 두 번째 종류의 제약 조건을 고려하십시오. 튜플 제약 조건. 튜플 제약 조건은 무엇이며 속성 제약 조건과 어떻게 다릅니까? 튜플 제약 조건도 기본 속성 이름에 종속된 조건으로 작성되지만 튜플 제약 조건의 경우에만 조건이 동시에 여러 속성 이름에 종속될 수 있습니다. 튜플 제약 조건으로 작업하는 메커니즘을 보여주는 예를 고려하십시오. 표 만들기 기본 관계 이름 최소 무게 Kg 기본 속성의 값 유형 최소 무게 Kg 검사 (속성값 min Weight Kg의 제한) 널이 아님 디폴트 값 (기본값) 최대 무게 Kg 기본 속성의 값 유형 최대 무게 Kg 검사 (속성값 max Weight Kg의 제한) 널이 아님 디폴트 값 (기본값) 검사 (0 < 최소 무게 Kg 와 최소 무게 Kg < 최대 무게 Kg); 따라서 튜플에 제약 조건을 적용하는 것은 속성 이름을 튜플 값으로 대체하는 것과 같습니다. 기본 관계 생성 연산자에 대해 살펴보겠습니다. 일단 선언되면 기본 및 가상 속성은 선언되거나 선언되지 않을 수 있습니다. 열쇠: 기본, 후보 및 외부. 이전에 말했듯이 다른(또는 동일한) 기본 관계에서 첫 번째 관계의 컨텍스트에서 기본 또는 후보 키에 해당하는 기본 관계의 하위 스키마를 호출합니다. 외래 키. 외래 키는 다음을 나타냅니다. 링크 메커니즘 다른 관계의 튜플에 대한 일부 관계의 튜플, 즉 이미 언급된 소위의 부과와 관련된 외래 키 선언이 있습니다. 참조 무결성 제약 조건. (상태 무결성(즉, 무결성 제약 조건에 의해 적용되는 무결성)이 기본 관계 및 전체 데이터베이스의 성공에 중요하기 때문에 이 제약 조건은 다음 강의의 초점이 될 것입니다.) 기본 및 후보 키를 선언하면 앞서 논의한 기본 관계 스키마에 적절한 고유성 제약 조건이 부과됩니다. 그리고 마지막으로 기본 관계를 삭제할 가능성에 대해 말해야 합니다. 종종 데이터베이스 디자인 실습에서 프로그램 코드를 어지럽히지 않도록 오래된 불필요한 관계를 제거해야 합니다. 이것은 이미 친숙한 연산자를 사용하여 수행할 수 있습니다. 드롭. 전체 일반 형식에서 기본 관계 삭제 연산자는 다음과 같습니다. 드롭 테이블 기본 관계의 이름; 3. 국가별 무결성 제약 무결성 제약 관계형 데이터 개체 조건에 따라 이른바 데이터 불변량이다. 동시에 무결성은 보안과 확실하게 구별되어야 하며, 이는 차례로 데이터를 공개, 수정 또는 파괴하기 위해 무단 액세스로부터 데이터를 보호함을 의미합니다. 일반적으로 관계형 데이터 개체에 대한 무결성 제약 조건은 다음과 같이 분류됩니다. 계층 구조 수준별 이러한 동일한 관계형 데이터 개체(관계형 데이터 개체의 계층 구조는 중첩된 개념의 시퀀스입니다. "속성 - 튜플 - 관계 - 데이터베이스"). 이것은 무엇을 의미 하는가? 이는 무결성 제약 조건이 다음에 의존한다는 것을 의미합니다. 1) 속성 수준에서 - 속성 값에서; 2) 튜플 수준에서 - 튜플의 값에서, 즉 여러 속성의 값에서; 3) 관계 수준에서 - 관계, 즉 여러 튜플에서 4) 데이터베이스 수준에서 - 여러 관계에서. 따라서 이제 위의 각 개념의 상태에 대한 무결성 제약 조건을 더 자세히 고려하는 것만 남아 있습니다. 그러나 먼저 상태 무결성 제약 조건에 대한 절차적 및 선언적 지원의 개념을 살펴보겠습니다. 따라서 무결성 제약 조건에 대한 지원은 두 가지 유형이 될 수 있습니다. 1) 절차상의, 즉, 프로그램 코드를 작성하여 생성됩니다. 2) 선언적즉, 위의 각 중첩 개념에 대한 특정 제한을 선언하여 생성됩니다. 무결성 제약 조건에 대한 선언적 지원은 기본 관계를 만들기 위한 Create 문의 컨텍스트에서 구현됩니다. 이에 대해 더 자세히 이야기해 보겠습니다. 관계형 데이터 개체의 계층적 사다리의 맨 아래, 즉 속성의 개념에서 제한 집합을 고려하기 시작하겠습니다. 속성 레벨 제약 다음을 포함합니다 : 1) 속성 값의 유형에 대한 제한. 예를 들어, 값에 대한 정수 조건, 즉 앞에서 설명한 기본 관계 중 하나의 "Course" 속성에 대한 정수 조건입니다. 2) 속성 이름에 의존하는 조건으로 작성된 속성 값 제약. 예를 들어 이전 단락과 동일한 기본 관계를 분석하면 해당 관계에서 옵션을 사용하는 속성 값에 대한 제약도 있음을 알 수 있습니다. 검사, 즉.: 검사 (1 <= 코스 및 코스 <= 5); 3) 속성 수준 제약 조건에는 잘 알려진 유효성 플래그(Null) 또는 반대로 Null 값의 허용 불가(Null 아님)에 의해 정의된 Null 값 제약 조건이 포함됩니다. 앞에서 언급했듯이 처음 두 제약 조건은 속성의 도메인 제약 조건, 즉 정의 집합의 값을 정의합니다. 또한 관계형 데이터 개체의 계층적 사다리에 따르면 튜플에 대해 이야기해야 합니다. 그래서, 튜플 수준 제약 조건 튜플 제약으로 축소되고 관계 스키마의 여러 기본 속성의 이름에 의존하는 조건으로 작성됩니다. 즉, 이 상태 무결성 제약은 속성에만 해당하는 유사한 것보다 훨씬 작고 간단합니다. 그리고 다시, 우리가 지금 필요로 하는 튜플 제약이 있는 기본 관계의 예를 기억하는 것이 유용할 것입니다. 즉: 검사 (0 < 최소 무게 Kg 와 최소 무게 Kg < 최대 무게 Kg); 그리고 마지막으로 상태에 대한 무결성 제약의 맥락에서 마지막으로 중요한 개념은 관계 수준의 개념입니다. 우리가 전에 말했듯이, 관계 수준 제약 기본 값 제한을 포함합니다(기본 키) 및 후보자(후보 키) 키. 데이터베이스에 부과된 제한 사항이 더 이상 상태 무결성 제약 조건이 아니라 참조 무결성 제약 조건이라는 점이 궁금합니다. 4. 참조 무결성 제약 조건 따라서 데이터베이스 수준 제약 조건에는 외래 키 참조 무결성 제약 조건(외래 키). 기본 관계와 외래 키를 생성할 때 참조 무결성 제약 조건에 대해 이야기할 때 이미 간략하게 언급했습니다. 이제 이 개념에 대해 더 자세히 이야기할 시간입니다. 앞에서 말했듯이 선언된 기본 관계의 외래 키는 다른(가장 자주) 기본 관계의 기본 또는 후보 키를 참조합니다. 이 경우 외래 키가 참조하는 관계를 참조 또는 부모의, 참조하는 기본 관계에서 하나의 속성 또는 여러 속성을 일종의 "생성"하기 때문입니다. 그리고 차례로 외래 키를 포함하는 관계를 호출합니다. 어린이, 또한 명백한 이유. 이것은 참조 무결성 제약 조건? 그리고 그것은 외부 키의 값이 어떤 속성에서도 Null 값을 포함하지 않는 한, 자식 관계의 외래 키의 각 값이 반드시 부모 관계의 모든 키의 값과 반드시 일치해야 한다는 사실로 구성됩니다. 이 조건을 위반하는 자식 관계의 튜플을 호출합니다. 교수형. 실제로 자식 릴레이션의 외래 키가 부모 릴레이션에 실제로 존재하지 않는 속성을 참조하는 경우 아무 것도 참조하지 않습니다. 가능한 모든 방법으로 피해야 하는 것은 바로 이러한 상황이며, 이는 참조 무결성을 유지하는 것을 의미합니다. 그러나 어떤 데이터베이스도 댕글링 튜플 생성을 허용하지 않는다는 사실을 알고 있기 때문에 개발자는 데이터베이스에 처음에 댕글링 튜플이 없고 사용 가능한 모든 키가 부모 관계의 매우 실제 속성을 참조하는지 확인합니다. 그럼에도 불구하고 데이터베이스 운영 중에 이미 댕글링 튜플이 형성되는 상황이 있습니다. 이러한 상황은 무엇입니까? 부모 관계에서 튜플이 제거되거나 부모 관계의 튜플 키 값이 업데이트되면 참조 무결성이 위반될 수 있습니다. 즉, 댕글링 튜플이 발생할 수 있습니다. 외래 키 값을 선언할 때 발생 가능성을 배제하기 위해 다음 중 하나를 지정합니다. C SЂRμS ... 사용할 수있는 규정 부모 관계의 키 값을 업데이트할 때 그에 따라 적용되는 참조 무결성 유지(즉, 앞에서 언급했듯이, 업데이트 중) 또는 상위 관계에서 튜플을 제거할 때(삭제시). 명백한 이유로 부모 관계에 새 튜플을 추가해도 참조 무결성이 손상될 수 없습니다. 결국 이 튜플이 기본 관계에 추가된 경우 속성이 없기 때문에 이전에 해당 튜플을 참조할 수 없습니다! 그렇다면 데이터베이스에서 참조 무결성을 유지하는 데 사용되는 이 세 가지 규칙은 무엇입니까? 그것들을 나열해 봅시다. 1. 제한또는 제한 규칙. 기본 관계를 설정할 때 참조 무결성 제약 조건에서 외래 키를 선언할 때 이를 유지 관리하는 이 규칙을 적용한 경우 이 튜플이 자식 관계의 적어도 하나의 튜플에 의해 참조됩니다. 제한 행잉 튜플의 출현으로 이어질 수 있는 모든 작업을 수행하는 것을 엄격히 금지합니다. 다음 예를 통해 이 규칙의 적용을 설명합니다. 두 가지 관계가 주어집니다. 부모의 태도
자녀 관계
하위 관계 튜플 (2,...) 및 (2,...)는 상위 관계 튜플 (..., 2)를 참조하고 하위 관계 튜플 (3,...)은 다음을 참조하는 것을 알 수 있습니다. ( ..., 3) 부모의 태도. 하위 관계의 튜플(100,...)이 매달려 있고 유효하지 않습니다. 여기서는 상위 관계 튜플 (..., 1) 및 (..., 4)만이 하위 관계의 외래 키에 의해 참조되지 않기 때문에 키 값이 업데이트되고 튜플이 삭제되도록 허용합니다. 위의 모든 키 선언을 포함하는 기본 관계를 생성하기 위한 연산자를 작성해 보겠습니다. 표 만들기 부모의 태도 기본_키 정수 널이 아님 기본 키 (기본_키) 표 만들기 자녀 관계 Foreign_key 정수 null로 외래 키 (외부키) 참조 상위 관계(Primary_key) 업데이트 시 제한 삭제 제한 2. 작은 폭포또는 캐스케이드 수정 규칙. 기본 관계에서 외래 키를 선언할 때 참조 무결성 유지 규칙을 사용한 경우 작은 폭포, 그런 다음 상위 관계에서 키를 업데이트하거나 상위 관계에서 튜플을 삭제하면 하위 관계의 해당 키와 튜플이 자동으로 업데이트되거나 삭제됩니다. 계단식 수정 규칙이 어떻게 작동하는지 더 잘 이해하기 위해 예를 살펴보겠습니다. 이전 예에서 이미 친숙한 기본 관계가 주어집니다. 부모의 태도
и 자녀 관계
"상위 관계" 관계를 정의하는 테이블의 일부 튜플을 업데이트한다고 가정합니다. 즉, 튜플 (..., 2)를 튜플 (..., 20)으로 대체합니다. 즉, 새로운 관계를 얻습니다. 부모의 태도
그리고 동시에 외래 키를 선언할 때 기본 관계인 "자식 관계"를 생성한다는 진술에서 참조 무결성을 유지하는 규칙을 사용했습니다. 작은 폭포, 즉 기본 관계를 생성하기 위한 연산자는 다음과 같습니다. 표 만들기 부모의 태도 기본_키 정수 널이 아님 기본 키 (기본_키) 표 만들기 자녀 관계 Foreign_key 정수 null로 외래 키 (외부키) 참조 상위 관계(Primary_key) 캐스케이드 업데이트 시 캐스케이드 삭제 시 그러면 위에서 설명한 방식으로 상위 관계가 업데이트되면 하위 관계는 어떻게 됩니까? 다음 형식을 취합니다. 자녀 관계
따라서 실제로 규칙 작은 폭포 상위 관계에 대한 업데이트에 대한 응답으로 하위 관계의 모든 튜플에 대한 계단식 업데이트를 제공합니다. 3. Null로 설정또는 널 할당 규칙. 기본 관계를 생성하는 문에서 외래 키를 선언할 때 참조 무결성 유지 규칙을 적용하면 Null로 설정그런 다음 상위 관계의 키를 업데이트하거나 상위 관계에서 튜플을 삭제하면 Null 값을 허용하는 하위 관계의 외래 키 속성에 Null 값이 자동으로 할당됩니다. 따라서 그러한 속성이 존재하는 경우 규칙이 적용됩니다. 이전에 이미 사용한 예를 살펴보겠습니다. 두 가지 기본 관계가 주어졌다고 가정합니다. "육아"
자녀 관계
보시다시피 자식 관계 속성은 Null 값을 허용하므로 규칙 Null로 설정 이 특별한 경우에 적용됩니다. 이제 이전 예제에서와 같이 튜플 (..., 1)이 상위 관계에서 제거되고 튜플 (..., 2)가 업데이트되었다고 가정해 보겠습니다. 따라서 상위 관계는 다음과 같은 형식을 취합니다. 부모의 태도
그런 다음 자식 관계의 외래 키를 선언할 때 참조 무결성을 유지하는 규칙을 적용했다는 사실을 고려하여 Null로 설정, 자식 관계는 다음과 같습니다. 자녀 관계
튜플 (..., 1)은 하위 관계 키에서 참조되지 않았으므로 삭제해도 아무런 결과가 없습니다. 규칙을 사용하는 기본 관계 생성 연산자 자체 Null로 설정 외래 키를 선언할 때 관계는 다음과 같습니다. 표 만들기 부모의 태도 기본_키 정수 널이 아님 기본 키 (기본_키) 표 만들기 자녀 관계 Foreign_key 정수 null로 외래 키 (외부키) 참조 상위 관계(Primary_key) 업데이트 시 Null로 설정 삭제 시 Null 설정 따라서 참조 무결성을 유지하기 위한 세 가지 다른 규칙이 있다는 것을 알 수 있습니다. 업데이트 중 и 삭제시 기능이 다를 수 있습니다. 튜플을 자식 관계에 삽입하거나 자식 관계의 키 값을 업데이트하는 것이 참조 무결성 위반, 즉 소위 댕글링 튜플의 출현으로 이어지는 경우 수행되지 않는다는 것을 기억하고 이해해야 합니다. 어떤 상황에서도 자식 관계에서 튜플을 제거하면 참조 무결성을 위반할 수 있습니다. 다른 기본 관계의 외래 키가 해당 속성 중 일부를 기본 키로 참조하는 경우 자식 관계가 참조 무결성을 유지하기 위한 자체 규칙을 사용하여 부모 관계로 동시에 작동할 수 있다는 것은 흥미로운 일입니다. 프로그래머가 위의 표준 규칙 이외의 일부 규칙에 의해 참조 무결성이 적용되도록 하려면 참조 무결성을 유지하기 위한 이러한 비표준 규칙에 대한 절차 지원이 소위 트리거의 도움으로 제공됩니다. 불행히도 이 개념에 대한 자세한 고려는 강의 과정에 포함되지 않습니다. 5. 지수의 개념 기본 관계에서 키 생성은 인덱스 생성과 자동으로 연결됩니다. 인덱스의 개념을 정의합시다. 색인 - 이것은 이러한 값이 발생하는 관계의 해당 튜플에 대한 링크가 있는 키 값의 반드시 순서가 지정된 목록을 포함하는 시스템 데이터 구조입니다. 데이터베이스 관리 시스템에는 두 가지 유형의 인덱스가 있습니다. 1) 단순한. 단일 속성에서 기본 관계의 스키마 하위 스키마에 대해 단순 색인을 가져옵니다. 2) 합성물. 따라서 복합 인덱스는 여러 속성으로 구성된 하위 스키마에 대한 인덱스입니다. 그러나 단순 인덱스와 복합 인덱스로 나누는 것 외에도 데이터베이스 관리 시스템에서는 인덱스를 고유 인덱스와 비고유 인덱스로 구분합니다. 그래서: 1) 유일한 인덱스는 최대 하나의 속성을 참조하는 인덱스입니다. 고유 인덱스는 일반적으로 관계의 기본 키에 해당합니다. 2) 고유하지 않은 인덱스는 동시에 여러 속성과 일치할 수 있는 인덱스입니다. 고유하지 않은 키는 대부분 관계의 외래 키에 해당합니다. 인덱스를 고유한 인덱스와 고유하지 않은 인덱스로 나누는 예를 고려하십시오. 즉, 테이블에 의해 정의된 다음 관계를 고려하십시오.
여기서 각각 기본 키는 관계의 기본 키이고 외래 키는 외래 키입니다. 이러한 관계에서 Primary key 속성의 인덱스는 기본 키, 즉 하나의 속성에 해당하므로 고유하고, Foreign key 속성의 인덱스는 foreign에 해당하므로 고유하지 않음이 분명합니다. 키. 그리고 값 "20"은 관계 테이블의 첫 번째 행과 세 번째 행 모두에 해당합니다. 그러나 때때로 키와 관계없이 인덱스를 생성할 수 있습니다. 이것은 정렬 및 검색 작업의 성능을 지원하기 위해 데이터베이스 관리 시스템에서 수행됩니다. 예를 들어 튜플의 인덱스 값에 대한 이분법 검색은 데이터베이스 관리 시스템에서 XNUMX회 반복으로 구현됩니다. 이 정보는 어디에서 왔습니까? 그들은 간단한 계산, 즉 다음과 같이 얻어졌습니다. 106 = (103)2 = 220; 인덱스는 이미 알려진 Create 문을 사용하여 데이터베이스 관리 시스템에서 생성되지만 인덱스 키워드를 추가해야만 생성됩니다. 이러한 연산자는 다음과 같습니다. 인덱스 작성 인덱스 이름 On 기본 관계 이름(속성 이름,..); 여기서 우리는 쉼표로 구분된 인수를 반복할 가능성을 나타내는 친숙한 금속 언어 기호 ",.."를 봅니다. 즉, 이 연산자에서 여러 속성에 해당하는 인덱스를 만들 수 있습니다. 고유 인덱스를 선언하려면 인덱스 단어 앞에 unique 키워드를 추가하면 기본 인덱스 관계의 전체 생성 문이 다음과 같이 됩니다. 고유 인덱스 생성 인덱스 이름 On 기본 관계 이름(속성 이름); 그런 다음 가장 일반적인 형태로 선택적 요소(금속 언어 기호 [])를 지정하는 규칙을 상기하면 기본 관계의 인덱스 생성 연산자는 다음과 같습니다. [고유] 인덱스 생성 인덱스 이름 On 기본 관계 이름(속성 이름,..); 기본 관계에서 이미 존재하는 인덱스를 제거하려면 이미 알려진 Drop 연산자를 사용하십시오. 드롭 인덱스 {기본 관계 이름. 인덱스 이름},.. ; 여기에서 정규화된 인덱스 이름 "기본 관계 이름. 인덱스 이름"이 사용되는 이유는 무엇입니까? 인덱스 이름은 동일한 관계 내에서 고유해야 하지만 그 이상은 아니므로 인덱스 삭제 연산자는 항상 정규화된 이름을 사용합니다. 6. 기본 관계의 수정 다양한 기본 관계를 성공적으로 생산적으로 사용하려면 개발자가 이 기본 관계를 어떤 식으로든 수정해야 하는 경우가 많습니다. 데이터베이스 설계 실무에서 가장 자주 접하게 되는 주요 수정 옵션은 무엇입니까? 다음과 같이 나열해 보겠습니다. 1) 튜플 삽입. 매우 자주 이미 형성된 기본 관계에 새 튜플을 삽입해야 합니다. 2) 속성 값 업데이트. 그리고 프로그래밍 실습에서 이러한 수정의 필요성은 이전 것보다 훨씬 더 일반적입니다. 데이터베이스의 인수에 대한 새로운 정보가 도착하면 불가피하게 일부 오래된 정보를 업데이트해야 하기 때문입니다. 3) 튜플 제거. 그리고 거의 동일한 확률로 새로운 정보를 수신하여 데이터베이스에 더 이상 존재하지 않아도 되는 튜플을 기본 관계에서 제거해야 합니다. 그래서 우리는 기본 관계를 수정하는 주요 사항을 설명했습니다. 각각의 목표를 어떻게 달성할 수 있습니까? 데이터베이스 관리 시스템에는 대부분 기본 제공되는 기본 관계 수정 연산자가 있습니다. 의사 코드 항목으로 설명하겠습니다. 1) 삽입 연산자 새로운 튜플의 기본 관계로. 운영자입니다 끼워 넣다. 다음과 같습니다. 에 집어 넣다 기본 관계 이름(속성 이름,..) 마케팅은: (속성값,..); 속성 이름과 속성 값 뒤에 있는 금속 언어 기호 ",.."는 이 연산자를 사용하여 여러 속성을 동시에 기본 관계에 추가할 수 있음을 알려줍니다. 이 경우 속성 이름과 속성 값을 쉼표로 구분하여 일관된 순서로 나열해야 합니다. 키워드 으로 연산자의 일반 이름과 함께 끼워 넣다 "삽입"을 의미하고 괄호 안의 속성이 삽입될 관계를 나타냅니다. 키워드 마케팅은: 이 명령문에서 "values", "values"를 의미하며 새로 선언된 속성에 할당됩니다. 2) 이제 고려 업데이트 연산자 기본 관계의 속성 값. 이 연산자는 업데이트, 영어에서 번역되어 문자 그대로 "업데이트"를 의미합니다. 이 연산자의 전체 일반 형식을 의사 코드 표기법으로 지정하고 해독해 보겠습니다. 업데이트 기본 관계 이름 세트 {속성 이름 - 속성 값},.. 어디에 상태; 따라서 키워드 다음 연산자의 첫 번째 줄에서 업데이트 업데이트될 기본 관계의 이름이 기록됩니다. Set 키워드는 영어에서 "set"으로 번역되며 명령문의 이 줄은 업데이트할 속성의 이름과 해당하는 새 속성 값을 지정합니다. 금속 언어 기호 ",.."의 사용에 따라 하나의 명령문에서 여러 속성을 한 번에 업데이트할 수 있습니다. 키워드 다음 세 번째 줄 어디에 이 기본 관계의 어떤 속성을 업데이트해야 하는지 정확히 보여주는 조건이 작성됩니다. 3) 연산자 .허용 제거하다 기본 관계의 모든 튜플. 전체 형식을 의사 코드로 작성하고 모든 개별 구문 단위의 의미를 설명하겠습니다. 삭제 위치 기본 관계 이름 어디에 상태; 키워드 에 운영자 이름과 결합 . "에서 제거"로 번역됩니다. 그리고 연산자의 첫 번째 줄에 있는 이러한 키워드 뒤에는 튜플을 제거해야 하는 기본 관계의 이름이 표시됩니다. 그리고 키워드 다음 연산자의 두 번째 줄에서 어디에 ("where")는 기본 관계에서 더 이상 필요하지 않은 튜플이 선택되는 조건을 나타냅니다. 강의 번호 9. 기능적 종속성 1. 기능적 의존성의 제한 관계의 기본 및 후보 키 선언에 의해 부과되는 고유성 제약은 개념과 관련된 제약의 특별한 경우입니다. 기능적 종속성. 기능적 종속성의 개념을 설명하기 위해 다음 예를 고려하십시오. 특정 세션의 결과에 대한 데이터를 포함하는 관계가 주어집니다. 이 관계의 스키마는 다음과 같습니다. 세션(레코드 북 번호, 성명, 제목, 등급); "성적부 번호" 및 "제목" 속성은 이 관계의 복합 기본 키를 형성합니다(XNUMX개의 속성이 키로 선언됨). 실제로 이 두 속성은 다른 모든 속성의 값을 고유하게 결정할 수 있습니다. 그러나 이 키와 관련된 고유성 제약 조건 외에도 관계는 반드시 한 명의 특정 사람에게 하나의 성적 기록이 발급된다는 조건을 따라야 하며, 따라서 이와 관련하여 동일한 성적 기록 번호를 가진 튜플은 동일한 값을 포함해야 합니다. "성" 속성의 "이름 및 중간 이름".
