|
|






 Arabic
Arabic Bengali
Bengali Chinese
Chinese English
English French
French German
German Hebrew
Hebrew Hindi
Hindi Italian
Italian Japanese
Japanese Korean
Korean Malay
Malay Polish
Polish Portuguese
Portuguese Spanish
Spanish Turkish
Turkish Ukrainian
Ukrainian Vietnamese
Vietnamese|
강의 요약, 유아용 침대
정보학 및 정보 기술. 치트 시트: 간략하게, 가장 중요한
차례
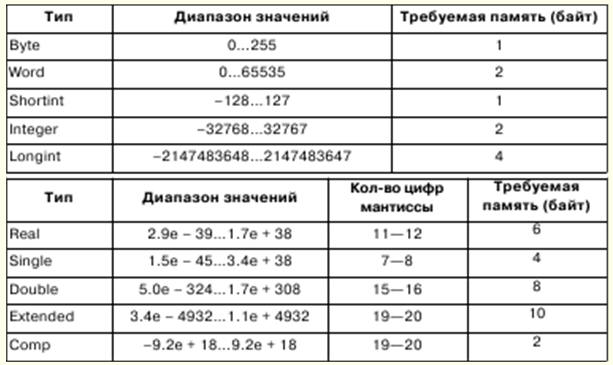
1. 컴퓨터 과학. 정보 대표 및 처리 / 정보. 숫자 체계 정보학은 과학, 기술 및 생산의 다양한 분야에서 개체 및 관계 구조의 형식화된 표현에 종사하고 있습니다. 다양한 형식 도구는 논리 공식, 데이터 구조, 프로그래밍 언어 등과 같은 객체 및 현상을 모델링하는 데 사용됩니다. 컴퓨터 과학에서 정보와 같은 기본 개념은 다양한 의미를 갖습니다. 1) 외부 형태의 정보에 대한 공식적인 표현 2) 정보의 추상적 의미, 내부 내용, 의미론; 3) 현실 세계에 대한 정보의 관계. 그러나 일반적으로 정보는 추상적 의미인 의미론으로 이해됩니다. 정보를 교환하려면 해석의 정확성이 침해되지 않도록 일관된 관점이 필요합니다. 이를 위해 정보 표현의 해석은 일부 수학적 구조로 식별됩니다. 이 경우 엄격한 수학적 방법으로 정보 처리를 수행할 수 있습니다. 정보에 대한 수학적 설명 중 하나는 정보를 함수로 표현하는 것입니다. y = 에프(엑스,티) 여기서 t는 시간이고, x는 y 값이 측정되는 일부 필드의 한 점입니다. 기능 매개변수 x 및 t에 따라 정보를 분류할 수 있습니다. 매개변수가 연속적인 값을 취하는 스칼라 양인 경우 이러한 방식으로 얻은 정보를 연속(또는 아날로그)이라고 합니다. 매개변수에 특정 변경 단계가 주어지면 정보를 이산이라고 합니다. 개별 정보는 보편적인 것으로 간주됩니다. 이산 정보는 일반적으로 디지털 정보로 식별되며, 이는 알파벳 표현의 기호 정보의 특수한 경우입니다. 알파벳은 모든 성격의 유한한 기호 집합입니다. 컴퓨터 과학에서는 인코딩 작업을 수행하기 위해 한 알파벳의 문자를 다른 알파벳의 문자로 나타내야 하는 상황이 매우 자주 발생합니다. 실습에서 알 수 있듯이 다른 알파벳을 인코딩할 수 있는 가장 간단한 알파벳은 이진 문자로, 일반적으로 0과 1로 표시되는 두 개의 문자로 구성됩니다. 이진 알파벳의 n 문자를 사용하여 2n 문자를 인코딩할 수 있으며 이것으로 충분합니다. 모든 알파벳을 인코딩합니다. 이진 알파벳의 기호로 나타낼 수 있는 값을 정보 또는 비트의 최소 단위라고 합니다. 8비트 시퀀스 - 바이트. 256개의 서로 다른 8비트 시퀀스를 포함하는 알파벳을 바이트 알파벳이라고 합니다. 숫자 체계는 숫자를 명명하고 쓰기 위한 일련의 규칙입니다. 위치 및 비 위치 번호 시스템이 있습니다. 숫자의 숫자 값이 숫자의 숫자 위치에 따라 달라지는 경우 숫자 체계를 위치 지정이라고 합니다. 그렇지 않으면 비포지셔닝이라고 합니다. 숫자의 값은 숫자에서 이러한 숫자의 위치에 따라 결정됩니다. 2. 컴퓨터에서 숫자 표현. 알고리즘의 공식화된 개념 32비트 프로세서는 최대 232-1개의 RAM에서 작동할 수 있으며 주소는 00000000 - FFFFFFFF 범위에서 쓸 수 있습니다. 