특정 세션 후에 교육 기관의 특정 데이터베이스에 대한 다음 조각이 있는 경우 성적 기록 번호가 100인 튜플에서 "성", "이름" 및 "패트러니믹" 속성은 동일합니다. 및 속성 "주제" 및 "평가" - 일치하지 않습니다(다른 주제 및 성과에 대해 이야기하고 있기 때문에 이해할 수 있습니다). 이는 속성 "성", "이름" 및 "패트러니믹"을 의미합니다. 기능적으로 의존적인 속성 "성적부 번호"에 대한 반면 속성 "제목" 및 "평가"는 기능적으로 독립적입니다. 따라서, 기능적 의존성 데이터베이스 관리 시스템에서 표로 작성된 단일 값 종속성입니다. 이제 우리는 기능적 종속성에 대한 엄격한 정의를 제공합니다. 정의: X, Y를 관계 S의 체계의 하위 체계라고 하고 체계 S를 정의합니다. 기능적 종속성 다이어그램 X → Y ("X 화살표 Y" 읽기). 정의하자 기능적 종속성 제약 조건 inv<X → Y> 스키마 S와 관련하여 하위 스키마 X에 대한 투영과 일치하는 두 개의 튜플은 하위 스키마 Y에 대한 투영도 일치해야 합니다. 수식 형식으로 동일한 정의를 작성해 보겠습니다. 인보이스<X → Y> 아르(에스) = 티1, 티2 ∈r(t1[엑스] = t2[X] ⇒ t1[Y]=t2 [Y]), X, Y ⊆ S; 흥미롭게도 이 정의는 이전에 접했던 단항 투영 연산의 개념을 사용합니다. 실제로, 이 작업을 사용하지 않고 행이 아닌 관계 테이블의 두 열이 서로 동등함을 표시하려면 어떻게 해야 합니까? 따라서 우리는 이 작업의 관점에서 일부 속성 또는 여러 속성(하위 스키마 X)에 대한 투영에서 튜플의 일치는 Y가 기능적으로 종속되는 경우 하위 스키마 Y에 대한 동일한 열-튜플의 일치를 확실히 수반한다고 썼습니다. X . X에 대한 Y의 기능적 종속의 경우 X가 기능적으로 정의 Y 또는 무엇 Y 기능적으로 의존적인 X에서. X → Y 기능 종속성 체계에서 하위 회로 X를 왼쪽이라고 하고 하위 회로 Y를 오른쪽이라고 합니다. 데이터베이스 설계 관행에서 기능 종속성 스키마는 일반적으로 간결함을 위해 기능 종속성이라고 합니다. 정의 끝. 기능적 종속성의 오른쪽, 즉 하위 스키마 Y가 관계의 전체 스키마와 일치하는 특수한 경우에 기능적 종속성 제약 조건은 기본 또는 후보 키 고유성 제약 조건이 됩니다. 진짜: 인보이스 r(S) = ∀ t1, 티2 ∈r(t1[케이] = t2 [케이] → t1(에스) = t2(S)), K ⊆ S; 기능적 종속성을 정의할 때 하위 체계 X 대신 키 K를 지정해야 하고 기능적 종속성의 오른쪽인 하위 체계 Y 대신 전체 관계 체계를 취해야 합니다. 즉, 실제로, 관계 키의 고유성에 대한 제한은 오른쪽이 관계 체계 전체에 걸쳐 기능적 종속성의 동일한 체계일 때 기능적 종속성 제한의 특별한 경우입니다. 다음은 기능적 의존성 이미지의 예입니다. {계좌번호} → {성, 이름, 가명}; {성적 번호, 과목} → {등급}; 2. 암스트롱의 추론 규칙 기본 관계가 벡터 정의 기능 종속성을 충족하는 경우 다양한 특수 추론 규칙의 도움으로 이 기본 관계가 확실히 충족할 다른 기능 종속성을 얻을 수 있습니다. 이러한 특수 규칙의 좋은 예는 암스트롱의 추론 규칙입니다. 그러나 암스트롱 추론 규칙 자체의 분석을 진행하기 전에 새로운 금속 언어 기호 "├"를 소개하겠습니다. 파생 가능성 메타 주장 기호. 이 기호는 규칙을 공식화할 때 두 구문 표현 사이에 쓰이며 오른쪽의 공식이 왼쪽의 공식에서 파생되었음을 나타냅니다. 이제 암스트롱 추론 규칙 자체를 다음 정리의 형태로 공식화해 보겠습니다. 정리. 암스트롱의 추론 규칙이라고 하는 다음 규칙이 유효합니다. 추론 규칙 1. ├ X → X; 추론 규칙 2. X → Y├ X ∪ Z → Y; 추론 규칙 3. X → Y, Y ∪ W → Z ├ X ∪ W → Z; 여기서 X, Y, Z, W는 관계 S 스키마의 임의의 하위 스키마입니다. 파생 가능성 메타 진술 기호는 전제 목록과 주장 목록(결론)을 구분합니다. 1. 첫 번째 추론 규칙은 "반사성" 및 다음과 같이 읽습니다. "규칙이 추론됩니다." X는 기능적으로 X "를 수반합니다. 이것은 암스트롱의 유도 규칙 중 가장 단순한 것입니다. 이것은 말 그대로 희박한 공기에서 파생됩니다. 왼쪽 부분과 오른쪽 부분이 모두 있는 기능적 종속성을 반사적인. 반사성 규칙에 따라 반사적 의존의 제약이 자동으로 수행됩니다. 2. 두 번째 추론 규칙은 "채움" 그리고 다음과 같이 읽습니다. "X가 기능적으로 Y를 결정하는 경우 규칙이 파생됩니다. "서브 회로 X와 Z의 결합은 기능적으로 Y를 수반합니다."" 완성 규칙을 사용하면 기능 종속성 제약 조건의 왼쪽을 확장할 수 있습니다. 3. 세 번째 추론 규칙은 "유사 전이성" 하위 회로 X가 기능적으로 하위 회로 Y를 포함하고 하위 회로 Y와 W의 결합이 기능적으로 Z를 수반하는 경우 규칙은 파생됩니다. "서브 회로 X와 W의 결합이 하위 회로 Z를 기능적으로 결정합니다."" 의사 전이 규칙은 특수한 경우 W: = 0에 해당하는 전이 규칙을 일반화합니다. 이 규칙을 공식적으로 표기해 보겠습니다. X→Y, Y→Z ├X→Z. 앞서 주어진 전제와 결론은 기능적 의존도 체계의 지정에 의해 축약된 형태로 제시되었다는 점에 유의해야 한다. 확장된 형식에서는 다음과 같은 기능적 종속성 제약 조건에 해당합니다. 추론 규칙 1. inv r(S); 추론 규칙 2. inv r(S) ⇒ 인브 r(S); 추론 규칙 3. inv r(S)&INV r(S) ⇒ 인브 r(S); 실행하자 증거 이러한 추론 규칙. 1. 규칙의 증거 반사성 하위 체계 X가 하위 회로 Y로 대체될 때 기능 종속성 제약의 정의에서 직접 따릅니다. 실제로 기능적 종속성 제약 조건을 취하십시오. 인보이스 r(S)에 Y 대신 X를 대입하면 다음을 얻습니다. 인보이스 r(S), 이것은 반사성 규칙입니다. 반사 법칙이 증명됩니다. 2. 규칙의 증거 채움 기능적 의존성의 다이어그램에 대해 설명하겠습니다. 첫 번째 다이어그램은 패키지 다이어그램입니다. 전제: X → Y
두 번째 다이어그램: 결론: X ∪ Z → Y
튜플이 X ∪ Z에서 동일하다고 가정합니다. 그러면 X에서 동일합니다. 전제에 따르면 Y에서도 동일할 것입니다. 보충 규칙이 입증되었습니다. 3. 규칙의 증거 유사 전이성 우리는 또한 이 특정한 경우에 XNUMX이 될 다이어그램에 대해 설명할 것입니다. 첫 번째 다이어그램은 첫 번째 전제입니다. 전제 1: X → Y
전제 2: Y ∪ W → Z
마지막으로 세 번째 다이어그램은 결론 다이어그램입니다. 결론: X ∪ W → Z
튜플이 X ∪ W에서 동일하다고 가정합니다. 그러면 X와 W 모두에서 동일합니다. 전제 1에 따르면 Y에서도 동일하므로 전제 2에 따르면 Z에서도 동일합니다. 유사 전이 법칙이 증명됩니다. 모든 규칙이 입증되었습니다. 3. 유도 추론 규칙 필요한 경우 기능적 의존성의 새로운 규칙을 도출할 수 있는 규칙의 또 다른 예는 파생된 추론 규칙. 이 규칙은 무엇이며 어떻게 얻습니까? 합법적인 논리적 방법으로 이미 존재하는 일부 규칙에서 다른 규칙을 추론하면 이러한 새로운 규칙, 즉 파생상품, 원래 규칙과 함께 사용할 수 있습니다. 이러한 매우 임의적인 규칙은 우리가 이전에 겪었던 암스트롱의 추론 규칙에서 정확히 "파생적"이라는 점에 유의해야 합니다. 다음 정리의 형태로 기능적 종속성을 유도하기 위한 유도 규칙을 공식화하자. 정리. 다음 규칙은 암스트롱의 추론 규칙에서 파생됩니다. 추론 규칙 1. ├ X ∪ Z → X; 추론 규칙 2. X → Y, X → Z ├ X ∪ Y → Z; 추론 규칙 3. X → Y ∪ Z ├ X → Y, X → Z; 여기서 X, Y, Z, W는 이전의 경우와 같이 관계 S 체계의 임의의 하위 체계입니다. 1. 첫 번째 파생 규칙은 사소한 규칙 그리고 다음과 같이 읽습니다. "규칙은 파생됩니다: '서로 X와 Z의 결합은 기능적으로 X를 수반합니다'". 왼쪽이 오른쪽의 부분집합인 기능적 종속성을 호출합니다. 하찮은. 사소한 규칙에 따르면 사소한 종속성 제약 조건이 자동으로 적용됩니다. 흥미롭게도 사소한 규칙은 반사 규칙의 일반화이며 후자와 마찬가지로 기능적 종속성 제약 조건의 정의에서 직접 파생될 수 있습니다. 이 규칙이 파생되었다는 사실은 우연이 아니며 암스트롱의 규칙 시스템의 완전성과 관련이 있습니다. 암스트롱의 규칙 시스템의 완성도에 대해서는 조금 후에 더 이야기하겠습니다. 2. 두 번째 파생 규칙은 가산법칙 다음과 같이 읽습니다: "서브 회로 X가 기능적으로 서브 회로 Y를 결정하고 X가 동시에 기능적으로 Z를 결정한다면, 다음 규칙이 이러한 규칙에서 추론됩니다: "X는 기능적으로 서브 회로 Y와 Z의 결합을 결정합니다"". 3. 세 번째 파생 규칙은 투영법칙 또는 규칙가산성 반전". 그것은 다음과 같이 읽습니다: "만약 하위 회로 X가 하위 회로 Y와 Z의 결합을 기능적으로 결정한다면, 다음 규칙이 이 규칙에서 추론됩니다: "X는 하위 회로 Y를 기능적으로 결정하고 동시에 X는 하위 회로를 기능적으로 결정합니다. Z" ", 즉, 실제로 이 파생 규칙은 역가산 규칙입니다. 왼쪽 부분이 동일한 기능적 종속성에 적용된 가산성 및 투영성의 규칙이 종속성의 오른쪽 부분을 결합하거나 반대로 분할할 수 있다는 것이 궁금합니다. 추론 체인을 구성할 때 모든 전제를 공식화한 후 결론에 오른쪽과의 기능적 종속성을 포함하기 위해 이행성의 규칙이 적용됩니다. 실행하자 증거 임의의 추론 규칙을 나열했습니다. 1. 규칙의 증거 사소한 일들. 이후의 모든 증명과 마찬가지로 단계별로 수행해 보겠습니다. 1) X → X(암스트롱의 추론의 반사성 규칙에서); 2) 더 나아가 X ∪ Z → X(암스트롱의 추론 완료 규칙을 먼저 적용한 다음 증명의 첫 번째 단계의 결과로 얻음). 사소함의 법칙이 증명되었습니다. 2. 우리는 규칙의 단계별 증명을 수행할 것입니다 가산성: 1) X → Y(이것은 전제 1); 2) X → Z(이것은 전제 2); 3) Y ∪ Z → Y ∪ Z(암스트롱의 추론의 반사성 규칙에서); 4) X ∪ Z → Y ∪ Z (암스트롱 추론의 의사 전이 규칙을 적용한 다음 증명의 첫 번째 및 세 번째 단계의 결과로 얻음) 5) X ∪ X → Y ∪ Z(암스트롱의 추론의 의사 전이 규칙을 적용하여 얻은 값으로 두 번째 및 네 번째 단계를 따릅니다.) 6) X → Y ∪ Z가 있습니다(다섯 번째 단계에서 이어짐). 가산법칙이 증명된다. 3. 그리고 마지막으로 규칙 증명을 구성하겠습니다. 투사성: 1) X → Y ∪ Z, X → Y ∪ Z(이것은 전제); 2) Y → Y, Z → Z(암스트롱의 추론의 반사성 규칙을 사용하여 파생됨); 3) Y ∪ z → y, Y ∪ z → Z(암스트롱의 추론 완성 규칙과 증명의 두 번째 단계에서 얻은 결과); 4) X → Y, X → Z(암스트롱 추론의 의사 전이 규칙을 적용한 다음 증명의 첫 번째 및 세 번째 단계의 결과로 얻음) 투영법칙이 증명된다. 모든 파생 추론 규칙이 입증되었습니다. 4. 암스트롱 규칙 시스템의 완성도 F(S)를 관계 체계 S에 대해 정의된 기능적 종속성의 주어진 집합이라고 하자. 로 나타내다 INV 이 기능적 종속성 세트에 의해 부과된 제약. 다음과 같이 작성해 보겠습니다. 인보이스 r(S) = ∀X → Y ∈F(S) [inv r(S)]. 따라서 기능 종속성에 의해 부과된 이 제한 집합은 다음과 같이 해독됩니다. 기능 종속성 집합 F(S)에 속하는 기능 종속성 시스템의 규칙 X → Y에 대해 기능 종속성 제한 inv r(S)는 관계 r(S)의 집합에 대해 정의됩니다. 어떤 관계 r(S)가 이 제약 조건을 만족하게 하십시오. 암스트롱의 추론 규칙을 집합 F(S)에 대해 정의된 기능적 종속성에 적용함으로써 우리가 이미 말하고 증명한 바와 같이 새로운 기능적 종속성을 얻을 수 있습니다. 그리고 암시적으로, 관계 F(S)는 암스트롱의 추론 규칙의 확장된 형태에서 볼 수 있듯이 이러한 기능적 종속성의 제한을 자동으로 충족합니다. 이러한 확장 추론 규칙의 일반적인 형식을 기억하십시오. 추론 규칙 1. inv < X → X > r(S); 추론 규칙 2. inv r(에스) ⇒ 인보이스<X ∪ Z → Y> r(S); 추론 규칙 3. inv r(S) & inv <Y ∪ 승 → Z> r(S) ⇒ 인보이스<X ∪ 승→Z>; 우리의 추론으로 돌아가서 암스트롱의 규칙을 사용하여 파생된 새로운 종속성을 집합 F(S)에 보충해 보겠습니다. 우리는 더 이상 새로운 기능적 종속성을 얻지 않을 때까지 이 보충 절차를 적용할 것입니다. 이 구성의 결과로 우리는 폐쇄 F(S)를 설정하고 표시 F+(S). 실제로, 그러한 이름은 매우 논리적입니다. 왜냐하면 우리는 긴 구성을 통해 자체적으로 기존 기능 종속성 세트를 "닫고" 기존 기능으로 인한 모든 새로운 기능 종속성을 추가(따라서 "+")하기 때문입니다. 이러한 모든 구성이 수행되는 관계 체계 자체가 유한하기 때문에 클로저를 구성하는 이 프로세스는 유한하다는 점에 유의해야 합니다. 클로저는 닫혀 있는 집합의 상위 집합이며(실제로 더 큽니다!) 다시 닫힐 때 어떤 식으로든 변경되지 않습니다. 방금 말한 것을 공식 형식으로 쓰면 다음을 얻습니다. 에프(에스) ⊆ 에프+(에), [F+(에스)]+= 에프+(에스); 또한 암스트롱의 추론 규칙과 폐쇄의 정의에 대한 입증된 진실(즉, 합법성, 합법성)으로부터 주어진 기능적 종속성 세트의 제약 조건을 충족하는 모든 관계는 폐쇄에 속하는 종속성의 제약 조건을 충족할 것이라는 결론이 나옵니다. . X → Y ∈ F+(S) ⇒ ∀r(S) [inv r(S) ⇒ 인보이스 r(S)]; 따라서 추론 규칙 시스템에 대한 암스트롱의 완전성 정리는 외부 함축이 상당히 합법적이고 정당하게 등가로 대체될 수 있다고 말합니다. (우리는 이 정리의 증명을 고려하지 않을 것입니다. 왜냐하면 우리의 특정 강의 과정에서는 증명 과정 자체가 그렇게 중요하지 않기 때문입니다.) 강의 번호 10. 일반 형식 1. 데이터베이스 스키마 정규화의 의미 이 섹션에서 고려할 개념은 기능적 종속성 개념과 관련이 있습니다. 즉, 데이터베이스 스키마 정규화의 의미는 기능적 종속성 시스템에 의해 부과되는 제한 개념과 떼려야 뗄 수 없는 관계이며 이 개념에서 대부분 따릅니다. 모든 데이터베이스 디자인의 시작점은 도메인을 하나 이상의 관계로 나타내는 것이며 각 디자인 단계에서 "향상된" 속성이 있는 관계 스키마 집합이 생성됩니다. 따라서 설계 과정은 관계 패턴을 정규화하는 과정이며, 각각의 연속적인 정규 형식은 이전 형식보다 어떤 의미에서는 더 나은 속성을 가집니다. 각 정규형에는 일정한 제약 조건이 있으며 관계는 자체 제약 집합을 만족하는 경우 특정 정규 형식에 있습니다. 예는 첫 번째 정규 형식의 제한입니다. 관계의 모든 속성 값은 원자적입니다. 관계형 데이터베이스 이론에서 일반적으로 다음과 같은 정규 형식 시퀀스가 구별됩니다. 1) 첫 번째 정규형(1NF); 2) 제2정규형(XNUMXNF); 3) 제3정규형(XNUMXNF); 4) Boyce-Codd 정규형(BCNF); 5) 제4정규형(XNUMXNF); 6) 다섯 번째 정규형 또는 투영 결합 정규형(5 NF 또는 PJ/NF). (본 강의에서는 기본 관계의 처음 XNUMX개 정규형에 대한 자세한 논의가 포함되어 있으므로 XNUMX차 및 XNUMX차 정규형에 대한 자세한 내용은 다루지 않겠습니다.) 일반 형태의 주요 속성은 다음과 같습니다. 1) 다음의 각각의 정규형은 이전의 정규형보다 어떤 의미에서는 더 낫다. 2) 다음 정규형으로 전달할 때 이전 정규형의 속성이 유지됩니다. 설계 프로세스는 정규화 방법, 즉 이전 정규 형식의 관계를 다음 정규 형식의 요구 사항을 충족하는 둘 이상의 관계로 분해하는 방법을 기반으로 합니다. 우리가 자료를 통해 갈 때). 또는 다른 기본적인 관계). 기본 관계 생성에 대한 섹션에서 언급했듯이, 주어진 기능적 종속성 세트는 기본 관계의 스키마에 적절한 제한을 부과합니다. 이러한 제한은 일반적으로 두 가지 방식으로 구현됩니다. 1) 선언적으로, 즉 기본 관계에서 다양한 유형의 기본, 후보 및 외래 키를 선언함으로써(가장 널리 사용되는 방법) 2) 절차적으로, 즉 프로그램 코드 작성(위에서 언급한 소위 트리거 사용). 간단한 논리의 도움으로 데이터베이스 스키마를 정규화하는 요점이 무엇인지 이해할 수 있습니다. 데이터베이스를 정규화하거나 데이터베이스를 일반 형식으로 가져오는 것은 프로그램 코드 작성 필요성을 최소화하고 데이터베이스 성능을 높이며 상태 및 참조 무결성에 의한 데이터 무결성 유지를 용이하게 하기 위해 이러한 기본 관계 체계를 정의하는 것을 의미합니다. 즉, 개발자와 사용자가 가능한 한 간단하고 편리하게 코드를 만들고 작업하는 것입니다. 비정규화 데이터베이스와 정규화 데이터베이스의 동작을 비교하여 시각적으로 보여주기 위해 다음 예를 살펴보자. 시험 세션의 결과에 대한 정보가 포함된 기본 관계를 가정해 보겠습니다. 우리는 이미 그러한 데이터베이스를 전에 고려했습니다. 따라서, 옵션 1 데이터베이스 스키마. 세션(레코드 북 번호, 성명, 제목, 등급) 이 관계에서는 기본 관계 스키마 이미지에서 볼 수 있듯이 복합 기본 키가 정의됩니다. 기본 키(교과서 번호, 주제); 또한 이와 관련하여 기능적 종속성 시스템이 설정됩니다. {계좌번호} → {성, 이름, 가명}; 다음은 이 관계 체계를 사용하는 데이터베이스의 작은 조각에 대한 표 형식의 보기입니다. 우리는 이미 기능적 종속성의 한계를 고려하는 데 이 단편을 사용했으므로 예제를 사용하여 이 주제를 이해하는 것이 매우 쉬울 것입니다.