그러나 리얼 모드에서 프로세서는 최대 220-1의 메모리로 작동하며 주소는 00000 - FFFFF 범위에 속합니다. 메모리 바이트는 고정 및 가변 길이의 필드로 결합될 수 있습니다. 워드는 2바이트로 구성된 고정 길이 필드이고, 더블 워드는 4바이트 필드입니다. 필드 주소는 짝수 또는 홀수일 수 있으며 짝수 주소가 더 빠릅니다. 고정 소수점 숫자는 컴퓨터에서 정수 이진수로 표시되며 크기는 1, 2 또는 4바이트일 수 있습니다. 정수 이진수는 XNUMX의 보수로 표현됩니다. 양수의 보수 코드는 숫자 자체와 같고 음수의 보수 코드는 다음 공식을 사용하여 얻을 수 있습니다. x = 10n - \x\, 여기서 n은 숫자의 비트 깊이입니다. 이진수 시스템에서 비트를 반전하여 추가 코드를 얻습니다. 즉, 단위를 XNUMX으로 또는 그 반대로 바꾸고 최하위 비트에 XNUMX을 더합니다. 가수의 비트 수는 숫자 표현의 정밀도를 결정하고 기계 순서 비트 수는 부동 소수점 숫자의 표현 범위를 결정합니다. 알고리즘의 공식화된 개념 알고리즘은 동시에 어떤 수학적 대상이 존재하는 경우에만 존재할 수 있습니다. 알고리즘의 형식화된 개념은 재귀 함수, 일반 마르코프 알고리즘, 튜링 기계의 개념과 연결됩니다. 수학에서 어떤 인수 집합에 대해 함수의 고유한 값이 결정되는 법칙이 있는 경우 함수를 단일 값이라고 합니다. 알고리즘은 그러한 법칙처럼 작용할 수 있습니다. 이 경우 함수는 계산 가능하다고 합니다. 재귀 함수는 계산 가능한 함수의 하위 클래스이며 계산을 정의하는 알고리즘을 컴패니언 재귀 함수 알고리즘이라고 합니다. 첫째, 기본 재귀 함수가 고정되어 수반되는 알고리즘이 사소하고 모호하지 않습니다. 그런 다음 세 가지 규칙(대체, 재귀 및 최소화 연산자)이 도입되며, 이를 통해 기본 기능을 기반으로 더 복잡한 재귀 기능을 얻을 수 있습니다. 기본 기능과 그에 수반되는 알고리즘은 다음과 같습니다. 1) XNUMX과 동일하게 n 독립 변수의 함수. 그런 다음 함수의 부호가 φn이면 인수의 수에 관계없이 함수 값은 XNUMX으로 설정되어야 합니다. 2) Ψ ni 형식의 n 독립 변수의 항등 함수. 그런 다음 함수의 부호가 Ψ ni이면 함수의 값은 왼쪽에서 오른쪽으로 세어 i 번째 인수의 값으로 취해야 합니다. 3) 하나의 독립적인 인수의 λ-함수. 그런 다음 함수의 부호가 λ이면 함수의 값은 인수 값 다음에 오는 값으로 취해야 합니다. 3. 파스칼 언어 소개 언어의 기본 기호(문자, 숫자 및 특수 문자)는 알파벳을 구성합니다. 파스칼 언어에는 다음과 같은 기본 기호 집합이 포함됩니다. 1) 26개의 라틴 소문자 및 26개의 라틴 대문자: 2) _(밑줄); 3) 10자리: 0 1 2 3 4 5 6 7 8 9; 4) 작동 징후: + - O / = <> < > <= >= := @; 5) 구분 기호:., ( ) [ ] (..) { } (* *).. : ; 6) 지정자: ^ # $; 7) 서비스(예약) 단어: ABSOLUTE, ASSEMBLER, AND, ARRAY, ASM, BEGIN, CASE, CONST, CONSTRUCTOR, DESTRUCTOR, DIV, DO, DOWNTO, ELSE, END, EXPORT, EXTERNAL, FAR, FILE, FOR, FORWARD, FUNCTION, GOTO, IF, IMPLEMENTATION, IN, INDEX, Inherited, INLINE, INTERFACE, INTERRUPT, LABEL, LIBRARY, MOD, NAME, NIL, NEAR, NOT, OBJECT, OF, OR, PACKED, PRIVATE, PROCEDURE, 프로그램, 공개, 기록, 반복, 거주자, 설정, SHL, SHR, STRING, THEN, TO, 유형, 단위, UNTIL, USES, VAR, 가상, WHILE, 함께, XOR. 