여기서, 상태별 데이터의 무결성을 유지하기 위해, 즉 성을 변경할 때 {classbook number} → {Last name, First name, Patronymic} 기능 종속 시스템의 제한을 충족하기 위해 이 기본 관계의 모든 튜플을 살펴보고 필요한 변경 사항을 순차적으로 입력하는 데 필요합니다. 그러나 이것은 다소 번거롭고 시간이 많이 소요되는 프로세스이므로(특히 대규모 교육 기관의 데이터베이스를 다루는 경우) 데이터베이스 관리 시스템 개발자는 이 프로세스를 자동화해야 한다는 결론에 도달했습니다. , 자동으로 만들어졌습니다. 이제 이(및 기타) 기능적 종속성의 이행에 대한 제어는 기본 관계에서 다양한 키의 올바른 선언과 이것의 소위 분해(즉, 무언가를 여러 독립 부분으로 나누는 것)를 사용하여 자동으로 구성될 수 있습니다. 관계. 따라서 기존 "세션" 관계 스키마를 지정된 교육 기관의 학생에 대한 정보만 포함하는 "학생" 스키마와 마지막 지난 세션에 대한 정보를 포함하는 "세션" 스키마의 두 가지 스키마로 나누어 보겠습니다. 그런 다음 필요한 정보를 쉽게 얻을 수 있는 방식으로 키를 선언합니다. 키가 있는 이러한 새로운 관계 체계가 어떻게 생겼는지 보여 드리겠습니다. 옵션 2 데이터베이스 스키마. 학생(레코드 북 번호, 성명), 기본 키(성적부 번호). 세션(음반번호, 제목, 등급), 기본 키(성적 번호, 제목), 외래 키(성적 번호)는 학생(성적 번호)을 참조합니다. 우리는 지금 무엇을 가지고 있습니까? "학생"과 관련하여 기본 키 "성적부 번호"는 기능적으로 다른 세 가지 속성인 "성", "이름" 및 "재산"을 결정합니다. 그리고 "세션"과 관련하여 복합 기본 키 "성적부 번호, 주제"도 모호하지 않습니다. 즉, 문자 그대로 이 관계 체계의 마지막 속성인 "점수"를 기능적으로 정의합니다. 그리고 이 두 관계 사이의 연결이 설정되었습니다. "세션" 관계 "성적부 번호"의 외부 키를 통해 수행되며, 이는 "학생" 관계에서 동일한 이름의 속성을 참조하며, 요청 시, 필요한 모든 정보를 제공합니다. 이제 해당 데이터베이스 스키마를 지정하는 두 번째 옵션에 해당하는 테이블이 나타내는 관계가 어떻게 생겼는지 보여드리겠습니다.
따라서 기능 종속성에 의해 부과된 제한 측면에서 정규화의 목표는 기본 관계의 다양한 유형의 기본, 후보 및 외래 키 선언을 사용하여 모든 데이터베이스에 필요한 기능 종속성을 부과할 필요가 있다는 것을 알 수 있습니다. 2. 제1정규형(XNUMXNF) 데이터베이스 설계 및 데이터베이스 관리 체계 개발의 초기 단계에서는 단순하고 모호하지 않은 속성이 가장 생산적이고 합리적인 코드 단위로 사용되었습니다. 그런 다음 단일 값 및 다중 값 속성과 함께 단순 및 복합 속성과 함께 사용했습니다. 이러한 각 개념의 의미를 설명하겠습니다. 복합 속성는 단순한 속성과 달리 여러 개의 간단한 속성으로 구성된 속성입니다. 다중값 속성는 단일 값 속성과 달리 여러 값을 나타내는 속성입니다. 다음은 단순, 복합, 단일 값 및 다중 값 속성의 예입니다. 관계를 나타내는 다음 표를 고려하십시오.
여기서 "Phone" 속성은 단순하고 모호하지 않으며 "Address" 속성은 단순하지만 다중 값을 갖습니다. 이제 다른 속성을 가진 다른 테이블을 고려하십시오.
이 관계에서 표로 표시되는 "Phones" 속성은 단순하지만 다중 값을 가지며 "Addresses" 속성은 복합 및 다중 값을 모두 갖습니다. 일반적으로 단순 또는 복합 속성의 다양한 조합이 가능합니다. 다른 경우에 관계를 나타내는 테이블은 일반적으로 다음과 같을 수 있습니다.
기본 관계 체계를 정규화할 때 프로그래머는 1가지 가장 일반적인 정규형 유형 중 하나를 사용할 수 있습니다. 첫 번째 정규형(2NF), 두 번째 정규형(3NF), 세 번째 정규형(XNUMXNF) 또는 Boyce-Codd 정규형(NFBC) . 명확히 하기 위해: 약어 NF는 영어 구 Normal Form의 약어입니다. 공식적으로는 위의 것 외에도 다른 형태의 일반형이 있지만 위의 것이 가장 대중적인 것 중 하나입니다. 현재 데이터베이스 개발자는 코드 작성을 복잡하게 하지 않고 구조에 과부하가 걸리지 않으며 사용자를 혼란스럽게 하지 않기 위해 복합 및 다중 값 속성을 피하려고 합니다. 이러한 고려 사항에서 첫 번째 정규형의 정의는 논리적으로 따릅니다. 정의. 모든 기본 관계는 첫 번째 정규형 이 관계의 스키마가 단순하고 단일 값 속성만 포함하고 반드시 동일한 의미를 갖는 경우에만. 정규화 관계와 비정규화 관계의 차이점을 시각적으로 설명하려면 예를 고려하십시오. 다음과 같은 비정규화 관계가 있다고 하자. 따라서, 옵션 1 간단한 기본 키가 정의된 관계 체계: 직원 (직원 번호, 성, 이름, 가문, 직위 코드, 전화번호, 입학 또는 퇴학 날짜); 기본 키(인력 번호); 이 관계 체계에 어떤 오류가 있는지 나열하겠습니다. 1) "Surname First Name Patronymic" 속성은 합성, 즉 이질적인 요소로 구성됩니다. 2) "Phones" 속성은 다중값입니다. 즉, 해당 값은 값 집합입니다. 3) 속성 "수락 또는 해고 날짜"에는 명확한 의미가 없습니다. 즉, 후자의 경우 입력한 날짜가 명확하지 않습니다. 예를 들어 날짜의 의미를 보다 정확하게 정의하기 위해 추가 속성이 도입되면 이 속성의 값은 의미상 명확해 지지만 그럼에도 불구하고 각 직원에 대해 지정된 날짜 중 하나만 저장할 수 있습니다. 이 관계를 정상 형태로 가져오려면 어떻게 해야 합니까? 첫째, 이러한 복합 속성과 복합 의미를 가진 속성을 제외하기 위해 복합 속성을 단순 속성으로 분할해야 합니다. 그리고 두 번째로, 이 관계를 분해할 필요가 있습니다. 즉, 다중값 속성을 제외하기 위해 여러 개의 새로운 독립 관계로 분해할 필요가 있습니다. 따라서 위의 모든 사항을 고려하여 "Employees" 관계를 분해하여 첫 번째 정규형 또는 1NF로 축소한 후 기본 및 외래 키가 설정된 다음 관계의 시스템을 얻습니다. 따라서, 옵션 2 처지: 직원 (직원 번호, 성, 이름, 가문, 직위 코드, 입학 날짜, 해고 날짜); 기본 키(인력 번호); 전화(인원번호, 전화번호); 기본 키(인력 번호, 전화); 외래 키(인사 번호)는 직원(인사 번호)을 참조합니다. 그래서 우리는 무엇을 볼 수 있습니까? 복합 속성 "성 이름 Patronymic"은 더 이상 우리 관계에 없으며 대신 세 가지 단순 속성 "성", "이름" 및 "패트로니믹"이 있으므로 관계의 "비정상"에 대한 이러한 이유는 제외되었습니다. . 또한 의미가 불명확한 속성 "고용 또는 해고 날짜" 대신 이제 "입원 날짜" 및 "해고 날짜"라는 두 가지 속성이 있으며 각각 의미가 명확합니다. 따라서 우리의 "Employees"관계가 정상적인 형태가 아닌 두 번째 이유도 안전하게 제거됩니다. 그리고 마지막으로 "Employees" 관계가 정규화되지 않은 마지막 이유는 다중 값 속성 "Phones"가 있기 때문입니다. 이 속성을 제거하려면 전체 관계를 분해해야 했습니다. 이 분해의 결과 일반적으로 원래 관계인 "Employees"에서 "Phones" 속성이 제외되었지만 두 번째 관계인 "Phones"가 형성되었습니다. 여기에는 "Employee의 직원 번호"와 "Phone"이라는 두 가지 속성이 있습니다. ", 즉 모든 속성 - 다시 간단하게, 첫 번째 정규형에 속하는 조건이 충족됩니다. 이러한 속성 "Employee number" 및 "Phone"은 "Phones" 관계의 복합 기본 키를 형성하고, "Employee number" 속성은 차례로 "Employees"에서 동일한 이름의 속성을 참조하는 외래 키입니다. " 관계, 즉 " 관계에서" 기본 키 "인사 번호"의 속성은 "직원" 관계의 기본 키를 참조하는 외래 키이기도 합니다. 따라서 두 관계 사이에 링크가 제공됩니다. 이 링크를 사용하면 복합 속성을 사용하지 않고도 많은 노력과 시간을 들이지 않고도 직원의 직원 번호별로 전화의 전체 목록을 표시할 수 있습니다. 시스템과 관련하여 기능적 종속성이 있는 경우 위의 모든 변환 후에 정규화가 완료되지 않습니다. 그러나 이 특정 예에서는 기능적 종속성 제약 조건이 없으므로 이 관계의 추가 정규화가 필요하지 않습니다. 3. 제2정규형(XNUMXNF) 두 번째 정규형 또는 2NF에 의해 관계에 더 강력한 요구 사항이 부과됩니다. 이는 제XNUMX정규형 관계의 정의가 제XNUMX정규형과 대조적으로 기능적 종속성에 대한 제한 체계의 존재를 의미하기 때문이다. 정의. 기본 관계는 두 번째 정규형 주어진 기능적 종속성 세트에 대한 상대적인 것은 그것이 제XNUMX정규 형태이고 또한 키가 아닌 각 속성이 각 키에 완전히 기능적으로 종속되어 있는 경우에만 해당됩니다. 이 정의에서 키가 아닌 속성 관계의 기본 또는 후보 키에 포함되지 않은 모든 관계 속성입니다. 키에 대한 전체 기능 종속성은 해당 키의 어떤 부분에도 기능 종속성이 없음을 의미합니다. 따라서 이제 관계를 정규화할 때 관계가 첫 번째 정규 형식이 되기 위한 조건의 충족도 모니터링해야 합니다. 기능적 종속성의 제한. 단순 키(XNUMX차 및 후보)와의 관계는 확실히 제XNUMX정규 형식에 있음이 분명합니다. 실제로 이 경우 키에 별도의 부분이 없기 때문에 키의 일부에 의존하는 것은 불가능해 보입니다. 이제 이전 주제의 구절에서와 같이 비정규화 관계 체계와 정규화 과정 자체의 예를 고려하십시오. 따라서, 옵션 1 관계 체계: 청중(건물번호, 강당번호, 면적 sq. m, 군단의 군 사령관); 기본 키(말뭉치 번호, 대상 번호); 또한 다음과 같은 기능 종속 시스템이 정의됩니다. {군단의 번호} → {군단의 군 사령관의 번호}; 우리는 무엇을 보는가? 이 관계의 모든 단일 속성이 모호하지 않고 단순하기 때문에 이 관계 "청중"이 첫 번째 정규 형식을 유지하기 위한 모든 조건이 충족됩니다. 그러나 키가 아닌 각 요소는 기능적으로 키에 완전히 종속되어야 한다는 조건이 충족되지 않습니다. 왜요? 예, "군단 참모장 번호" 속성은 기능적으로 복합 키 "군단 번호, 청중 번호"에 의존하지 않고 이 키의 일부, 즉 속성에 의존하기 때문에 그렇습니다. "군단의 번호". 실제로, 결국 어떤 특정 지휘관이 할당되는지를 완전히 결정하는 것은 군단 번호이며, 차례로 군단 지휘관의 인원 수는 강당 번호에 의존할 수 없습니다. 따라서 정규화의 주요 작업은 키가 특히 "No. 이를 달성하려면 이전 단락에서와 같이 관계 분해를 다시 적용해야 합니다. 따라서 다음과 같은 관계 시스템은 옵션 2 "Audience" 관계는 원래 관계를 몇 가지 새로운 독립 관계로 분해하여 얻은 것입니다. 군단(선체 번호, 군단의 인사 사령관의 수); 기본 키(케이스 번호); 청중(건물번호, 강당번호, 면적 sq. 중); 기본 키(말뭉치 번호, 대상 번호); 외래 키(케이스 번호)는 케이스(케이스 번호)를 참조합니다. 우리는 지금 무엇을 보는가? "군단" 비키 속성과 관련하여 "군단 지휘관의 인원 번호"는 기본 키 "군단 번호"에 완전히 기능적으로 의존합니다. 여기서 두 번째 정규형의 관계를 찾는 조건이 완전히 충족됩니다. 이제 두 번째 관계인 "청중"에 대한 고려로 넘어가겠습니다. "Audience"와 관련하여 기본 키 속성 "Case #"은 "Case" 관계의 기본 키를 참조하는 외래 키이기도 합니다. 이와 관련하여 키가 아닌 속성 "Area sq. m"은 전체 복합 기본 키 "Building #, Auditorium #"에 완전히 종속되며 해당 부분에도 종속되지 않습니다. 따라서 원래 관계를 분해하여 두 번째 정규형 정의의 모든 조건이 완전히 충족된다는 결론에 도달했습니다. 이 예에서 모든 기능적 종속성 요구 사항은 기본 키(여기에는 후보 키 없음) 및 외래 키의 선언에 의해 부과됩니다. 따라서 더 이상의 정규화가 필요하지 않습니다. 4. 제3정규형(XNUMXNF) 다음으로 살펴볼 정규형은 제3정규형(또는 XNUMXNF)입니다. 첫 번째 정규형과 두 번째 정규형과 달리 세 번째 정규형은 관계와 함께 기능적 종속성 시스템의 할당을 의미합니다. 관계가 제XNUMX정규형으로 환원되기 위해 어떤 속성을 가져야 하는지 공식화합시다. 정의. 기본 관계는 제XNUMX정규형 주어진 기능적 종속성 세트와 관련하여 그것이 두 번째 정규 형식이고 키가 아닌 각 속성이 키에만 완전히 기능적으로 종속되는 경우에만. 따라서 제XNUMX정규형의 요구사항은 결합된 경우에도 제XNUMX정규형과 제XNUMX정규형의 요구사항보다 더 강력합니다. 사실, 제XNUMX정규형에서 키가 아닌 모든 속성은 키와 전체 키에 의존하며 키 외에는 아무 것도 의존하지 않습니다. 비정규화 관계를 제XNUMX정규형으로 가져오는 과정을 설명하겠습니다. 이렇게 하려면 제XNUMX정규형이 아닌 관계의 예를 고려하십시오. 따라서, 옵션 1 "직원"관계의 계획 : 직원 (직원 번호, 성, 이름, 가문, 직위 코드, 급여); 기본 키(인력 번호); 또한 이 "직원" 관계 위에 다음과 같은 기능적 종속성 시스템이 설정됩니다. {직위 코드} → {급여}; 실제로, 일반적으로 급여 금액, 즉 급여 금액은 직위, 따라서 해당 데이터베이스의 코드에 직접적으로 의존합니다. 이것이 이 관계 "Employees"가 제XNUMX정규 형식이 아닌 이유입니다. 왜냐하면 이 속성은 키 속성이 아니지만 키가 아닌 속성 "Salary"가 "Position code" 속성에 완전히 기능적으로 종속되어 있기 때문입니다. 흥미롭게도 모든 관계는 이 형식 이전의 두 형식, 즉 분해에 의해 정확히 동일한 방식으로 세 번째 정규 형식으로 축소됩니다. "Employees" 관계를 분해하여 다음과 같은 새로운 독립 관계 시스템을 얻습니다. 따라서, 옵션 2 "직원"관계의 계획 : 직위(포지션 코드, 샐러리); 기본 키(위치 코드); 직원 (직원 번호, 성, 이름, 가문, 직위 코드); 기본 키(위치 코드); 외래 키(위치 코드)는 위치(위치 코드)를 참조합니다. 이제 우리가 볼 수 있듯이 "Position"과 관련하여 키가 아닌 속성 "Salary"는 단순 기본 키 "Position code"와 이 키에만 기능적으로 완전히 종속됩니다. "Employees"와 관련하여 키가 아닌 속성 "Last Name", "First Name", "Patronymic" 및 "Position Code"는 모두 단순 기본 키 "Employment Number"에 완전히 기능적으로 종속됩니다. 이와 관련하여 "Position ID" 속성은 "Positions" 관계의 기본 키를 참조하는 외래 키입니다. 이 예에서 모든 요구 사항은 단순 기본 키와 외래 키를 선언하여 부과되므로 더 이상의 정규화가 필요하지 않습니다. 실제로는 일반적으로 데이터베이스를 제XNUMX정규형으로 만드는 데 자신을 제한한다는 사실을 아는 것은 흥미롭고 유용합니다. 동시에 동일한 관계의 다른 속성에 대한 주요 속성의 일부 기능적 종속성이 부과되지 않을 수 있습니다. 이러한 비표준 기능 종속성에 대한 지원은 앞서 언급한 트리거를 사용하여 구현됩니다(즉, 적절한 프로그램 코드를 작성하여 절차적으로). 또한 트리거는 이 관계의 튜플과 함께 작동해야 합니다. 5. 보이스-코드 정규형(NFBC) Boyce-Codd 정규형은 XNUMX차 정규형 바로 다음에 "복잡성"을 따릅니다. 따라서 Boyce-Codd 정규형은 때때로 단순히 강한 제XNUMX정규형 (또는 강화된 3NF). 그녀가 강화된 이유는 무엇입니까? Boyce-Codd 정규형의 정의를 공식화합니다. 정의. 기본 관계는 보이스 노멀 폼 - 코드 키가 아닌 속성이 모든 키에 완전히 기능적으로 종속될 뿐만 아니라 모든 키 속성이 모든 키에 완전히 기능적으로 종속되어야 하는 경우에만 제XNUMX정규 형식입니다. 따라서 키가 아닌 속성이 실제로 전체 키에 의존하고 키 외에는 아무 것도 의존하지 않는다는 요구 사항은 키 속성에도 적용됩니다. Boyce-Codd 정규 형식의 관계에서 관계 내의 모든 기능적 종속성은 키 선언에 의해 부과됩니다. 그러나 데이터베이스 관계를 Boyce-Codd 형식으로 축소할 때 다양한 관계의 속성 간의 종속성이 기능적 종속성을 부과하지 않는 것으로 판명되는 상황이 발생할 수 있습니다. 다른 관계의 튜플에서 작동하는 트리거로 이러한 기능적 종속성을 지원하는 것은 트리거가 단일 관계의 튜플에서 작동하는 제XNUMX정규형의 경우보다 더 어렵습니다. 무엇보다도 데이터베이스 관리 시스템을 설계하는 관행은 기본 관계를 Boyce-Codd 정규형으로 가져오는 것이 항상 가능한 것은 아님을 보여주었습니다. 언급된 예외 사항에 대한 이유는 두 번째 정규형과 세 번째 정규형의 요구 사항이 다른 가능한 키의 구성 요소인 속성의 기본 키에 대한 최소한의 기능 종속성을 요구하지 않았기 때문입니다. 이 문제는 역사적으로 Boyce-Codd 정규형이라고 하는 정규형에 의해 해결되며 가능한 키가 여러 개 있는 경우 세 번째 정규형을 개선한 것입니다. 일반적으로 데이터베이스 스키마 정규화는 데이터베이스 무결성을 유지하는 검사 및 백업의 수를 줄이기 때문에 데이터베이스 관리 시스템이 수행하는 데이터베이스 업데이트를 보다 효율적으로 만듭니다. 관계형 데이터베이스를 설계할 때 거의 항상 데이터베이스에 있는 모든 관계의 두 번째 정규 형식을 얻습니다. 자주 업데이트되는 데이터베이스에서는 일반적으로 관계의 세 번째 정규 형식을 제공하려고 합니다. Boyce-Codd 정규형은 실제로 관계에 여러 복합 중첩 후보 키가 있는 상황이 드물기 때문에 훨씬 덜 주의를 기울입니다. 위의 모든 사항으로 인해 Boyce-Codd 정규형은 프로그램 코드를 개발할 때 사용하기가 그리 편리하지 않습니다. 따라서 앞에서 언급한 것처럼 실제로 개발자는 일반적으로 데이터베이스를 제XNUMX의 정규형으로 가져오는 데 자신을 제한합니다. 그러나 그것은 또한 자체의 다소 흥미로운 기능을 가지고 있습니다. 요점은 관계가 XNUMX차 정규형이지만 Boyce-Codd 정규형이 아닌 상황은 실제로 매우 드물다는 것입니다. 즉, XNUMX차 정규형으로 축소한 후 일반적으로 모든 기능적 종속성은 기본, 후보 및 외래 키이므로 기능적 종속성을 지원하기 위한 트리거가 필요하지 않습니다. 그러나 기능적 종속성에 의해 연결되지 않은 무결성 제약 조건을 지원하기 위해 트리거가 필요합니다. 6. 정규형의 중첩 일반 형식의 중첩은 무엇을 의미합니까? 일반 형식의 중첩 - 이것은 서로 관련하여 약화 된 형태와 강화 된 형태의 개념의 비율입니다. 정규형의 중첩은 각각의 정의를 완전히 따릅니다. 우리에게 알려진 일반 형식의 중첩 관계를 보여주는 다이어그램을 상상해 봅시다.