나열된 것 외에도 기본 문자 세트에는 공백이 포함됩니다. 파스칼에는 규칙이 있습니다. 유형은 사용 전에 변수나 함수의 선언에 명시적으로 지정됩니다. Pascal 유형 개념에는 다음과 같은 주요 속성이 있습니다. 1) 모든 데이터 유형은 변수 또는 표현식이 취할 수 있거나 연산이나 함수가 생성할 수 있는 상수가 속하는 값 세트를 정의합니다. 2) 상수, 변수 또는 표현식이 제공하는 값의 유형은 형식이나 설명에 따라 결정될 수 있습니다. 3) 각 연산이나 함수에는 고정 유형 인수가 필요하며 고정 유형 결과를 생성합니다. Pascal에는 스칼라 및 구조화된 데이터 유형이 있습니다. 스칼라 유형에는 표준 유형과 사용자 정의 유형이 있습니다. 표준 유형에는 정수, 실수, 문자, 부울 및 주소 유형이 포함됩니다. 정수 유형은 주어진 컴퓨터에서 허용되는 정수 집합에 의해 값이 실현되는 상수, 변수 및 함수를 정의합니다. 파스칼에는 다음과 같은 연산자 우선 순위가 있습니다.
1) 괄호 안의 계산 2) 기능 값의 계산; 3) 단항 연산; 4) 작업 * / div 모드 및; 5) 연산 + - 또는 xor; 6) 관계 연산 = <> < > <= >=. 4. 표준 절차 및 기능 산술 함수 1. 기능 Abs(X); 매개변수의 절대값을 반환합니다. 2. 기능 ArcTan(X: 확장): 확장; 인수의 아크 탄젠트를 반환합니다. 3. 함수 Exp(X: 실수): 실수; 지수를 반환합니다. 4.Frac(X:실제):실제; 인수의 소수 부분을 반환합니다. 5. 함수 Int(X: 실수): 실수; 인수의 정수 부분을 반환합니다. 6. 함수 Ln(X: 실수): 실수; 실수 유형 표현식 x의 자연 로그(Ln e = 1)를 반환합니다. 7. 기능 파이: 확장; 3.1415926535로 정의된 Pi 값을 반환합니다. 8. 함수 죄(X: 확장): 확장; 인수의 사인을 반환합니다. 9.Function Sqr(X: 확장): 확장; 인수의 제곱을 반환합니다. 10.Function Sqrt(X: 확장): 확장; 인수의 제곱근을 반환합니다. 가치 변환 절차 및 기능 1. 프로시저 Str(X [: 너비 [: 소수점]]; var S); 숫자 X를 문자열 표현으로 변환합니다. 2. 기능 Chr(X:바이트): 문자; ASCII 테이블에서 인덱스 번호 x를 가진 문자를 반환합니다. 3. 기능 높음(X); 매개변수 범위에서 가장 큰 값을 반환합니다. 4.FunctionLow(X); 매개변수 범위에서 가장 작은 값을 반환합니다. 5. 함수 Ord(X): LongInt; 열거형 식의 서수 값을 반환합니다. 6. 함수 라운드(X: 확장): LongInt; 실수 값을 정수로 반올림합니다. 7. 함수 Trunc(X: 확장): LongInt; 실수 유형 값을 정수로 자릅니다. 8. 프로시저 Val(S, var V, var 코드: 정수), 숫자를 문자열 값 S에서 숫자 표현 V로 변환합니다. 서수 값 절차 및 함수 1. 프로시저 Dec(var X [; N: LongInt]); 변수 X에서 XNUMX 또는 N을 뺍니다. 2. 프로시저 Inc(var X [; N: LongInt]); 변수 X에 하나 또는 N을 추가합니다. 3. 함수 Odd(X: LongInt): 부울; X가 홀수이면 True를 반환하고 그렇지 않으면 False를 반환합니다. 4.FunctionPred(X); 매개변수의 이전 값을 반환합니다. 