구체적인 예를 들어 서로에 대해 약화된 정규형과 강화된 정규형의 개념을 설명하겠습니다. 첫 번째 정규형은 두 번째 정규형과 관련하여(그리고 다른 모든 정규형과도 관련하여) 약화됩니다. 실제로 우리가 겪은 모든 정규형의 정의를 회상하면 각 정규형의 요구 사항에 첫 번째 정규형에 속해야 하는 요구 사항이 포함되어 있음을 알 수 있습니다(결국 각 후속 정의에 포함됨). 제XNUMX정규형은 제XNUMX정규형보다 강하지만 제XNUMX정규형 및 Boyce-Codd 정규형보다 약합니다. 사실 제XNUMX정규형에 속하는 것은 제XNUMX정규형의 정의에 포함되며, 제XNUMX정규형 자체도 차례로 제XNUMX정규형을 포함한다. Boyce-Codd 정규형은 세 번째 정규형에 대해서뿐만 아니라 이전의 다른 모든 정규형에 대해서도 강화됩니다. 그리고 세 번째 정규형은 Boyce-Codd 정규형에 대해서만 약해집니다. 강의 11. 데이터베이스 스키마 설계 논리적 수준에서 설계할 때 데이터베이스 스키마를 추상화하는 가장 일반적인 방법은 소위 엔티티 관계 모델. 라고도 합니다. 응급실 모델, 여기서 ER은 영어 구 Entity - Relationship의 약어이며 문자 그대로 "Entity - Relationship"으로 번역됩니다. 이러한 모델의 요소는 엔티티 클래스, 속성 및 관계입니다. 우리는 이러한 각 요소에 대한 설명과 정의를 제공할 것입니다. 엔티티 클래스 객체 지향 프로그래밍의 의미에서 메서드가 없는 객체 클래스와 같습니다. 물리적 계층으로 이동할 때 엔터티 클래스는 특정 데이터베이스 관리 시스템에 대한 기본 관계형 데이터베이스 관계로 변환됩니다. 그들은 기본 관계 자체와 마찬가지로 고유한 속성을 가지고 있습니다. 방금 주어진 대상에 대해 보다 정확하고 엄밀한 정의를 내리도록 합시다. 수업 공통 속성, 작업, 관계 및 의미를 가진 개체 컬렉션의 명명된 설명이라고 합니다. 그래픽으로 클래스는 일반적으로 직사각형으로 표시됩니다. 각 클래스에는 다른 모든 클래스와 고유하게 구별되는 이름(텍스트 문자열)이 있어야 합니다. 클래스 속성 이 속성의 인스턴스가 취할 수 있는 값 집합을 설명하는 클래스의 명명된 속성입니다. 클래스는 여러 속성을 가질 수 있습니다(특히 속성이 없을 수 있음). 속성으로 표현되는 속성은 주어진 클래스의 모든 객체에 공통되는 모델링된 엔터티의 속성입니다. 따라서 속성은 객체의 상태를 추상화한 것입니다. 모든 클래스 개체의 모든 속성에는 값이 있어야 합니다. 소위 관계는 외래 키의 선언을 사용하여 구현됩니다(우리는 이미 유사한 현상을 이전에 만났습니다). 그리고 이를 통해 여러 개의 서로 다른 독립적인 기본 관계가 데이터베이스라는 단일 시스템으로 "연결"됩니다. 또한, 엔티티-관계 모델의 그래픽 기반을 형성하는 다이어그램은 통합 모델링 언어 UML을 사용하여 묘사됩니다. 많은 책들이 객체 지향 모델링 언어 UML(또는 통합 모델링 언어)에 할애되어 있으며, 그 중 많은 책이 러시아어로 번역되었습니다(일부는 러시아 작가가 저술함). 일반적으로 UML을 사용하면 순수 소프트웨어, 순수 하드웨어, 소프트웨어-하드웨어, 혼합, 명시적으로 인간 활동 포함 등 다양한 유형의 시스템을 모델링할 수 있습니다. 그러나 무엇보다도 우리가 이미 언급했듯이 UML 언어는 관계형 데이터베이스를 설계하는 데 적극적으로 사용됩니다. 이를 위해 언어(클래스 다이어그램)의 작은 부분이 사용되지만 전체는 아닙니다. 관계형 데이터베이스 설계 관점에서 모델링 기능은 ER 다이어그램의 기능과 크게 다르지 않습니다. 우리는 또한 관계형 데이터베이스 설계의 맥락에서 ER 다이어그램 사용에 기반한 구조적 설계 방법과 UML 언어 사용에 기반한 객체 지향 방법이 주로 용어에서만 다르다는 것을 보여주고 싶었습니다. ER 모델은 개념적으로 UML보다 간단하고 개념, 용어 및 응용 프로그램 옵션이 적습니다. 그리고 이것은 ER 모델의 다른 버전이 관계형 데이터베이스 설계를 지원하기 위해 특별히 개발되었으며 ER 모델에는 관계형 데이터베이스 디자이너의 실제 요구 사항을 넘어서는 기능이 거의 포함되어 있지 않기 때문에 이해할 수 있습니다. UML은 객체 세계에 속합니다. 이 세계는 관계형 세계보다 훨씬 더 복잡합니다. UML은 무엇이든 통합된 객체 지향 모델링에 사용할 수 있기 때문에 언어에는 관계형 데이터베이스 디자인 관점에서 중복되는 개념, 용어 및 사용 사례가 많이 포함되어 있습니다. 클래스 다이어그램의 일반적인 메커니즘에서 관계형 데이터베이스 설계에 실제로 필요한 것을 추출하면 표기법과 용어가 다른 정확히 ER 다이어그램을 얻을 수 있습니다. UML에서 클래스 이름을 구성할 때 문자, 숫자, 심지어 구두점까지 임의의 조합이 허용되는지 궁금합니다. 그러나 실제로는 대문자로 시작하는 짧고 의미 있는 형용사와 명사를 클래스 이름으로 사용하는 것이 좋습니다. (다이어그램의 개념은 다음 강의에서 더 자세히 다루겠습니다.) 1. 채권의 종류와 다양성 데이터베이스 스키마 설계에서 관계 간의 관계는 엔터티 클래스를 연결하는 선으로 표시됩니다. 더욱이, 연결의 각 끝은 이름(즉, 연결 유형)과 연결에서 클래스 역할의 다양성으로 특징지어질 수 있고 일반적으로 그래야 합니다. 다중성 및 연결 유형의 개념을 더 자세히 고려해 보겠습니다. 다수 (다중성)은 주어진 역할을 가진 엔티티 클래스의 속성이 어떤 종류의 관계의 각 인스턴스에 참여할 수 있거나 참여해야 하는지를 나타내는 특성입니다. 관계 역할의 카디널리티를 설정하는 가장 일반적인 방법은 특정 숫자나 범위를 직접 지정하는 것입니다. 예를 들어 "1"을 지정하면 주어진 역할을 가진 각 클래스가 이 연결의 일부 인스턴스에 참여해야 하며 이 역할을 가진 클래스의 정확히 하나의 개체가 연결의 각 인스턴스에 참여할 수 있음을 나타냅니다. "0..1" 범위를 지정하면 주어진 역할을 가진 클래스의 모든 개체가 이 관계의 인스턴스에 참여할 필요가 없지만 하나의 개체만 관계의 각 인스턴스에 참여할 수 있음을 나타냅니다. 다중성에 대해 더 자세히 이야기합시다. 데이터베이스 디자인 시스템에서 일반적이고 가장 일반적인 카디널리티는 다음과 같습니다. 1) 1 - 해당 끝에서 연결의 다중도는 XNUMX과 같습니다. 2) 0... 1 - 이 표기법은 해당 끝에서 주어진 연결의 다중성이 XNUMX을 초과할 수 없음을 의미합니다. 3) 0... - 이 다중성은 단순히 "다"로 해독됩니다. 일반적으로 "많다"는 "아무것도"를 의미하지 않는다는 것이 궁금합니다. 4) 1... - 이 지정은 "하나 이상"의 다중성에 부여되었습니다. 다양한 링크가 있는 작업을 설명하기 위해 간단한 다이어그램의 예를 들어 보겠습니다.
이 다이어그램에 따르면 각 매표소에는 많은 티켓이 있으며 각 티켓은 하나의(그리고 그 이상은 아닌) 매표소에 있음을 쉽게 이해할 수 있습니다. 이제 링크의 가장 일반적인 유형이나 이름을 고려하십시오. 다음과 같이 나열해 보겠습니다. 1) 1:1 - 이 지정은 연결 "일대일", 즉, 두 세트의 일대일 대응입니다. 2) 1 : 0... - 이것은 "와 같은 연결에 대한 지정입니다.일대다". 간결하게 이러한 관계를 "1:M"이라고 합니다. 앞서 살펴본 다이어그램에서 볼 수 있듯이 바로 이러한 이름과의 관계가 있습니다. 3) 0... : 1 - 이는 이전 연결의 역전이거나 " 유형의 연결입니다.하나에 많은"; 4) 0... : 0... XNUMX은 "와 같은 연결에 대한 지정입니다.많은", 즉 링크의 각 끝에 많은 속성이 있습니다. 5) 0... 1 : 0... 1 - 이는 이전에 소개된 "일대일" 유형 연결과 유사한 연결이며, 이를 ""라고 합니다.하나 이상 하나 이상"; 6) 0... 1 : 0... - 이는 일대다 연결과 유사한 연결이며 "일대다 이하"라고 합니다. 7) 0... : 0... 1 - 이는 다대일 유형 연결과 유사한 연결이며 "다수에서 한 명 이하". 보시다시피, 마지막 세 연결은 "하나"의 다중도를 "하나 이하"의 다중도로 대체하여 강의에서 숫자 XNUMX, XNUMX, XNUMX으로 나열된 연결에서 얻은 것입니다. 2. 도표. 차트 유형 이제 마지막으로 다이어그램과 해당 유형에 대한 고려로 직접 진행해 보겠습니다. 일반적으로 논리적 모델에는 세 가지 수준이 있습니다. 이러한 수준은 데이터 구조에 대한 정보의 표현 깊이가 다릅니다. 이러한 수준은 다음 다이어그램에 해당합니다. 1) 프레젠테이션 다이어그램; 2) 키 다이어그램; 3) 완전한 속성 다이어그램. 이러한 유형의 다이어그램을 각각 분석하고 데이터 구조에 대한 정보 표현의 깊이에서 차이점의 의미를 자세히 설명하겠습니다. 1. 프리젠테이션 다이어그램. 이러한 다이어그램은 엔터티의 가장 기본적인 클래스와 해당 관계만 설명합니다. 이러한 다이어그램의 키는 전혀 설명되지 않을 수 있으므로 연결이 어떤 식으로든 개별화되지 않을 수 있습니다. 따라서 다대다 관계는 일반적으로 피하거나 존재하는 경우 미세 조정되지만 허용됩니다. 복합 및 다중 값 속성도 완벽하게 유효하지만 이러한 속성과의 기본 관계는 정상적인 형태로 축소되지 않는다고 이전에 썼습니다. 흥미롭게도 우리가 고려한 세 가지 유형의 다이어그램 중 마지막 유형(전체 속성 다이어그램)만이 여기에 제공된 데이터가 정상적인 형식이라고 가정합니다. 프리젠테이션 다이어그램이 이미 고려되었고 다음 줄에 있는 키 다이어그램은 그러한 종류를 의미하지 않습니다. 이러한 다이어그램은 일반적으로 프리젠테이션에 사용됩니다(따라서 이름 - 프리젠테이션, 즉 과도한 세부 사항이 필요하지 않은 프리젠테이션, 데모에 사용됨). 때때로 데이터베이스를 설계할 때 이 특정 데이터베이스가 정보를 다루는 주제 영역의 전문가와 상의할 필요가 있습니다. 그런 다음 프리젠 테이션 다이어그램도 사용됩니다. 프로그래밍과 거리가 먼 직업의 전문가로부터 필요한 정보를 얻기 위해 특정 세부 사항에 대한 과도한 설명이 전혀 필요하지 않기 때문입니다. 2. 주요 다이어그램. 프리젠테이션 다이어그램과 달리 키 다이어그램은 반드시 기본 키의 관점에서 엔티티의 모든 클래스와 이들의 관계를 설명합니다. 여기에서 다대다 관계는 이미 필연적으로 상세합니다(즉, 순수한 형태의 이 유형의 관계는 단순히 여기에서 지정할 수 없습니다). 다중값 속성은 여전히 프리젠테이션 다이어그램에서와 같은 방식으로 허용되지만 키 다이어그램에 존재하는 경우 일반적으로 독립 엔티티 클래스로 변환됩니다. 그러나 이상하게도 모호하지 않은 속성은 여전히 불완전하게 표현되거나 복합적인 것으로 설명될 수 있습니다. 프리젠테이션 및 키 다이어그램과 같은 다이어그램에서 여전히 유효한 이러한 "자유"는 기본 관계가 정규화되지 않았음을 결정하기 때문에 다음 유형의 다이어그램에서 허용되지 않습니다. 따라서 우리는 미래의 키 다이어그램이 이미 설명된 엔티티 클래스에 대해 "매달린" 속성만 가정한다고 결론을 내릴 수 있습니다. 즉, 프레젠테이션 다이어그램을 사용하여 가장 필요한 엔티티 클래스를 설명하는 것으로 충분하고 키 다이어그램을 사용하여 모든 것을 추가 필요한 속성을 지정하고 가장 중요한 모든 링크를 지정합니다. 3. 전체 속성 다이어그램. 전체 속성 다이어그램은 위의 모든 엔터티 클래스, 해당 속성 및 이러한 엔터티 클래스 간의 관계를 가장 자세히 설명합니다. 일반적으로 이러한 차트는 제XNUMX정규 형식의 데이터를 나타내므로 이러한 차트에서 설명하는 기본 관계에서 비세분화된 다대다 속성이 없는 것처럼 복합 또는 다중값 속성이 허용되지 않는 것은 당연합니다. 많은 관계. 그러나 완전한 속성 차트에는 데이터 표시 측면에서 가장 완전한 차트라고 부를 수 없다는 단점이 있습니다. 예를 들어, 전체 속성 다이어그램을 사용할 때 특정 데이터베이스 관리 시스템의 특성은 여전히 고려되지 않고 특히 데이터 유형은 필요한 논리적 모델링 수준에 필요한 정도로만 지정됩니다. 3. 연결 및 키 마이그레이션 조금 전에 데이터베이스에서 관계가 무엇인지에 대해 이미 이야기했습니다. 특히 관계의 외래 키를 선언할 때 관계가 설정되었습니다. 그러나 우리 과정의이 섹션에서는 더 이상 기본 관계에 대해 이야기하지 않고 엔티티의 금전 등록기에 대해 이야기합니다. 이런 의미에서 관계를 설정하는 과정은 여전히 다양한 키의 선언과 연관되어 있지만 지금은 엔터티 클래스의 키에 대해 이야기하고 있습니다. 즉, 관계를 설정하는 프로세스는 한 엔터티 클래스의 단순 또는 복합 기본 키를 다른 클래스로 전송하는 것과 관련됩니다. 그러한 이전 과정을 키 마이그레이션. 이 경우 기본 키가 전송되는 엔터티 클래스를 호출합니다. 부모 클래스, 그리고 외래 키가 마이그레이션되는 엔터티의 클래스를 호출합니다. 자식 클래스 엔터티. 자식 엔터티 클래스에서 키 속성은 외래 키 속성의 상태를 받으며 자신의 기본 키 형성에 참여할 수도 있고 참여하지 않을 수도 있습니다. 따라서 기본 키가 부모에서 자식 엔터티 클래스로 마이그레이션되면 부모 클래스의 기본 키를 참조하는 외래 키가 자식 클래스에 나타납니다. 키 마이그레이션의 공식적 표현의 편의를 위해 다음 키 마커를 소개합니다. 1) PK - 이것이 기본 키(기본 키)의 속성을 표시하는 방법입니다. 2) FK - 이 마커를 사용하여 외래 키(외래 키)의 속성을 나타냅니다. 3) PFK - 이러한 마커를 사용하여 기본/외래 키의 속성, 즉 일부 엔터티 클래스의 유일한 기본 키의 일부인 동시에 동일한 엔터티 클래스의 일부 외래 키의 일부인 속성을 나타냅니다. . 따라서 PK 및 FK 마커가 있는 엔터티 클래스의 속성은 이 클래스의 기본 키를 형성합니다. FK 마커가 있는 속성 및 PFK는 이 엔터티 클래스의 일부 외래 키의 일부입니다. 일반적으로 키는 다른 방식으로 마이그레이션될 수 있으며 각각의 경우에 일종의 연결이 발생합니다. 그렇다면 키 마이그레이션 방식에 따라 어떤 유형의 링크가 있는지 살펴보겠습니다. 전체적으로 두 가지 주요 마이그레이션 계획이 있습니다. 1. 마이그레이션 계획 ∀박(박 |→PF케이); 이 항목에서 "|→" 기호는 "이전"의 개념을 의미합니다. 즉, 위의 공식은 다음과 같이 읽습니다. 상위 엔터티 클래스의 기본 키 PK의 모든 (각각) 속성은 기본 키 PF물론 이 클래스의 외래 키이기도 한 K 자식 엔터티 클래스입니다. 이 경우 부모 엔터티 클래스의 모든 키 속성은 예외 없이 자식 엔터티 클래스로 마이그레이션되어야 한다는 사실에 대해 이야기하고 있습니다. 이러한 유형의 연결을 식별, 부모 엔터티 클래스의 키는 자식 엔터티 식별에 전적으로 관련되어 있기 때문입니다. 식별 유형의 링크 중에서 차례로 두 가지 가능한 독립 유형의 링크가 있습니다. 따라서 두 가지 유형의 식별 링크가 있습니다. 1) 완전히 식별. 식별 관계는 상위 엔티티 클래스의 마이그레이션 기본 키 속성이 하위 엔티티 클래스의 기본(및 외래) 키를 완전히 형성하는 경우에만 완전히 식별한다고 합니다. 완전 식별 관계는 때때로 범주형, 완전히 식별되는 관계는 모든 범주에서 하위 엔터티를 식별하기 때문입니다. 2) 완전히 식별되지 않음. 식별 관계는 부모 엔터티 클래스의 마이그레이션 기본 키 속성이 자식 엔터티 클래스의 기본(동시에 외래) 키를 부분적으로만 형성하는 경우에만 불완전 식별이라고 합니다. 따라서 마커가 있는 키 외에도 PFK에는 PK로 표시된 키도 있습니다. 이 경우 자식 엔터티 클래스의 외래 키 PFK는 부모 엔터티 클래스의 기본 키 PK에 의해 완전히 결정되지만 단순히 이 자식 관계의 기본 키 PK는 부모 엔터티 클래스의 기본 키 PK에 의해 결정되지 않습니다. 엔터티 클래스는 그 자체로 존재합니다. 2. 이주 계획 ∃박(박 |→ FK); 이러한 마이그레이션 체계는 다음과 같이 읽어야 합니다. 마이그레이션 중에 자식 엔터티 클래스의 키가 아닌 필수 속성으로 전송되는 부모 엔터티 클래스의 기본 키 속성이 있습니다. 따라서 이 경우 이전 사례에서와 같이 전부가 아닌 일부가 상위 엔티티 클래스의 기본 키 속성이 하위 엔티티 클래스로 전송된다는 사실에 대해 이야기하고 있습니다. 또한 이전 마이그레이션 방식이 자식 관계의 기본 키로 마이그레이션을 정의한 경우 동시에 외래 키가 된 경우 마지막 마이그레이션 유형은 부모 엔터티 클래스의 기본 키 속성이 일반 키로 마이그레이션되는 것으로 결정합니다. , 처음에는 키가 아닌 속성이며 이후 외래 키 상태를 얻습니다. 이러한 유형의 연결을 호출합니다. 비식별, 실제로 부모 키는 자식 엔터티의 형성에 전적으로 관여하지 않기 때문에 단순히 자식 엔터티를 식별하지 않습니다. 비식별 관계 중에서 두 가지 가능한 유형의 관계도 구별됩니다. 따라서 비식별 관계에는 다음 두 가지 유형이 있습니다. 1) 반드시 식별이 불가능한. 비식별 관계는 하위 엔터티 클래스의 모든 마이그레이션 키 속성에 대한 Null 값이 금지되는 경우에만 반드시 비식별 관계라고 합니다. 2) 선택적으로 비식별. 비식별 관계는 하위 엔터티 클래스의 일부 마이그레이션 키 속성에 대해 null 값이 허용되는 경우에만 반드시 비식별이 아니라고 합니다. 제시된 자료를 체계화하고 이해하는 작업을 용이하게 하기 위해 위의 모든 내용을 다음 표의 형식으로 요약합니다. 또한 이 표에는 어떤 유형의 관계("일대일 이하", "다대일", "다대일 이하")가 어떤 유형의 관계(완전히 식별하는 것이 아니라 완전히 식별하는가)에 해당하는지에 대한 정보가 포함됩니다. 식별, 반드시 식별하지 않음, 반드시 비식별하지 않음). 따라서 부모 엔터티 클래스와 자식 엔터티 클래스 간에는 관계 유형에 따라 다음과 같은 유형의 관계가 설정됩니다.