5 함수 Succ(X); 다음 매개변수 값을 반환합니다. 5. 파스칼 언어 연산자 조건 연산자 완전한 조건문의 형식은 다음과 같이 정의됩니다. B이면 S1이면 S2 여기서 B는 분기(의사결정) 조건, 논리식 또는 관계입니다. S1, S2 - 하나의 실행 가능한 명령문, 단순 또는 복합. 조건문을 실행할 때 먼저 표현식 B가 평가된 다음 그 결과가 분석됩니다. B가 true이면 명령문 S1이 실행됩니다. then의 분기 및 명령문 S2는 건너뜁니다. B가 거짓이면 명령문 S2 - else 분기가 실행되고 명령문 S1을 건너뜁니다. 문 선택 연산자 구조는 다음과 같습니다. 케이스 S c1: 지시1; c2: 지시2; ... cn: 명령N; 다른 지시 끝; 여기서 S는 값이 계산되는 서수 유형 표현식입니다. c1, c2,..., on - 표현식 S가 비교되는 순서형 상수입니다. Instructionl,..., InstructionN - 상수가 표현식 S의 값과 일치하는 연산자가 실행되는 연산자입니다. 명령 - 표현식 S의 값이 상수 c1, o2, on과 일치하지 않는 경우 실행되는 연산자입니다. 매개변수가 있는 루프 문 for 문이 실행을 시작하면 시작 값과 끝 값이 한 번 결정되고 이 값은 for 문이 실행되는 동안 유지됩니다. for 문의 본문에 포함된 문은 시작 값과 끝 값 사이의 범위에 있는 각 값에 대해 한 번씩 실행됩니다. 루프 카운터는 항상 초기 값으로 초기화됩니다. 전제 조건이 있는 루프 문 B가 S를 하는 동안; 여기서 B는 논리 조건이며 진실이 확인됩니다(루프를 종료하기 위한 조건)$; S - 루프 본문 - 하나의 명령문. 명령문의 반복을 제어하는 표현식은 부울 유형이어야 합니다. 내부 문이 실행되기 전에 평가됩니다. 표현식이 Trie로 평가되는 한 내부 문은 반복적으로 실행됩니다. 표현식이 처음부터 False로 평가되면 전제 조건 루프 문에 포함된 문이 실행되지 않습니다. 사후 조건이 있는 루프 문 B까지 S를 반복합니다. 여기서 B는 논리 조건이며, 그 진실이 확인됩니다(루프를 종료하기 위한 조건). S - 하나 이상의 루프 본문 문. 표현식의 결과는 부울 유형이어야 합니다. repeat 및 until 키워드 사이에 있는 명령문은 표현식의 결과가 True로 평가될 때까지 순차적으로 실행됩니다. 명령문 시퀀스의 각 실행 후에 표현식이 평가되기 때문에 명령문 시퀀스는 적어도 한 번 실행됩니다. 6. 보조 알고리즘의 개념 문제 해결 알고리즘은 전체 문제를 별도의 하위 작업으로 분해하여 설계되었습니다. 일반적으로 하위 작업은 하위 루틴으로 구현됩니다. 서브루틴은 매개변수라고 하는 일부 들어오는 양의 다른 값을 사용하여 기본 알고리즘에서 반복적으로 사용되는 보조 알고리즘입니다. 프로그래밍 언어의 서브루틴은 프로그램의 한 곳에서만 정의되고 작성된 일련의 명령문이지만 프로그램의 하나 이상의 지점에서 실행을 위해 호출될 수 있습니다. 각 서브루틴은 고유한 이름으로 식별됩니다. 파스칼에는 프로시저와 함수라는 두 가지 유형의 서브루틴이 있습니다. 프로시저와 함수는 선언과 명령문의 명명된 시퀀스입니다. 프로시저 또는 함수를 사용할 때 프로그램은 프로시저 또는 함수의 텍스트와 프로시저 또는 함수에 대한 호출을 포함해야 합니다. 설명에 지정된 매개변수를 형식이라고 하고 서브루틴 호출에 지정된 매개변수를 실제라고 합니다. 모든 형식 매개변수는 다음 범주로 나눌 수 있습니다. 1) 매개변수-변수; 2) 일정한 매개변수; 3) 매개변수 값; 4) 절차 매개변수 및 기능 매개변수, 즉 절차 유형 매개변수; 5) 유형화되지 않은 변수 매개변수. 절차 및 기능에 대한 텍스트는 절차 및 기능에 대한 설명에 있습니다. 프로시저 및 함수 이름을 매개변수로 전달 많은 문제, 특히 계산 수학에서 프로시저와 함수의 이름을 매개변수로 전달하는 것이 필요합니다. 이를 위해 TURBO PASCAL은 기술된 내용에 따라 절차적 또는 기능적이라는 새로운 데이터 유형을 도입했습니다. (절차 및 함수 유형은 유형 선언 섹션에 설명되어 있습니다.) 함수 및 프로시저 형식은 형식 매개변수 목록이 있지만 이름이 없는 프로시저 및 함수의 표제로 정의됩니다. 매개변수 없이 함수 또는 절차 유형을 정의할 수 있습니다. 예를 들면 다음과 같습니다. 유형 절차 = 절차; 절차적 또는 기능적 유형을 선언한 후에는 형식 매개변수(절차 및 함수의 이름)를 설명하는 데 사용할 수 있습니다. 또한 이름이 실제 매개변수로 전달될 실제 프로시저나 함수를 작성해야 합니다. 7. 파스칼의 절차와 기능 파스칼의 절차 절차에 대한 설명은 헤더와 블록으로 구성되며 모듈 연결 부분을 제외하고는 프로그램 블록과 다르지 않습니다. 헤더는 Procedure 키워드, 프로시저 이름, 괄호 안의 선택적 형식 매개변수 목록으로 구성됩니다. 프로시저 <이름> [(<형식 매개변수 목록>)]; 각 형식 매개변수에 대해 해당 유형을 정의해야 합니다. 프로시저 설명의 매개변수 그룹은 세미콜론으로 구분됩니다. 절차의 구조는 프로그램과 거의 완전히 유사합니다. 그러나 프로시저 블록에는 모듈 연결 섹션이 없습니다. 블록은 설명 및 실행의 두 부분으로 구성됩니다. 설명 부분에는 절차 요소에 대한 설명이 포함됩니다. 그리고 실행 부분에서 작업은 필요한 결과를 얻을 수 있도록 절차에 액세스할 수 있는 프로그램 요소(예: 전역 변수 및 상수)로 표시됩니다. 프로시저의 명령어 섹션은 end 키워드가 마침표 대신 세미콜론으로 섹션을 끝낸다는 점에서만 프로그램의 명령어 섹션과 다릅니다. 프로시저 호출 문은 프로시저를 호출하는 데 사용됩니다. 프로시저 이름과 괄호로 묶인 인수 목록으로 구성됩니다. 프로시저가 실행될 때 실행될 명령문은 프로시저 모듈의 명령문 부분에 포함됩니다. 때때로 프로시저가 자신을 호출하기를 원합니다. 이러한 호출 방식을 재귀라고 합니다. 재귀는 주요 작업을 하위 작업으로 나눌 수 있는 경우에 유용하며, 각 하위 작업은 기본 작업과 일치하는 알고리즘에 따라 구현됩니다. 파스칼의 함수 함수 선언은 값이 계산되고 반환되는 프로그램 부분을 정의합니다. 함수 설명은 헤더와 블록으로 구성됩니다. 헤더에는 Function 키워드, 함수 이름, 괄호로 묶인 형식 매개변수의 선택적 목록 및 함수의 반환 유형이 포함됩니다. 함수 헤더의 일반적인 형식은 다음과 같습니다. 함수 <이름> [(<형식 매개변수 목록>)]: <반환 유형>; Turbo Pascal 7.0의 Borland 구현에서 함수의 반환 값은 복합 유형이 될 수 없습니다. 그리고 볼랜드 델파이 통합 개발 환경에서 사용되는 오브젝트 파스칼 언어는 파일 유형을 제외한 모든 유형의 반환 결과를 허용합니다. 기능 블록은 프로시저 블록과 구조가 유사한 로컬 블록입니다. 함수의 본문에는 하나 이상의 할당문이 포함되어야 하며, 왼쪽에 함수의 이름이 있습니다. 함수가 반환하는 값을 결정하는 것은 바로 그녀입니다. 그러한 명령어가 여러 개 있는 경우 함수의 결과는 마지막으로 실행된 할당 명령어의 값이 됩니다. 함수가 호출되면 함수가 활성화됩니다. 함수가 호출되면 함수를 평가하는 데 필요한 함수 식별자와 매개변수가 지정됩니다. 