따라서 마지막 경우를 제외한 모든 경우에 참조가 비어 있지 않음(null이 아님) → 1임을 알 수 있습니다. 마지막 연결을 제외한 모든 경우에 연결의 상위 끝에서 다중성이 "XNUMX"로 설정되는 경향에 유의하십시오. 이것은 이러한 관계의 경우 외래 키의 값(즉, 완전히 식별하는 관계, 완전히 식별하지 않는 관계, 반드시 식별할 수 없는 관계 유형)의 기본 키 값과 반드시 일치해야 하기 때문입니다. 상위 엔티티 클래스. 그리고 후자의 경우 외래 키의 값이 Null 값(FK: null 유효성 플래그)과 같을 수 있기 때문에 다중성은 키의 상위 끝에서 "XNUMX개 이하"로 설정됩니다. 관계. 우리는 분석을 더 수행합니다. 연결의 하위 끝에서 첫 번째를 제외한 모든 경우에 다중성은 "다"로 설정됩니다. 이는 두 번째 경우와 같이 불완전한 식별로 인해(또는 두 번째 및 세 번째 경우에는 그러한 식별이 전혀 없는 경우) 상위 엔터티 클래스의 기본 키 값이 값 중에서 반복적으로 발생할 수 있기 때문입니다. 자식 클래스의 외래 키. 그리고 첫 번째 경우에는 관계가 완전히 식별되므로 부모 엔터티 클래스의 기본 키 속성은 자식 엔터티 클래스 키의 속성 중 한 번만 발생할 수 있습니다. 강의 12. 엔티티 클래스의 관계 따라서 우리가 살펴본 모든 개념, 즉 다이어그램과 그 유형, 다중성 및 관계 유형, 키 마이그레이션 유형은 이제 동일한 관계에 대한 자료를 살펴보는 데 도움이 될 것입니다. 엔터티. 그 중에는 앞으로 보게 되겠지만 다양한 종류의 연결도 있습니다. 1. 계층적 재귀 관계 우리가 고려할 엔티티 클래스 간의 첫 번째 유형의 관계는 소위 계층적 재귀 관계. 대개 재귀 (또는 재귀 링크)는 엔터티 클래스와 자체의 관계입니다. 때로는 생활 상황과 유사하게 이러한 연결을 "낚시 고리"라고도합니다. 계층적 재귀 관계 (또는 간단히 계층적 재귀)는 "최대 일대다" 유형의 재귀 관계입니다. 계층적 재귀는 데이터를 트리 구조에 저장하는 데 가장 일반적으로 사용됩니다. 계층적 재귀 관계를 지정할 때 부모 엔터티 클래스의 기본 키(이 특별한 경우 자식 엔터티 클래스 역할도 함)는 동일한 엔터티 클래스의 키가 아닌 필수 특성에 대한 외래 키로 마이그레이션되어야 합니다. 이 모든 것은 "계층적 재귀"라는 개념 자체의 논리적 무결성을 유지하는 데 필요합니다. 따라서 위의 모든 사항을 고려하면 계층적 재귀 관계는 반드시 비식별은 아님 다른 종류의 관계가 사용되면 외래 키에 대한 Null 값이 유효하지 않고 재귀가 무한하기 때문입니다. 속성이 동일한 이름으로 동일한 엔터티 클래스에 두 번 나타날 수 없음을 기억하는 것도 중요합니다. 따라서 마이그레이션된 키의 속성에는 소위 역할 이름이 지정되어야 합니다. 따라서 계층적 재귀 관계에서 노드의 속성은 직계 조상인 노드의 기본 키에 대한 선택적 참조인 외래 키로 확장됩니다. 관계형 데이터 모델에서 계층적 재귀를 구현하는 프리젠테이션 및 키 다이어그램을 작성하고 표 형식의 예를 들어 보겠습니다. 먼저 프레젠테이션 다이어그램을 만들어 보겠습니다.
이제 더 자세한 키 다이어그램을 작성해 보겠습니다.
계층적 재귀 관계와 같은 유형의 관계를 명확하게 설명하는 예를 고려하십시오. 이전 예제와 같이 "Ancestor Code" 및 "Node Code" 특성으로 구성된 다음 엔터티 클래스가 주어집니다. 먼저 이 엔터티 클래스의 표 형식 표현을 보여 드리겠습니다.
이제 이 엔터티 클래스를 나타내는 다이어그램을 작성해 보겠습니다. 이를 위해 테이블에서 이에 필요한 모든 정보를 선택합니다. 코드 "one"이 있는 노드의 조상이 존재하지 않거나 정의되지 않았습니다. 이로부터 노드 "one"이 정점이라는 결론을 내립니다. 동일한 노드 "one"은 코드 "two" 및 "three"가 있는 노드의 조상입니다. 차례로 코드 "two"가 있는 노드에는 코드 "four"가 있는 노드와 코드 "five"가 있는 노드의 두 자식이 있습니다. 코드 "three"가 있는 노드에는 코드 "six"가 있는 노드가 하나뿐입니다. 따라서 위의 모든 사항을 고려하여 이전 테이블에 포함된 데이터에 대한 정보를 반영하는 트리 구조를 작성해 보겠습니다.
따라서 계층적 재귀 관계를 사용하여 트리 구조를 나타내는 것이 정말 편리하다는 것을 확인했습니다. 2. 네트워크 재귀 통신 엔터티 클래스 간의 네트워크 재귀 연결은 이미 통과한 계층적 재귀 연결의 다차원 유사체입니다. 계층적 재귀가 "최대 일대다" 재귀 관계로 정의된 경우에만 네트워크 재귀 "다대다" 유형의 동일한 재귀 관계를 나타냅니다. 많은 엔터티 클래스가 양쪽에서 이 연결에 참여한다는 사실 때문에 이를 네트워크 연결이라고 합니다. 계층적 재귀와 유사하게 이미 추측할 수 있듯이 네트워크 재귀 유형의 링크는 그래프 데이터 구조를 나타내도록 설계되었습니다(기억하듯이 계층적 링크는 트리 구조 구현에만 사용됨). 그러나 네트워크 재귀 유형의 연결에서 "다 대다"유형의 연결이 지정되므로 추가 세부 사항 없이는 불가능합니다. 따라서 스키마의 모든 다대다 관계를 구체화하려면 Ancestor-Descendant 관계의 부모 또는 자손에 대한 모든 참조를 포함하는 새로운 독립 엔터티 클래스를 생성해야 합니다. 이러한 클래스는 일반적으로 연관 엔티티 클래스. 우리의 특별한 경우(우리 과정에서 고려할 데이터베이스에서) 연관 엔티티에는 자체 추가 속성이 없으며 호출됩니다. 부름, Ancestor-Descendant 관계를 참조하여 이름을 지정하기 때문입니다. 따라서 호스트를 나타내는 엔터티 클래스의 기본 키는 연관 엔터티 클래스로 두 번 마이그레이션되어야 합니다. 이 클래스에서 마이그레이션된 키는 함께 복합 기본 키를 형성해야 합니다. 위에서 우리는 네트워크 재귀를 사용할 때 링크를 설정하는 것이 완전히 식별되어서는 안 되며 다른 어떤 것도 아니라는 결론을 내릴 수 있습니다. 계층적 재귀 관계를 사용할 때와 마찬가지로 네트워크 재귀를 관계로 사용할 때 동일한 엔터티 클래스에 같은 이름으로 속성이 두 번 나타날 수 없습니다. 따라서 지난번과 마찬가지로 마이그레이션 키의 모든 속성에 역할 이름을 부여해야 한다고 구체적으로 규정하고 있습니다. 네트워크 재귀 통신의 작동을 설명하기 위해 관계형 데이터 모델에서 네트워크 재귀를 구현하는 프리젠테이션 및 주요 다이어그램을 작성해 보겠습니다. 프리젠테이션 다이어그램부터 시작하겠습니다.
이제 더 자세한 키 다이어그램을 작성해 보겠습니다.
여기서 무엇을 볼 수 있나요? 그리고 이 핵심 다이어그램의 두 연결은 모두 "다대일" 연결임을 알 수 있습니다. 더욱이 다중성 "0... " 또는 다중성 "다수"는 엔터티의 명명 클래스를 향하는 연결 끝에 있습니다. 실제로 많은 링크가 있지만 모두 "노드" 엔터티 클래스의 기본 키인 하나의 노드 코드를 참조합니다. 그리고 마지막으로 네트워크 재귀와 같은 엔터티 클래스에 의한 연결 유형의 작동을 설명하는 예를 고려해 봅시다. 링크에 대한 정보를 포함하는 이름 지정 엔터티 클래스뿐만 아니라 일부 엔터티 클래스의 표 형식 표현이 제공됩니다. 이 테이블들을 살펴보겠습니다. 매듭:
링크 :
실제로 위의 표현은 철저합니다. 여기에 인코딩된 그래프 구조를 쉽게 재현하기 위해 필요한 모든 정보를 제공합니다. 예를 들어 코드가 "one"인 노드에는 각각 "two", "three" 및 "four"라는 코드가 있는 세 개의 자식이 있음을 장애물 없이 볼 수 있습니다. 또한 "two" 및 "three" 코드가 있는 노드에는 자손이 전혀 없으며 코드 "four"가 있는 노드에는 코드 "one", "two" 및 삼". 위에서 주어진 엔터티 클래스가 제공하는 그래프를 그려봅시다.
따라서 방금 작성한 그래프는 네트워크 재귀 유형 연결을 사용하여 엔티티 클래스가 연결된 데이터입니다. 3. 협회 특정 강의 과정에 포함된 모든 유형의 연결 중에서 재귀 연결은 두 가지뿐입니다. 우리는 이미 그것들을 고려했으며 각각 계층 및 네트워크 재귀 링크입니다. 고려해야 할 다른 모든 유형의 관계는 재귀적이지 않지만 일반적으로 여러 부모 및 여러 자식 엔터티 클래스의 관계를 나타냅니다. 또한 짐작할 수 있듯이 부모 및 자식 엔터티 클래스는 이제 결코 일치하지 않습니다(실제로 더 이상 재귀에 대해 이야기하지 않습니다). 강의의 이 섹션에서 논의할 연결을 연결이라고 하며 정확히 비재귀 유형의 연결을 나타냅니다. 그래서 연결은 협회, 여러 부모 엔터티 클래스와 하나의 자식 엔터티 클래스 간의 관계로 구현됩니다. 그리고 동시에 흥미롭게도 이 관계는 다양한 유형의 관계로 설명됩니다. 네트워크 재귀에서와 같이 연관 중에 부모 엔터티 클래스는 하나만 있을 수 있지만 이러한 상황에서도 자식 엔터티 클래스에서 오는 관계의 수는 두 개 이상이어야 한다는 점도 주목할 가치가 있습니다. 흥미롭게도 연결 및 네트워크 재귀에는 특별한 종류의 엔터티 클래스가 있습니다. 이러한 클래스의 예로는 자식 엔터티 클래스가 있습니다. 실제로 일반적인 경우 연결에서 자식 엔터티 클래스를 호출합니다. 연관 엔티티 클래스. 연관 엔터티 클래스에 고유한 추가 속성이 없고 부모 엔터티 클래스의 기본 키와 함께 마이그레이션되는 속성만 포함하는 특수한 경우 이러한 클래스를 호출합니다. 명명 엔터티 클래스. 보시다시피 네트워크 재귀 연결에서 연관 및 명명 엔터티의 개념과 거의 절대적으로 유사합니다. 대부분의 경우 연결은 다대다 관계를 개선(해결)하는 데 사용됩니다. 이 진술을 설명하겠습니다. 예를 들어 특정 병원에서 특정 의사를 받는 계획을 설명하는 다음 프레젠테이션 다이어그램이 제공됩니다.
이 다이어그램은 문자 그대로 병원에 의사와 환자가 많고 의사와 환자 사이에 다른 관계와 서신이 없다는 것을 의미합니다. 따라서, 물론 그러한 데이터베이스를 사용하면 병원 행정부가 다른 환자를 위해 다른 의사와 약속을 정하는 방법이 결코 명확하지 않을 것입니다. 여기에서 사용되는 다대다 관계는 다양한 의사와 환자 간의 관계를 구체화하기 위해, 즉 모든 의사와 환자의 약속 일정을 합리적으로 구성하기 위해 세부적으로 설명될 필요가 있음이 분명합니다. 병원. 이제 기존의 모든 다대다 관계를 이미 자세히 설명하는 더 자세한 키 다이어그램을 작성해 보겠습니다. 이를 위해 우리는 그에 따라 새로운 엔티티 클래스를 소개할 것입니다. "Receive"라고 부르겠습니다. 이 클래스는 연관 엔티티 클래스 역할을 합니다(나중에 이름 지정 클래스가 아닌 연관 엔티티 클래스가 되는 이유를 나중에 살펴보겠습니다). 이전에 이야기했던 엔터티). 따라서 키 다이어그램은 다음과 같습니다.
이제 새 클래스 "수신"이 명명 엔터티 클래스가 아닌 이유를 명확하게 알 수 있습니다. 결국 이 클래스에는 "Date - Time"이라는 자체 추가 속성이 있으므로 정의에 따라 새로 도입된 "Reception" 클래스는 연관 엔티티 클래스입니다. 이 클래스는 특정 약속이 수행되는 시간을 통해 "의사" 및 "환자" 엔티티 클래스를 서로 "연결"하므로 이러한 데이터베이스 작업이 훨씬 더 편리해집니다. 따라서 "Date - Time" 속성을 도입하여 다양한 의사들에게 절실히 필요한 작업 일정을 말 그대로 정리했습니다. 또한 "Reception" 엔터티 클래스의 외부 기본 키 "Doctor's Code"가 "Doctors" 엔터티 클래스의 동일한 이름 기본 키를 참조하는 것을 볼 수 있습니다. 마찬가지로 "Reception" 엔터티 클래스의 외부 기본 키 "Patient Code"는 "Patient" 엔터티 클래스에서 동일한 이름의 기본 키를 참조합니다. 이 경우 당연히 엔티티 클래스 "의사"와 "환자"가 상위이고 연관 엔티티 클래스 "접수"가 유일한 하위입니다. 이전 프레젠테이션 다이어그램의 다대다 관계가 이제 완전히 자세히 설명되었음을 알 수 있습니다. 위의 프레젠테이션 다이어그램에서 볼 수 있는 하나의 다대다 관계 대신 두 개의 다대일 관계가 있습니다. 첫 번째 관계의 자식 끝에는 다중도 "다수"가 있습니다. 이는 문자 그대로 "접수" 엔터티 클래스에 많은 의사가 있음을 의미합니다(모두 병원에 있음). 그리고 이 관계의 부모 끝에는 "하나"의 다중성이 있습니다. 이것이 무엇을 의미합니까? 즉, "접수" 엔터티 클래스에서 각 특정 의사의 사용 가능한 각 코드는 무한정 여러 번 발생할 수 있습니다. 실제로 병원 일정에서 동일한 의사의 코드가 다른 요일과 시간에 여러 번 발생합니다. 여기에 동일한 코드가 있지만 이미 "Doctors" 엔티티 클래스에서 한 번만 발생할 수 있습니다. 실제로 모든 병원 의사 목록(그리고 "Doctors" 엔티티 클래스는 그러한 목록에 불과함)에서 각 특정 의사의 코드는 한 번만 존재할 수 있습니다. 부모 클래스 "Patient"와 자식 클래스 "Patient" 사이의 관계에서도 비슷한 일이 발생합니다. 모든 병원 환자 목록("Patients" 엔터티 클래스)에서 각 특정 환자의 코드는 한 번만 나타날 수 있습니다. 그러나 약속 일정(엔터티 클래스 "접수")에서 특정 환자의 각 코드는 임의로 여러 번 발생할 수 있습니다. 그것이 결합의 끝에서 다중성이 이런 식으로 배열되는 이유입니다. 관계형 데이터 모델에서 연결 구현의 예로, 컨설턴트의 선택적인 참여로 고객과 계약자 간의 회의 일정을 설명하는 모델을 구축해 보겠습니다. 모든 세부 사항에서 다이어그램의 구성을 고려해야 하고 프레젠테이션 다이어그램은 그러한 기회를 제공할 수 없기 때문에 프레젠테이션 다이어그램에 머 무르지 않을 것입니다. 따라서 고객, 계약자 및 컨설턴트 간의 관계의 본질을 반영하는 핵심 다이어그램을 작성해 봅시다.
이제 위의 키 다이어그램에 대한 자세한 분석을 시작하겠습니다. 첫째, "Graph" 클래스는 연관 엔티티 클래스이지만 이전 예에서와 같이 명명된 엔티티 클래스가 아닙니다. 키와 함께 마이그레이션되지 않는 속성이 있기 때문입니다. 자신의 속성. 이것은 "날짜 - 시간" 속성입니다. 둘째, 자식 엔터티 클래스 "차트" "고객 코드", "집행자 코드" 및 "날짜 - 시간"의 속성이 이 엔터티 클래스의 복합 기본 키를 형성한다는 것을 알 수 있습니다. "고문 코드" 특성은 단순히 "차트" 엔터티 클래스의 외래 키입니다. 조건에 따라 회의에 컨설턴트가 필요하지 않기 때문에 이 속성은 해당 값 중 Null 값을 허용합니다. 또한 세 번째로 (사용 가능한 세 개의 링크 중) 처음 두 개의 링크가 완전히 식별되지 않는다는 점에 유의하십시오. 즉, 두 경우 모두 마이그레이션 키(기본 키 "고객 코드" 및 "실행자 코드")가 "그래프" 엔터티 클래스의 기본 키를 완전히 형성하지 않기 때문에 완전히 식별되지 않습니다. 실제로 복합 기본 키의 일부이기도 한 "날짜 - 시간" 속성이 남아 있습니다. 불완전하게 식별되는 이 두 결합의 끝에 다중성 "일"과 "다수"가 표시됩니다. 이는 (의사와 환자에 대한 예에서와 같이) 고객의 코드를 언급하는 것과 다른 엔터티 클래스에서 수행자를 언급하는 것의 차이점을 보여주기 위해 수행됩니다. 실제로 "그래프" 엔터티 클래스에서 모든 고객 또는 계약자 코드는 원하는 만큼 여러 번 발생할 수 있습니다. 그러므로 이 연결의 끝에는 "다수"의 다중성이 있습니다. 그리고 엔터티 클래스 "고객" 또는 "계약자"에서 고객 또는 계약자의 각 코드는 각각 한 번만 발생할 수 있습니다. 이러한 엔터티 클래스는 각각 모든 고객 및 수행자의 전체 목록에 지나지 않기 때문입니다. 따라서 연결의 상위 끝인 이 지점에는 "하나"의 다중성이 있습니다. 마지막으로 세 번째 관계, 즉 "그래프" 엔터티 클래스와 "컨설턴트" 엔터티 클래스의 관계가 반드시 비식별인 것은 아닙니다. 실제로 이 경우 "컨설턴트" 엔터티 클래스의 키 속성 "컨설턴트 코드"를 동일한 이름의 "그래프" 엔터티 클래스의 키가 아닌 속성, 즉 기본 키로 이전하는 것에 대해 이야기하고 있습니다. "그래프" 엔터티 클래스의 "컨설턴트" 엔터티 클래스는 이 클래스의 기본 키를 이미 식별하지 않습니다. 게다가 앞서 언급했듯이 "Advisor Code" 속성은 Null 값을 허용하므로 여기서는 정확히 비식별 관계가 사용됩니다. 따라서 "Advisor Code" 속성은 외래 키 상태만 획득합니다. 또한 이 불완전한 비식별 링크의 부모 및 자식 끝에 배치된 링크의 다중성에 주목합시다. 부모 끝은 "하나 이상 없음"의 다중성을 갖습니다. 실제로 완전히 비식별적이지 않은 관계의 정의를 상기하면 "그래프" 엔터티 클래스의 "컨설턴트 코드" 특성이 모든 컨설턴트 목록에서 둘 이상의 컨설턴트 코드에 해당할 수 없음을 이해할 수 있습니다. ("컨설턴트" 엔터티 클래스임). 그리고 일반적으로 컨설턴트 코드와 일치하지 않을 수 있습니다 (Null 값 허용 여부에 대한 확인란 기억 컨설턴트 코드: Null). 일반적으로 고객과 계약자 간의 회의는 필요하지 않습니다. 4. 일반화 우리가 고려할 엔티티 클래스 간의 또 다른 유형의 관계는 형식의 관계입니다. 일반화. 또한 비재귀적 유형의 관계입니다. 그래서, 다음과 같은 관계 일반화 하나의 부모 엔터티 클래스와 여러 자식 엔터티 클래스의 관계로 구현됩니다(여러 부모 엔터티 클래스와 하나의 자식 엔터티 클래스를 처리하는 이전 연결 관계와 달리). 일반화 관계를 사용하여 데이터 표현 규칙을 공식화할 때 하나의 상위 엔터티 클래스와 여러 하위 엔터티 클래스의 관계가 완전히 식별되는 관계, 즉 범주 관계로 설명된다는 점을 바로 말해야 합니다. 완전히 식별하는 관계의 정의를 상기하면 일반화를 사용할 때 부모 엔터티 클래스의 기본 키의 각 속성이 자식 엔터티 클래스의 기본 키, 즉 부모의 기본 마이그레이션 키의 속성으로 전송된다는 결론을 내립니다. 엔터티 클래스는 모든 하위 엔터티 클래스의 기본 키를 완전히 형성하며 이를 식별합니다. Generalization이 소위 범주 계층 또는 상속 계층. 이 경우 상위 엔터티 클래스는 다음을 정의합니다. 일반 엔티티 클래스, 모든 하위 클래스의 엔티티에 공통되는 속성 또는 소위 범주형 엔터티 즉, 상위 엔터티 클래스는 모든 하위 엔터티 클래스의 리터럴 일반화입니다. 관계형 데이터 모델에서 일반화 구현의 예로 다음 모델을 구성합니다. 이 모델은 "Students"의 일반화된 개념을 기반으로 하며 "Schoolchildren", "Students" 및 "Postgraduate Students"와 같은 범주별 개념을 설명합니다(즉, 다음 하위 엔터티 클래스를 일반화함). 따라서 일반화 유형의 연결로 설명되는 부모 엔터티 클래스와 자식 엔터티 클래스 간의 관계의 본질을 반영하는 주요 다이어그램을 작성해 보겠습니다.