함수 호출은 표현식에 피연산자로 포함될 수 있습니다. 표현식이 평가되면 함수가 실행되고 피연산자의 값은 함수에서 반환된 값이 됩니다. 기능 블록의 연산자 부분은 기능이 활성화될 때 실행되어야 하는 명령문을 지정합니다. 모듈에는 함수 식별자에 값을 할당하는 할당문이 하나 이상 있어야 합니다. 함수의 결과는 할당된 마지막 값입니다. 이러한 할당 문이 없거나 실행되지 않은 경우 함수의 반환 값은 정의되지 않습니다. 모듈 내에서 함수(함수)를 호출할 때 함수 식별자가 사용되면 함수는 재귀적으로 실행됩니다. 8. 서브루틴의 설명과 연결을 전달합니다. 지령 프로그램은 여러 서브루틴을 포함할 수 있습니다. 즉, 프로그램 구조가 복잡할 수 있습니다. 그러나 이러한 서브루틴은 동일한 중첩 수준에 있을 수 있으므로 특별한 전달 선언이 사용되지 않는 한 서브루틴 선언이 먼저 오고 다음에 호출되어야 합니다. 명령문 블록 대신 정방향 지시문을 포함하는 프로시저 선언을 정방향 선언이라고 합니다. 이 선언 이후 어딘가에 정의 선언으로 프로시저를 정의해야 합니다. 정의 선언은 동일한 프로시저 식별자를 사용하지만 형식 매개변수 목록을 생략하고 명령문 블록을 포함하는 선언입니다. 전방 선언과 정의 선언은 프로시저 및 함수 선언의 동일한 부분에 나타나야 합니다. 그들 사이에 전방 선언 절차를 참조할 수 있는 다른 절차와 함수를 선언할 수 있습니다. 따라서 상호 재귀가 가능합니다. 전방 설명 및 정의 설명은 절차에 대한 완전한 설명입니다. 절차는 전방 기술을 사용하여 기술된 것으로 간주됩니다. 프로그램에 상당히 많은 서브루틴이 포함되어 있으면 프로그램이 시각적으로 표시되지 않고 탐색하기 어려울 것입니다. 이를 방지하기 위해 일부 서브루틴은 디스크에 소스 파일로 저장되며, 필요에 따라 컴파일 단계에서 컴파일 지시문을 사용하여 메인 프로그램에 연결됩니다. 지시문은 일반 주석이 있을 수 있는 프로그램의 모든 위치에 배치할 수 있는 특수 주석입니다. 그러나 지시문에 특수 표기법이 있다는 점에서 다릅니다. 공백 없이 닫는 대괄호 바로 뒤에 $ 기호가 쓰여지고 다시 공백 없이 지시문이 표시됩니다. 예 : 1) {$E+} - 수학 보조 프로세서를 에뮬레이트합니다. 2) {$F+} - 호출 프로시저 및 함수의 원거리 유형을 형성합니다. 3) {$N+} - 수학 보조 프로세서를 사용합니다. 4) {$R+} - 범위가 범위를 벗어났는지 확인합니다. 일부 컴파일 스위치에는 다음과 같은 매개변수가 포함될 수 있습니다. {$I file name} - 컴파일된 프로그램의 텍스트에 명명된 파일을 포함합니다. 9. 서브프로그램 매개변수 프로시저 또는 함수에 대한 설명은 형식 매개변수 목록을 지정합니다. 형식 매개변수 목록에 선언된 각 매개변수는 설명되는 프로시저 또는 함수에 대해 지역적이며 식별자에 의해 해당 프로시저 또는 함수와 연관된 모듈에서 참조될 수 있습니다. 매개변수에는 값, 변수 및 유형이 지정되지 않은 변수의 세 가지 유형이 있습니다. 다음과 같은 특징이 있습니다. 1. 선행 키워드가 없는 매개변수 그룹은 값 매개변수 목록입니다. 2. 앞에 const 키워드가 있고 뒤에 유형이 오는 매개변수 그룹은 상수 매개변수 목록입니다. 3. var 키워드가 앞에 오고 유형이 뒤에 오는 매개변수 그룹은 변수 매개변수 목록입니다. 값 매개변수 형식 값 매개변수는 프로시저 또는 함수가 호출될 때 해당 실제 매개변수에서 초기 값을 가져오는 것을 제외하고는 프로시저 또는 함수에 대한 로컬 변수처럼 취급됩니다. 형식 값 매개변수가 수행하는 변경은 실제 매개변수의 값에 영향을 미치지 않습니다. 