그래서 우리는 무엇을 봅니까? 첫째, 각각의 기본 관계(또는 동일한 엔터티 클래스에서) "Schoolchildren", "Students" 및 "Postgraduate Students"는 "Class", "Course" 및 "Year of study"와 같은 자체 속성에 해당합니다. " . 이러한 각 특성은 자체 엔터티 클래스의 구성원을 특징짓습니다. 또한 상위 엔터티 클래스 "Students"의 기본 키가 각 하위 엔터티 클래스로 마이그레이션되고 거기에서 기본 외래 키를 형성하는 것을 볼 수 있습니다. 이러한 연결의 도움으로 우리는 학생의 이름, 성 및 부칭, 해당 하위 엔터티 클래스 자체에서 찾을 수 없는 정보를 코드로 결정할 수 있습니다. 둘째, 엔터티 클래스의 완전히 식별되는(또는 범주형) 관계에 대해 이야기하고 있으므로 부모 엔터티 클래스와 해당 자식 클래스 간의 관계의 다양성에 주의를 기울일 것입니다. 이러한 각 링크의 상위 끝은 "XNUMX"의 다중성을 가지며 링크의 각 하위 끝은 "최대 XNUMX"의 다중성을 갖습니다. 엔터티 클래스의 완전히 식별하는 관계의 정의를 상기하면 "Students" 엔터티 클래스의 기본 키인 정말 고유한 학생 코드가 각 자식 엔터티에서 이러한 코드와 함께 최대 하나의 속성을 지정한다는 것이 분명해집니다. 클래스 "학생", "학생" 및 대학원생. 따라서 모든 채권에는 그러한 다중성이 있습니다. 캐스케이드 유형의 참조 무결성을 유지하기 위한 규칙의 정의와 함께 기본 관계 "Schoolchildren" 및 "Students"를 생성하기 위한 연산자의 일부를 작성해 봅시다. 그래서 우리는: 테이블 학생 만들기 ... 기본 키(학생 코드) 외래 키(학생 ID)는 학생(학생 ID)을 참조합니다. 업데이트 캐스케이드 계단식 삭제 시 테이블 학생 만들기 ... 기본 키(학생 코드) 외래 키(학생 ID)는 학생(학생 ID)을 참조합니다. 업데이트 캐스케이드 계단식 삭제 시; 따라서 자식 엔터티 클래스(또는 관계) "Student"에서 부모 엔터티 클래스(또는 관계) "Students"를 참조하는 기본 외래 키가 지정되었음을 알 수 있습니다. 참조 무결성을 유지하기 위한 계단식 규칙은 상위 엔터티 클래스 "학생"의 속성이 삭제되거나 업데이트될 때 자식 관계 "학생"의 해당 속성이 자동으로(계단식으로) 업데이트되거나 삭제되도록 결정합니다. 마찬가지로 상위 엔터티 클래스 "Students"의 속성이 삭제되거나 업데이트되면 하위 관계 "Students"의 해당 속성도 자동으로 업데이트되거나 삭제됩니다. 여기에서 사용되는 것은 이 참조 무결성 규칙이라는 점에 유의해야 합니다. 왜냐하면 이 컨텍스트(학생 목록)에서 정보의 삭제 및 업데이트를 금지하고 실제 정보 대신 정의되지 않은 값을 할당하는 것은 합리적이지 않기 때문입니다. . 이제 이전 다이어그램에서 설명한 엔터티 클래스의 예를 표 형식으로만 제공하겠습니다. 따라서 다음과 같은 관계 테이블이 있습니다. 학생 - 다른 모든 관계의 속성에 대한 정보를 결합하는 상위 관계:
학생 - 자식 관계:
학생 - 두 번째 자식 관계:
박사 과정 학생 - 세 번째 자식 관계:
따라서 실제로 엔티티의 자식 클래스에는 학생, 즉 학생, 학생 및 대학원생의 성, 이름 및 후원에 대한 정보가 포함되어 있지 않습니다. 이 정보는 상위 엔티티 클래스에 대한 참조를 통해서만 얻을 수 있습니다. 또한 "Students" 엔터티 클래스의 다른 학생 코드가 다른 하위 엔터티 클래스에 해당할 수 있음을 알 수 있습니다. 따라서 코드가 "1"인 학생 Nikolai Zabotin에 대해서는 그의 이름을 제외하고는 부모 관계에서 알려진 바가 없으며 다른 모든 정보(그가 누구인지, 남학생, 학생 또는 대학원생)는 참조를 통해서만 찾을 수 있습니다. 해당 자식 엔터티 클래스(코드에 의해 결정됨)로. 마찬가지로 상위 엔터티 클래스 "Students"에 코드가 지정된 나머지 학생과 함께 작업해야 합니다. 5. 구성 구성 유형의 엔터티 클래스 관계는 앞의 두 항목과 마찬가지로 순환 관계 유형에 속하지 않습니다. 구성 (또는 때때로 불리는 것처럼, 복합 집계)는 앞서 논의한 관계와 마찬가지로 단일 상위 엔티티 클래스와 여러 하위 엔티티 클래스의 관계입니다. 일반화. 그러나 일반화가 관계를 완전히 식별하여 기술된 엔터티 클래스의 관계로 정의된 경우 컴포지션은 불완전한 관계 식별로 기술됩니다. 자식 엔터티 클래스의 동시에 마이그레이션 키 속성은 하위 엔터티 클래스의 기본 키를 부분적으로만 형성합니다. 따라서 복합 집계(컴포지션 포함)를 사용하면 상위 엔터티 클래스(또는 단위)가 여러 자식 엔터티 클래스(또는 구성 요소). 이 경우 집계의 구성 요소(즉, 상위 엔터티 클래스의 구성 요소)는 기본 키의 일부인 외래 키를 통해 집계를 참조하므로 집계 외부에 존재할 수 없습니다. 일반적으로 복합 집계는 단순 집계의 향상된 형태입니다(이에 대해서는 나중에 설명하겠습니다). 컴포지션(또는 복합 집계)은 다음과 같은 특징이 있습니다. 1) 어셈블리에 대한 참조가 구성 요소 식별에 포함됩니다. 2) 이러한 구성 요소는 집계 외부에 존재할 수 없습니다. 필연적으로 비식별 관계가 있는 집계(자세히 고려할 관계)도 구성 요소가 집계 외부에 존재하는 것을 허용하지 않으므로 의미상 위에서 설명한 복합 집계 구현과 유사합니다. 하나의 부모 엔터티 클래스와 여러 자식 엔터티 클래스 사이의 관계, 즉 복합 집계 유형의 엔터티 클래스 관계를 설명하는 키 다이어그램을 작성해 보겠습니다. 이것은 건물, 교실 및 엘리베이터를 포함하여 특정 캠퍼스의 건물 구성을 나타내는 주요 다이어그램입니다. 따라서 이 다이어그램은 다음과 같습니다.
이제 방금 만든 다이어그램을 살펴보겠습니다. 무엇을 볼 수 있습니까? 첫째, 이 복합 집계에 사용된 관계가 실제로 식별되고 실제로 완전히 식별되지는 않는다는 것을 알 수 있습니다. 결국 상위 엔터티 클래스 "Buildings"의 기본 키는 하위 엔터티 클래스 "Audiences" 및 "Elevators"의 기본 키 형성에 관여하지만 완전히 정의하지는 않습니다. 상위 엔터티 클래스의 기본 키 "Case No"는 두 자식 클래스의 외래 기본 키 "Case No"로 마이그레이션되지만 이 마이그레이션된 키 외에도 두 자식 엔터티 클래스에는 각각 고유한 기본 키인 "Audience"가 있습니다. No' 및 'Elevator No. 이제 상위 클래스와 두 하위 클래스를 연결하는 링크의 다양성을 살펴보겠습니다. 우리는 불완전한 식별 링크를 다루고 있기 때문에 "하나"와 "다수"라는 다중성이 존재합니다. 다중성 "하나"는 두 관계의 상위 끝에 존재하며 사용 가능한 모든 말뭉치 목록(및 엔터티 클래스 "말뭉치"는 바로 그러한 목록임)에서 각 숫자가 한 번만 나타날 수 있음을 상징합니다. 그보다) 번. 그리고 차례로 "관람객"과 "엘리베이터" 클래스의 속성 중 각 건물 번호는 건물보다 관객(또는 엘리베이터)이 더 많기 때문에 여러 번 나타날 수 있으며 각 건물에는 여러 개의 강당과 엘리베이터가 있습니다. 따라서 모든 교실과 엘리베이터를 나열할 때 부득이하게 건물 번호를 반복하게 됩니다. 그리고 마지막으로 이전 유형의 연결의 경우와 마찬가지로 기본 관계(또는 동일한 항목 클래스) "Audiences" 및 "Elevators"를 생성하기 위한 연산자의 조각을 적어 보겠습니다. 캐스케이드 유형의 참조 무결성을 유지하기 위한 규칙 정의로 이를 수행하십시오. 따라서 이 진술은 다음과 같을 것입니다. 표 잠재고객 만들기 ... 기본 키(말뭉치 번호, 청중 번호) 외래 키(케이스 번호) 참조 패턴(케이스 번호) 업데이트 캐스케이드 계단식 삭제 시 테이블 리프트 만들기 ... 기본 키(케이스 번호, 엘리베이터 번호) 외래 키(케이스 번호) 참조 패턴(케이스 번호) 업데이트 캐스케이드 계단식 삭제 시; 따라서 자식 엔터티 클래스의 필수 기본 키와 외래 키를 모두 설정했습니다. 우리는 이미 가장 합리적이라고 설명했기 때문에 참조 무결성을 유지하는 규칙을 계단식으로 다시 취했습니다. 이제 방금 고려한 모든 엔터티 클래스의 표 형식으로 예제를 제공합니다. 표 형식의 다이어그램을 사용하여 반영한 기본 관계를 설명하고 명확성을 위해 일정량의 지표 데이터를 소개합니다. 껍질 부모 관계는 다음과 같습니다.
청중 - 하위 엔티티 클래스:
엘리베이터 - 상위 클래스 "인클로저"의 두 번째 하위 엔티티 클래스:
따라서 실제 교육 기관에서 사용할 수 있는 이 데이터베이스에서 모든 건물, 교실 및 엘리베이터에 대한 정보가 어떻게 구성되어 있는지 확인할 수 있습니다. 6. 집계 집계는 과정의 일부로 간주되는 엔터티 클래스 간의 관계의 마지막 유형입니다. 또한 재귀적이지 않으며 두 가지 유형 중 하나는 이전에 고려된 복합 집계와 매우 유사합니다. 따라서, 집합 하나의 상위 엔티티 클래스와 여러 하위 엔티티 클래스의 관계입니다. 이 경우 관계는 두 가지 유형의 관계로 설명할 수 있습니다. 1) 필연적으로 비식별 링크; 2) 선택적 비식별 링크. 필연적으로 비식별 관계로 부모 엔터티 클래스의 기본 키의 일부 속성이 자식 클래스의 키가 아닌 속성으로 전송되고 마이그레이션 키의 모든 속성에 대한 Null 값이 금지된다는 점을 기억하십시오. 반드시 비식별 관계는 아니지만 기본 키의 마이그레이션은 정확히 동일한 원칙에 따라 발생하지만 마이그레이션 키의 일부 속성에 대해 Null 값이 허용됩니다. 집계할 때 상위 엔티티 클래스(또는 단위)가 여러 자식 엔터티 클래스(또는 구성 요소). 집계의 구성 요소(즉, 상위 엔터티 클래스)는 기본 키의 일부가 아닌 외래 키를 통해 집계를 참조하므로 다음과 같은 경우 반드시 비식별 링크는 아님, 집계 구성 요소는 집계 외부에 존재할 수 있습니다. 필연적으로 비식별 관계를 갖는 집합체의 경우 집합체의 구성 요소가 집합체 외부에 존재하는 것을 허용하지 않으며, 이러한 의미에서 필연적으로 비식별 관계를 갖는 집합체는 복합 집합체에 가깝습니다. 이제 집계 유형 관계가 무엇인지 명확해졌으므로 이 관계의 작동을 설명하는 주요 다이어그램을 작성해 보겠습니다. 미래의 도표가 자동차의 표시된 구성 요소(즉, 엔진과 섀시)를 설명하도록 하십시오. 동시에, 우리는 자동차의 폐기가 섀시의 폐기를 의미하지만 엔진의 동시 폐기를 의미하지는 않는다고 가정합니다. 따라서 키 다이어그램은 다음과 같습니다.
이 핵심 다이어그램에서 무엇을 볼 수 있습니까? 첫째, 상위 엔터티 클래스 "Cars"와 자식 엔터티 클래스 "Engines"의 관계는 "car #" 속성이 해당 값 중 null 값을 허용하기 때문에 반드시 비식별적일 필요는 없습니다. 차례로 이 속성은 조건에 따라 엔진의 폐기가 전체 차량의 폐기에 의존하지 않으므로 자동차를 폐기할 때 반드시 발생하는 것은 아니기 때문에 Null 값을 허용합니다. 또한 "Cars" 엔터티 클래스의 "Engine #" 기본 키가 "Engines" 엔터티 클래스의 키가 아닌 속성 "Engine #"으로 마이그레이션되는 것을 볼 수 있습니다. 동시에 이 속성은 외래 키 상태를 획득합니다. 그리고 이 Engines 엔터티 클래스의 기본 키는 상위 관계의 속성을 참조하지 않는 Engine Marker 속성입니다. 둘째로, 외래 키 속성 "Car #"은 그 값 중에 Null 값을 허용하지 않기 때문에 상위 엔터티 클래스 "Motors"와 자식 엔터티 클래스 "Chassis" 간의 관계는 필연적으로 비식별 관계입니다. 이는 차량의 폐기가 섀시의 필수 동시 폐기를 의미한다는 조건으로 알려져 있기 때문에 발생합니다. 여기서는 이전 관계의 경우와 마찬가지로 상위 엔터티 클래스 "Motors"의 기본 키가 하위 엔터티 클래스 "Chassis"의 키가 아닌 속성 "Car number"로 마이그레이션됩니다. 동시에 이 엔터티 클래스의 기본 키는 "섀시 마커" 속성이며 "모터" 상위 관계의 속성을 참조하지 않습니다. 계속하세요. 주제를 최대한 이해하기 위해 참조 무결성을 유지하기 위한 규칙의 정의와 함께 기본 관계 "모터" 및 "섀시"를 생성하기 위한 연산자 조각을 다시 작성해 보겠습니다. 테이블 엔진 만들기 ... 기본 키(모터 마커) 외래 키(차량 번호)는 자동차(차량 번호)를 참조합니다. 업데이트 캐스케이드 삭제 시 Null 설정 테이블 섀시 생성 ... 기본 키(섀시 마커) 외래 키(차량 번호)는 자동차(차량 번호)를 참조합니다. 업데이트 캐스케이드 계단식 삭제 시; 우리는 모든 곳에서 참조 무결성을 유지하기 위해 동일한 규칙을 사용했음을 알 수 있습니다. 캐스케이드, 이전에도 가장 합리적인 것으로 인식했기 때문입니다. 그러나 이번에는 캐스케이드 규칙에 추가하여 Null 참조 무결성 규칙을 사용했습니다. 또한 다음 조건에서 사용했습니다. 상위 엔터티 클래스 "Cars"에서 기본 키 "Car number"의 일부 값이 삭제되면 자식 관계 "Engines"의 외래 키 "Car number" 값이 삭제됩니다. 그것을 참조하면 Null 값이 할당됩니다. 7. 속성의 통일 특정 부모 엔터티 클래스의 기본 키를 마이그레이션하는 동안 의미가 일치하는 다른 부모 클래스의 속성이 동일한 자식 클래스에 들어가면 이러한 속성을 "병합"해야 합니다. -라고 불리는 속성의 통일. 예를 들어 직원이 조직에서 일할 수 있고 하나의 부서에만 나열되는 경우 "조직 코드" 속성을 통합한 후 다음 키 다이어그램을 얻습니다.
상위 엔터티 클래스 "조직" 및 "부서"에서 하위 클래스 "직원"으로 기본 키를 마이그레이션할 때 속성 "조직 ID"는 엔터티 클래스 "직원"으로 가져옵니다. 그리고 두 번: 1) 마커로 처음 PF불완전한 식별 관계를 설정할 때 엔터티 클래스 "조직"의 K; 2) 두 번째로, 반드시 비식별 관계를 설정할 때 "부서" 엔터티 클래스에서 Null 값을 수락하는 조건이 있는 FK 마커를 사용합니다. 통합되면 "조직 ID" 속성은 기본/외래 키 속성의 상태를 취하여 외래 키 속성의 상태를 흡수합니다. 통합 프로세스 자체를 보여주는 새로운 주요 다이어그램을 작성해 보겠습니다.
따라서 속성의 통일이 이루어졌습니다. 강의 13. 전문가 시스템과 지식 생산 모델 1. 전문가 시스템의 임명 우리에게 다음과 같은 새로운 개념에 익숙해지기 위해 전문가 시스템 우선, "전문가 시스템" 방향의 생성 및 개발 역사를 살펴본 다음 전문가 시스템의 개념을 정의할 것입니다. 80년대 초반. XNUMX 세기 인공 지능 생성에 관한 연구에서 새로운 독립 방향이 형성되었습니다. 전문가 시스템. 전문가 시스템에 대한 이 새로운 연구의 목적은 특정 유형의 문제를 해결하도록 설계된 특수 프로그램을 개발하는 것입니다. 완전히 새로운 지식 공학의 창출을 필요로 하는 이 특별한 종류의 문제는 무엇입니까? 이 특수 유형의 작업에는 모든 주제 영역의 작업이 포함될 수 있습니다. 일반 문제와 구별되는 주된 점은 인간 전문가가 문제를 해결하는 것이 매우 어려운 작업으로 보인다는 것입니다. 그런 다음 첫 번째 소위 전문가 시스템 (전문가의 역할은 더 이상 사람이 아니라 기계였습니다) 전문가 시스템은 전문가 인 평범한 사람이 얻은 솔루션보다 품질과 효율성면에서 열등하지 않은 결과를받습니다. 전문가 시스템의 작업 결과는 매우 높은 수준에서 사용자에게 설명될 수 있습니다. 이러한 전문가 시스템의 품질은 자신의 지식과 결론에 대해 추론할 수 있는 능력에 의해 보장됩니다. 전문가 시스템은 전문가와의 상호 작용 과정에서 자신의 지식을 보충할 수 있습니다. 따라서 완전한 형태의 인공 지능과 동등하게 완전한 자신감을 가질 수 있습니다. 전문가 시스템 분야의 연구자들은 종종 독일 과학자 E. Feigenbaum이 "인공 지능 분야의 연구 원리와 도구를 문제 해결에 도입한 것"이라고 소개한 이전에 언급한 "지식 공학"이라는 용어를 해당 분야의 이름으로 사용합니다. 전문지식을 요하는 어려운 응용문제" 그러나 개발 회사의 상업적 성공은 즉시 이루어지지 않았습니다. 1960년부터 1985년까지 1985반세기 동안. 인공 지능의 성공은 주로 연구 개발과 관련이 있습니다. 그러나 1987년경부터 시작하여 1990년부터 XNUMX년까지 대규모로 진행되었다. 전문가 시스템은 상용 응용 프로그램에서 활발히 사용되었습니다. 전문가 시스템의 장점은 상당히 크며 다음과 같습니다. 1) 전문가 시스템 기술은 개인용 컴퓨터에서 해결되는 실질적으로 중요한 작업의 범위를 크게 확장하며, 그 솔루션은 상당한 경제적 이점을 가져오고 모든 관련 프로세스를 크게 단순화합니다. 2) 전문가 시스템 기술은 기간, 품질 및 결과적으로 복잡한 응용 프로그램 개발의 높은 비용과 같은 전통적인 프로그래밍의 글로벌 문제를 해결하는 데 가장 중요한 도구 중 하나이며 그 결과 경제적 효과가 크게 감소했습니다. ; 3) 복잡한 시스템의 운영 및 유지 관리 비용이 높으며, 이는 종종 개발 자체 비용을 몇 배 초과할 뿐만 아니라 프로그램의 낮은 수준의 재사용성 등입니다. 4) 전문가 시스템 기술과 전통적인 프로그래밍 기술의 결합은 먼저 프로그래머가 아닌 일반 사용자가 응용 프로그램을 동적으로 수정할 수 있도록 함으로써 소프트웨어 제품에 새로운 품질을 추가합니다. 둘째, 응용 프로그램의 더 큰 "투명성", 더 나은 그래픽, 인터페이스 및 전문가 시스템의 상호 작용입니다. 일반 사용자와 주요 전문가에 따르면 가까운 장래에 전문가 시스템은 다음과 같은 응용 프로그램을 찾을 수 있습니다. 1) 전문가 시스템은 설계, 개발, 생산, 배포, 디버깅, 제어 및 서비스 제공의 모든 단계에서 주도적인 역할을 할 것입니다. 2) 광범위한 상업적 유통을 받은 전문가 시스템 기술은 기성 지능형 상호 작용 모듈의 응용 프로그램 통합에 혁신적인 돌파구를 제공할 것입니다. 일반적으로 전문가 시스템은 소위 비공식 작업즉, 전문가 시스템은 형식화된 문제 해결에 초점을 맞춘 프로그램 개발에 대한 전통적인 접근 방식을 거부하거나 대체하지 않고 이를 보완하여 가능성을 크게 확장합니다. 이것은 단순한 인간 전문가가 할 수 없는 일입니다. 이러한 복잡한 비공식 작업은 다음과 같은 특징이 있습니다. 1) 원본 데이터의 오류, 부정확성, 모호성, 불완전성 및 불일치성 2) 문제 영역과 해결되는 문제에 대한 지식의 오류, 모호성, 부정확성, 불완전성 및 불일치; 3) 특정 문제에 대한 솔루션 공간의 큰 차원; 4) 이러한 비공식적 문제를 해결하는 과정에서 직접 데이터와 지식의 동적 가변성. 전문가 시스템은 주로 알려진 알고리즘의 실행이 아니라 솔루션에 대한 휴리스틱 검색을 기반으로 합니다. 이것은 소프트웨어 개발에 대한 전통적인 접근 방식에 비해 전문가 시스템 기술의 주요 이점 중 하나입니다. 이것이 그들이 그들에게 할당된 작업에 잘 대처할 수 있게 해주는 것입니다. 전문가 시스템 기술은 다양한 문제를 해결하는 데 사용됩니다. 이러한 작업의 주요 항목을 나열합니다. 1. 통역. 해석을 수행하는 전문가 시스템은 상황을 설명하기 위해 다양한 도구의 판독값을 가장 자주 사용합니다. 해석 전문가 시스템은 다양한 유형의 정보를 처리할 수 있습니다. 예를 들어 물질의 조성과 특성을 결정하기 위해 스펙트럼 분석 데이터와 물질 특성의 변화를 사용합니다. 또한 보일러와 그 안의 물의 상태를 설명하기 위해 보일러실에 있는 측정 장비의 판독 값을 해석하는 것이 그 예입니다. 해석 시스템은 대부분 판독값을 직접 처리합니다. 이와 관련하여 다른 유형의 시스템에는 없는 어려움이 발생합니다. 이 어려움은 무엇입니까? 이러한 어려움은 전문가 시스템이 막힌 불필요하고 불완전하며 신뢰할 수 없거나 잘못된 정보를 해석해야 한다는 사실 때문에 발생합니다. 따라서 오류 또는 데이터 처리의 상당한 증가가 불가피합니다. 2. 예측. 예측을 수행하는 전문가 시스템은 주어진 상황의 확률적 조건을 결정합니다. 예를 들어 악천후로 인한 곡물 수확 피해 예측, 세계 시장의 가스 수요 평가, 기상 관측소에 따른 일기 예보 등이 있습니다. 예측 시스템은 때때로 모델링, 즉 프로그래밍 환경에서 관계를 재현하기 위해 실제 세계에서 일부 관계를 표시하는 프로그램을 사용한 다음 특정 초기 데이터로 발생할 수 있는 상황을 설계합니다. 3. 다양한 장치 진단. 전문가 시스템은 오작동하는 진단 가능한 시스템의 가능한 원인을 결정하기 위해 다양한 구성 요소의 구조에 대한 상황, 동작 또는 데이터에 대한 설명을 사용하여 이러한 진단을 수행합니다. 예는 환자에게서 관찰되는 증상에 의한 질병 상황의 확립입니다(의학에서). 전자 회로의 결함 식별 및 다양한 장치의 메커니즘에서 결함이 있는 구성 요소 식별. 진단 시스템은 진단을 내릴 뿐만 아니라 문제 해결에도 도움을 주는 보조 장치인 경우가 많습니다. 이러한 경우 이러한 시스템은 사용자와 상호 작용하여 문제 해결을 지원한 다음 문제를 해결하는 데 필요한 작업 목록을 제공할 수 있습니다. 현재 많은 진단 시스템이 엔지니어링 및 컴퓨터 시스템에 대한 응용 프로그램으로 개발되고 있습니다. 4. 다양한 이벤트 기획. 다양한 운영 설계를 계획하기 위해 설계된 전문가 시스템. 시스템은 구현이 시작되기 전에 거의 완전한 일련의 작업을 미리 결정합니다. 이러한 사건 계획의 예는 적군보다 우위를 점하기 위해 일정 기간 동안 미리 결정된 방어 및 공격 군사 작전 계획 수립입니다. 5. 디자인. 디자인을 수행하는 전문가 시스템은 일반적인 상황과 모든 관련 요소를 고려하여 다양한 형태의 객체를 개발합니다. 예를 들면 유전 공학입니다. 6. 제어. 통제를 행사하는 전문가 시스템은 시스템의 현재 동작을 예상 동작과 비교합니다. 전문가 시스템을 관찰하면 예상과 정상적인 행동 또는 잠재적 편차에 대한 가정을 확인하는 통제된 행동을 감지합니다. 제어 전문가 시스템은 본질적으로 실시간으로 작동해야 하며 제어 대상의 동작에 대한 시간 종속적 및 컨텍스트 종속적 해석을 구현해야 합니다. 예를 들어 응급 상황을 감지하기 위해 원자로에서 측정 장비의 판독값을 모니터링하거나 중환자실에 있는 환자의 진단 데이터를 평가하는 것이 포함됩니다. 7. 거버넌스. 결국, 통제를 행사하는 전문가 시스템이 시스템 전체의 동작을 매우 효과적으로 관리한다는 것은 널리 알려져 있습니다. 예를 들어 다양한 산업의 관리와 컴퓨터 시스템의 배포가 있습니다. 제어 전문가 시스템은 장기간에 걸쳐 개체의 동작을 제어하기 위해 관찰 구성 요소를 포함해야 하지만 이미 분석된 작업 유형의 다른 구성 요소가 필요할 수도 있습니다. 전문가 시스템은 금융 거래, 석유 및 가스 산업 등 다양한 분야에서 사용됩니다. 전문가 시스템 기술은 에너지, 운송, 제약 산업, 우주 개발, 야금 및 광산업, 화학 및 기타 여러 분야에도 적용될 수 있습니다. 2. 전문가 시스템의 구조 전문가 시스템의 개발은 기존 소프트웨어 제품의 개발과 많은 중요한 차이점이 있습니다. 전문가 시스템을 만든 경험에 따르면 기존 프로그래밍에서 채택한 방법론을 개발에 사용하면 전문가 시스템을 만드는 데 소요되는 시간이 크게 증가하거나 부정적인 결과를 초래할 수 있습니다. 전문가 시스템은 일반적으로 다음과 같이 나뉩니다. 공전 и 동적. 먼저 정적 전문가 시스템을 고려하십시오. 표준 정적 전문가 시스템 다음과 같은 주요 구성 요소로 구성됩니다. 1) 데이터베이스라고도 하는 작업 메모리 2) 지식 기반; 3) 인터프리터라고도 하는 해석기; 4) 지식 습득의 구성 요소; 5) 설명 요소; 6) 대화 구성 요소. 이제 각 구성 요소를 더 자세히 살펴보겠습니다. 작업 기억 (작업, 즉 컴퓨터 RAM과 절대적으로 유추하여) 현재 해결 중인 작업의 초기 및 중간 데이터를 수신하고 저장하도록 설계되었습니다. База знаний 특정 주제 영역을 설명하는 장기 데이터와 해결되는 문제의 이 영역에서 데이터의 합리적인 변환을 설명하는 규칙을 저장하도록 설계되었습니다. 솔버,라고도 함 통역사, 다음과 같이 기능합니다. 작업 메모리의 초기 데이터와 지식 기반의 장기 데이터를 사용하여 규칙을 형성하고 초기 데이터에 적용하면 문제가 해결됩니다. 한마디로 그는 자신 앞에 놓인 문제를 실제로 "해결"합니다. 지식 습득 구성요소 전문가 시스템을 전문 지식으로 채우는 프로세스를 자동화합니다. 즉, 이 특정 주제 영역에서 필요한 모든 정보를 지식 기반에 제공하는 구성 요소입니다. 구성 요소 설명 시스템이 이 문제에 대한 솔루션을 얻은 방법 또는 이 솔루션을 받지 못한 이유와 그렇게 하는 데 사용한 지식을 설명합니다. 즉, Explain 구성 요소는 진행률 보고서를 생성합니다. 이 구성 요소는 전체 전문가 시스템에서 매우 중요합니다. 전문가의 시스템 테스트를 크게 용이하게 하고 얻은 결과에 대한 사용자의 신뢰도를 높여 개발 프로세스를 가속화하기 때문입니다. 대화 구성 요소 문제를 해결하는 과정과 지식을 습득하고 작업 결과를 선언하는 과정 모두에서 친숙한 사용자 인터페이스를 제공합니다. 이제 통계 전문가 시스템이 일반적으로 어떤 구성 요소로 구성되는지 알았으므로 이러한 전문가 시스템의 구조를 반영하는 다이어그램을 작성해 보겠습니다. 다음과 같이 보입니다.
정적 전문가 시스템은 문제를 해결하는 동안 발생하는 환경 변화를 고려하지 않을 수 있는 기술 응용 프로그램에서 가장 자주 사용됩니다. 실제 적용을 받은 최초의 전문가 시스템이 정확히 정적이라는 사실이 궁금합니다. 이상으로 통계 전문가 시스템에 대한 고찰은 여기까지 하고 동적 전문가 시스템에 대한 분석으로 넘어 갑시다. 불행히도 우리 과정의 프로그램에는 이 전문가 시스템에 대한 자세한 고려가 포함되어 있지 않으므로 동적 전문가 시스템과 정적 전문가 시스템 간의 가장 기본적인 차이점만 분석하는 것으로 제한할 것입니다. 정적 전문가 시스템과 달리 구조는 역동적인 전문가 시스템 또한 다음 두 가지 구성 요소가 도입되었습니다. 1) 외부 세계를 모델링하기 위한 서브시스템; 2) 외부 환경과의 관계 하위 시스템. 외부 환경과의 관계 하위 시스템 외부 세계와 연결될 뿐입니다. 그녀는 특수 센서 및 컨트롤러 시스템을 통해 이를 수행합니다. 또한 정적 전문가 시스템의 일부 기존 구성 요소는 현재 환경에서 발생하는 이벤트의 시간적 논리를 반영하기 위해 상당한 변화를 겪습니다. 이것이 정적 전문가 시스템과 동적 전문가 시스템의 주요 차이점입니다. 역동적인 전문가 시스템의 예는 제약 산업에서 다양한 의약품의 생산 관리입니다. 3. 전문가 시스템 개발 참여자 다양한 전문 분야의 대표자가 전문가 시스템 개발에 참여합니다. 대부분의 경우 세 명의 전문가가 특정 전문가 시스템을 개발합니다. 일반적으로 다음과 같습니다. 1) 전문가 2) 지식 엔지니어 3) 도구 개발을 위한 프로그래머. 여기에 나열된 각 전문가의 책임을 설명하겠습니다. 전문가 는 해당 분야의 전문가로, 개발 중인 이 특정 전문가 시스템의 도움으로 과제를 해결할 것입니다. 지식 엔지니어 전문가 시스템을 직접 개발하는 전문가입니다. 그가 사용한 기술과 방법을 지식공학 기술과 방법이라고 한다. 지식 엔지니어는 전문가가 주제 영역의 모든 정보에서 개발 중인 특정 전문가 시스템과 작업하는 데 필요한 정보를 식별하고 구조화하는 데 도움을 줍니다. 개발 참여자 중 지식 엔지니어의 부재, 즉 프로그래머로 교체하면 특정 전문가 시스템을 만드는 전체 프로젝트가 실패하거나 개발 시간이 크게 늘어나는 것이 궁금합니다. 그리고 마지막으로, 프로그래머 전문가 시스템의 개발을 가속화하도록 설계된 도구(도구가 새로 개발된 경우)를 개발합니다. 이러한 도구에는 전문가 시스템의 모든 주요 구성 요소가 제한적으로 포함되어 있습니다. 프로그래머는 또한 자신의 도구를 사용할 환경과 인터페이스합니다. 4. 전문가 시스템의 작동 모드 전문가 시스템은 두 가지 주요 모드로 작동합니다. 1) 지식 습득 방식 2) 문제 해결 방식(협의 방식 또는 전문가 시스템 사용 방식이라고도 함). 이것은 논리적이고 이해할 수 있습니다. 왜냐하면 먼저 전문가 시스템이 작동해야 하는 주제 영역의 정보를 전문가 시스템에 로드하는 것이 필요하기 때문입니다. 이것은 전문가 시스템의 "훈련" 모드입니다. 지식을 받습니다. 그리고 작업에 필요한 모든 정보를 불러온 후 작업 자체가 이어집니다. 전문가 시스템은 작동 준비가 되고 이제 상담이나 문제 해결에 사용할 수 있습니다. 더 자세히 고려하자 지식 습득 모드. 지식 습득 모드에서 전문가 시스템과의 작업은 지식 엔지니어를 통해 전문가가 수행합니다. 이 모드에서 전문가는 지식 획득 구성 요소를 사용하여 시스템을 지식(데이터)으로 채웁니다. 그러면 시스템이 전문가의 참여 없이 솔루션 모드에서 이 주제 영역의 문제를 해결할 수 있습니다. 프로그램 개발에 대한 전통적인 접근 방식의 지식 획득 모드는 프로그래머가 직접 수행하는 알고리즘화, 프로그래밍 및 디버깅 단계에 해당한다는 점에 유의해야 합니다. 전통적인 접근 방식과 달리 전문가 시스템의 경우 프로그램 개발은 프로그래머가 아니라 전문가 시스템의 도움을 받아 전문가에 의해 수행됩니다. , 프로그래밍을 모르는 사람. 그리고 이제 전문가 시스템의 두 번째 기능 모드, 즉 문제 해결 모드. 문제 해결 모드(또는 소위 상담 모드)에서 전문가 시스템과의 통신은 작업의 최종 결과와 때로는 이를 얻는 방법에 관심이 있는 최종 사용자가 직접 수행합니다. 전문가 시스템의 목적에 따라 사용자가 이 문제 영역의 전문가일 필요는 없습니다. 이 경우 그는 결과를 얻기 위한 충분한 지식이 없는 전문가 시스템에 의존하여 결과를 얻습니다. 또는 사용자가 스스로 원하는 결과를 달성하기에 충분한 수준의 지식을 가지고 있을 수도 있습니다. 이 경우 사용자는 결과를 직접 얻을 수 있지만 결과를 얻는 프로세스의 속도를 높이거나 단조로운 작업을 전문가 시스템에 할당하기 위해 전문가 시스템을 사용합니다. 상담 모드에서 사용자의 작업에 대한 데이터는 대화 구성 요소에 의해 처리된 후 작업 메모리에 들어갑니다. 솔버는 작업 메모리의 입력 데이터, 문제 영역에 대한 일반 데이터 및 데이터베이스의 규칙을 기반으로 문제에 대한 솔루션을 생성합니다. 문제를 해결할 때 전문가 시스템은 특정 작업의 규정된 순서를 실행할 뿐만 아니라 사전에 구성합니다. 이는 시스템의 반응이 사용자에게 완전히 명확하지 않은 경우에 수행됩니다. 이 상황에서 사용자는 이 전문가 시스템이 특정 질문을 하는 이유 또는 이 전문가 시스템이 이 작업을 수행할 수 없는 이유, 이 전문가 시스템이 제공하는 이 또는 저 결과를 얻는 방법에 대한 설명을 요구할 수 있습니다. 5. 지식 생산 모델 핵심에서, 지식 생산 모델 논리적 모델에 가깝기 때문에 논리적 데이터 추론을 위한 매우 효과적인 절차를 구성할 수 있습니다. 이것은 한편입니다. 그러나 반면에 지식의 생산 모델을 논리적 모델과 비교하여 고려하면 전자가 지식을 더 명확하게 표시한다는 점은 부인할 수 없는 이점입니다. 따라서 의심할 여지 없이 지식의 생산 모델은 인공 지능 시스템에서 지식을 표현하는 주요 수단 중 하나입니다. 이제 지식 생산 모델의 개념에 대한 자세한 고려를 시작하겠습니다. 전통적인 지식 생산 모델에는 다음과 같은 기본 구성 요소가 포함됩니다. 1) 생산 시스템의 지식 기반을 나타내는 일련의 규칙(또는 생산물) 2) 원래 사실뿐만 아니라 추론 메커니즘을 사용하여 원래 사실에서 파생된 사실을 저장하는 작업 메모리; 3) 기존 추론 규칙에 따라 사용 가능한 사실에서 새로운 사실을 도출할 수 있는 논리적 추론 메커니즘 자체. 그리고 이상하게도 그러한 작업의 수는 무한할 수 있습니다. 생산 시스템의 지식 기반을 나타내는 각 규칙에는 조건부 및 최종 부분이 포함됩니다. 규칙의 조건부 부분에는 접속사로 연결된 단일 사실 또는 여러 사실이 포함됩니다. 규칙의 마지막 부분에는 규칙의 조건부 부분이 참인 경우 작업 메모리로 보충해야 하는 사실이 포함되어 있습니다. 지식의 생산 모델을 개략적으로 묘사하려고 하면 생산은 다음 형식의 표현으로 이해됩니다. (i) 질문; 피; A→B; N; 여기서 i는 지식 생산 모델의 이름 또는 일련 번호이며, 이 생산은 일종의 식별을 받는 전체 생산 모델 세트와 구별되는 데 도움이 됩니다. 이 제품의 본질을 반영하는 어떤 어휘 단위는 이름의 역할을 할 수 있습니다. 실제로 목록에서 원하는 제품을 쉽게 검색할 수 있도록 의식적으로 더 잘 인식할 수 있도록 제품 이름을 지정합니다. 간단한 예를 들어 보겠습니다: 공책 구입" 또는 "색연필 세트. 분명히 각 제품은 일반적으로 그 순간에 적합한 단어로 언급됩니다. 즉, 스페이드를 스페이드라고 부릅니다. 계속하세요. Q 요소는 이 특정 지식 생산 모델의 범위를 특징짓습니다. 이러한 영역은 인간의 마음에서 쉽게 구별되므로 원칙적으로 이 요소의 정의에 어려움이 없습니다. 예를 들어 보겠습니다. 다음 상황을 고려해 봅시다. 우리 의식의 한 영역에는 음식을 요리하는 방법에 대한 지식이 저장되어 있고 다른 영역에는 일하는 방법, 세 번째 영역에는 세탁기를 올바르게 작동하는 방법이 저장되어 있다고 가정해 봅시다. 지식 생산 모델의 기억에도 유사한 구분이 존재한다. 이러한 지식을 별도의 영역으로 나누면 현재 필요한 특정 지식 생산 모델을 검색하는 데 소요되는 시간을 크게 절약할 수 있으므로 작업 프로세스가 크게 단순화됩니다. 물론 생산의 주요 요소는 위의 공식에서 A → B로 표시된 소위 코어입니다. 이 공식은 "조건 A가 충족되면 조치 B를 수행해야 한다"로 해석될 수 있습니다. 더 복잡한 커널 구성을 다루는 경우 오른쪽에서 다음과 같은 대안 선택이 허용됩니다. "조건 A가 충족되면 조치 B를 수행해야 합니다.1그렇지 않으면 조치 B를 수행해야 합니다.2". 그러나 지식 생산 모델의 핵심에 대한 해석은 다를 수 있으며 연속 부호 "→"의 왼쪽과 오른쪽에 무엇이 있을지에 따라 달라집니다. 지식의 생산 모델의 핵심에 대한 해석 중 하나를 사용하여 시퀀스는 일반적인 논리적 의미로 해석될 수 있습니다. 진정한 조건 A에서 행동 B의 논리적 결과의 표시로 그럼에도 불구하고 지식 생산 모델의 핵심에 대한 다른 해석도 가능하다. 예를 들어, A는 어떤 조건을 설명할 수 있으며, 그 조건의 이행은 어떤 행동 B가 수행되기 위해 필요합니다. 다음으로, 우리는 지식 R 생산 모델의 요소를 고려합니다. 요소 Р 제품 코어의 적용 가능성에 대한 조건으로 정의됩니다. 조건 P가 참이면 생산 코어가 활성화됩니다. 그렇지 않고 조건 P가 만족되지 않으면, 즉 거짓이면 코어를 활성화할 수 없습니다. 예시로 다음 지식 생산 모델을 고려하십시오. "돈의 가용성"; "물건 A를 사고 싶다면 출납원에게 비용을 지불하고 판매자에게 수표를 제시해야 합니다." 조건 P가 참이면 즉, 구매가 지불되고 수표가 제시되면 코어가 활성화됩니다. 구매가 완료되었습니다. 이 지식 생산 모델에서 핵심 적용 가능성 조건이 거짓이면, 즉 돈이 없으면 지식 생산 모델 핵심을 적용하는 것이 불가능하고 활성화되지 않습니다. 그리고 마지막으로 요소로 이동 N. 요소 N을 프로덕션 데이터 모델의 사후 조건이라고 합니다. 사후 조건은 프로덕션 코어 구현 후 수행해야 하는 조치 및 절차를 정의합니다. 더 나은 인식을 위해 간단한 예를 들어 보겠습니다. 상점에서 물건을 구입 한 후이 상점의 상품 재고에서 이러한 유형의 물건 수를 하나씩 줄여야합니다. 구매가 이루어지면 (따라서 , 코어가 판매됨) 상점에는이 특정 제품이 한 단위 적습니다. 따라서 사후 조건은 "구매한 항목의 단위를 지우십시오"입니다. 요약하면 지식을 일련의 규칙으로 표현하는 것, 즉 지식의 생산 모델을 사용하는 것은 다음과 같은 이점이 있다고 말할 수 있습니다. 1) 개별 규칙을 만들고 이해하기 쉽다. 2) 논리적 선택 메커니즘의 단순성이다. 그러나 일련의 규칙의 형태로 지식을 표현하는 데 있어서 생산 지식 모델의 적용 범위와 빈도를 여전히 제한하는 단점도 있습니다. 이러한 주요 단점은 지식의 특정 생산 모델을 구성하는 규칙과 논리적 선택 규칙 간의 상호 관계가 모호하다는 것입니다. 참고 사항 1. 책의 인쇄본에서 밑줄이 그어진 글꼴은 다음과 같습니다. 굵은 기울임꼴 책의 이 (전자) 버전에서. (대략. e. 에드.)
정원의 꽃을 솎아내는 기계
02.05.2024 고급 적외선 현미경
02.05.2024 곤충용 에어트랩
01.05.2024
▪ 타이어 카보런덤
▪ 기사 오렌지가 처음 등장한 곳은 어디입니까? 자세한 답변 ▪ 기사 Retroclock. 무선 전자 및 전기 공학 백과사전 ▪ 기사 Siemens C62 케이블의 구성표, 핀아웃(핀아웃). 무선 전자 및 전기 공학 백과사전
홈페이지 | 도서관 | 조항 | 사이트 맵 | 사이트 리뷰
www.diagram.com.ua |