해당 실제 값 매개변수 값은 표현식이어야 하며 해당 값은 파일 유형 또는 파일 유형을 포함하는 구조 유형이 아니어야 합니다. 실제 매개변수는 형식 값 매개변수의 유형과 할당 호환 가능한 유형이어야 합니다. 매개변수가 문자열 유형이면 형식 매개변수의 크기 속성은 255입니다. 상수 매개변수 서브루틴의 본문에서 상수 매개변수의 값은 변경할 수 없습니다. 매개변수-상수는 서브루틴에서 변경이 바람직하지 않고 금지되어야 하는 매개변수를 정렬하는 데 사용할 수 있습니다. 변수 매개변수 변수 매개변수는 값이 서브루틴에서 호출 블록으로 전달되어야 할 때 사용됩니다. 이 경우 서브루틴이 호출되면 형식 매개변수가 변수 인수로 대체되고 형식 매개변수에 대한 변경 사항이 인수에 반영됩니다. 절차적 변수 절차적 유형을 정의한 후에는 이 유형의 변수를 설명하는 것이 가능해집니다. 이러한 변수를 절차 변수라고 합니다. 정수형 값을 할당할 수 있는 정수 변수와 마찬가지로 절차형 변수에도 절차형 값을 할당할 수 있습니다. 물론 그러한 값은 또 다른 프로시저 변수일 수 있지만 프로시저 또는 함수 식별자일 수도 있습니다. 이 컨텍스트에서 프로시저 또는 함수의 선언은 값이 프로시저 또는 함수인 특수한 종류의 상수에 대한 설명으로 볼 수 있습니다. 다른 할당과 마찬가지로 왼쪽과 오른쪽의 변수 값은 할당 호환 가능해야 합니다. 할당 호환이 되려면 절차 유형의 매개변수 수가 같아야 하며 해당 위치의 매개변수 유형도 동일해야 합니다. 절차 형식 선언의 매개 변수 이름은 영향을 주지 않습니다. 또한 할당 호환성을 보장하기 위해 프로시저 또는 함수가 프로시저 변수에 할당될 경우 표준이거나 중첩되어서는 안 됩니다. 10. 서브루틴 파라미터의 종류 값 매개변수 형식 값 매개변수는 지역 변수로 취급되며 프로시저 또는 함수가 호출될 때 해당 실제 매개변수에서 초기값을 가져옵니다. 형식 값 매개변수가 겪는 변경은 실제 매개변수의 값에 영향을 미치지 않습니다. value 매개변수의 해당 실제 값은 표현식이어야 하며 해당 값은 파일 유형이 아니어야 합니다. 상수 매개변수 형식 상수 매개변수는 프로시저나 함수가 호출될 때 값을 얻습니다. 형식 상수 매개변수에 대한 할당은 허용되지 않습니다. 형식 상수 매개변수는 다른 프로시저나 함수에 실제 매개변수로 전달할 수 없습니다. 변수 매개변수 변수 매개변수는 값이 프로시저나 함수에서 호출 프로그램으로 전달되어야 할 때 사용됩니다. 활성화되면 형식 매개변수 변수가 실제 변수로 대체되고 형식 매개변수 변수에 대한 변경 사항이 실제 매개변수에 반영됩니다. 형식화되지 않은 매개변수 형식 매개변수가 유형이 지정되지 않은 변수 매개변수인 경우 해당 실제 매개변수는 변수 또는 상수 참조가 될 수 있습니다. var 키워드로 선언된 형식화되지 않은 매개변수는 수정할 수 있지만 const 키워드로 선언된 형식화되지 않은 매개변수는 읽기 전용입니다. 절차적 변수 절차적 유형을 정의한 후에는 이 유형의 변수를 설명하는 것이 가능해집니다. 이러한 변수를 절차 변수라고 합니다. 절차 변수에는 절차 유형 값을 할당할 수 있습니다. 할당된 절차 또는 기능은 다음과 같아야 합니다. 1) 표준이 아님; 2) 중첩되지 않음; 3) 인라인 형식의 절차가 아닙니다. 4) 인터럽트 절차에 의한 것이 아닙니다. 절차 유형 매개변수 프로시저 형식은 모든 컨텍스트에서 사용할 수 있으므로 프로시저 및 함수를 매개 변수로 사용하는 프로시저 또는 함수를 설명할 수 있습니다. 프로시저 형식 매개 변수는 여러 프로시저 또는 함수에 대해 몇 가지 일반적인 작업을 수행해야 할 때 특히 유용합니다. 