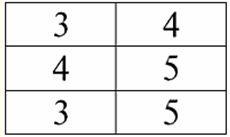
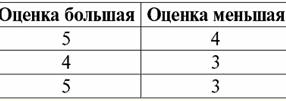

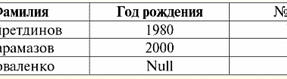

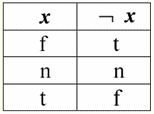

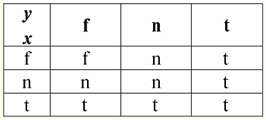
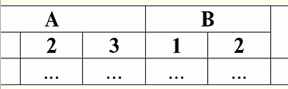


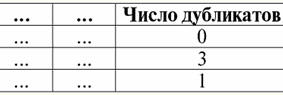






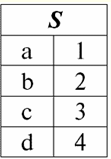
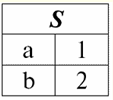

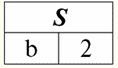
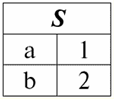

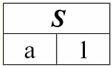
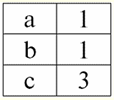

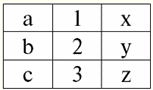









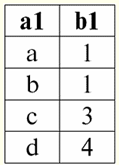






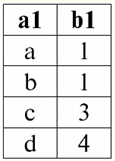



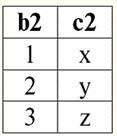

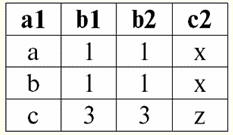




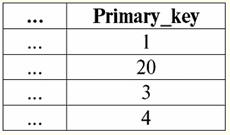

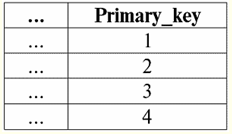

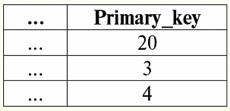
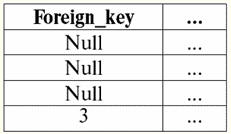

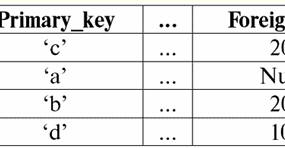











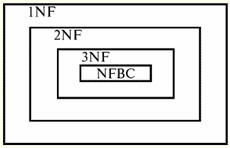

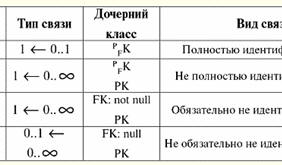



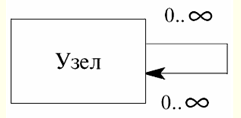







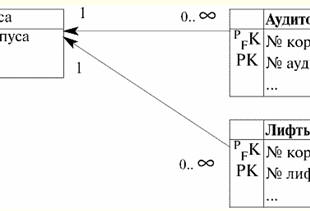




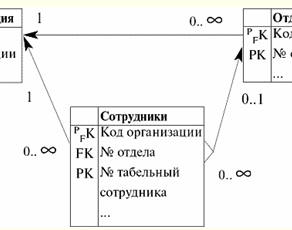
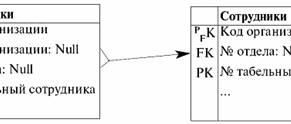
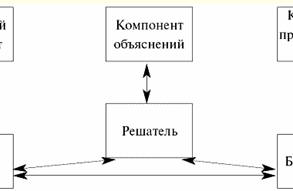
 다른 기사 보기 섹션
다른 기사 보기 섹션 