프로시저 또는 함수가 매개변수로 전달되는 경우 할당과 동일한 유형 호환성 규칙을 따라야 합니다. 즉, 이러한 프로시저나 함수는 far 지시문으로 컴파일해야 하고 내장 함수가 될 수 없으며 중첩될 수 없으며 인라인 또는 인터럽트 속성으로 설명할 수 없습니다. 11. 파스칼의 문자열 유형. 문자열 유형 변수에 대한 절차 및 함수 특정 길이의 문자 시퀀스를 문자열이라고 합니다. 문자열 유형의 변수는 변수 이름, 예약어 문자열을 지정하고 선택적으로(반드시 그렇지는 않음) 최대 크기, 즉 문자열 길이를 대괄호 안에 지정하여 정의됩니다. 최대 문자열 크기를 설정하지 않으면 기본적으로 255가 됩니다. 즉, 문자열은 255자로 구성됩니다. 문자열의 각 요소는 해당 번호로 참조할 수 있습니다. 그러나 문자열은 배열의 경우처럼 요소별로가 아니라 전체적으로 입력 및 출력됩니다. 입력한 문자 수는 최대 문자열 크기에 지정된 수를 초과하지 않아야 하므로 이러한 초과가 발생하는 경우 "추가" 문자는 무시됩니다. 문자열 유형 변수에 대한 절차 및 함수 1. 함수 복사(S: 문자열; 인덱스, 개수: 정수): 문자열; 문자열의 하위 문자열을 반환합니다. S는 String 유형의 표현식입니다. Index 및 Count는 정수 유형 표현식입니다. 이 함수는 인덱스 위치에서 시작하는 Count 문자를 포함하는 문자열을 반환합니다. Index가 S의 길이보다 크면 함수는 빈 문자열을 반환합니다. 2. 삭제 절차(var S: String; Index, Count: Integer); 인덱스 위치에서 시작하여 문자열 S에서 길이가 Count인 문자의 하위 문자열을 제거합니다. S는 String 유형의 변수입니다. Index 및 Count는 정수 유형 표현식입니다. Index가 S의 길이보다 크면 문자가 제거되지 않습니다. 3. 프로시저 삽입(소스: 문자열, var S: 문자열, 인덱스: 정수); 지정된 위치에서 시작하여 부분 문자열을 문자열로 연결합니다. 소스는 문자열 유형의 표현식입니다. S는 길이에 관계없이 String 유형의 변수입니다. 인덱스는 정수 유형의 표현식입니다. 삽입은 소스를 S 위치에서 시작하여 S에 삽입합니다. 4. 함수 길이(S: 문자열): 정수; 문자열 S에서 실제로 사용된 문자 수를 반환합니다. null로 끝나는 문자열을 사용할 때 문자 수가 반드시 바이트 수와 같지는 않습니다. 5. 함수 Pos(하위 문자열: 문자열; S: 문자열): 정수; 문자열에서 부분 문자열을 검색합니다. Pos는 S 내부에서 Substr을 찾습니다. S 내에서 Substr의 첫 번째 문자 인덱스인 정수 값을 반환합니다. Substr을 찾을 수 없으면 Pos는 XNUMX을 반환합니다. 12. 녹음 레코드는 서로 다른 유형에 속하는 제한된 수의 논리적으로 관련된 구성 요소의 모음입니다. 레코드의 구성 요소를 필드라고 하며 각 구성 요소는 이름으로 식별됩니다. 레코드 필드에는 필드 이름과 필드 유형을 나타내는 콜론이 뒤따릅니다. 레코드 필드는 파일 유형을 제외하고 Pascal에서 허용되는 모든 유형이 될 수 있습니다. 파스칼 언어로 된 레코드에 대한 설명은 서비스 단어 RECORD를 사용하여 수행되고 그 뒤에 레코드의 구성 요소에 대한 설명이 따라옵니다. 항목에 대한 설명은 서비스 단어 END로 끝납니다. 예를 들어 노트북에는 성, 이니셜, 전화번호가 포함되어 있으므로 노트북에서 별도의 줄을 다음 항목으로 나타내는 것이 편리합니다. 유형 행 = 레코드 FIO: 문자열[20]; 전화: 문자열[7]; 끝; var str: 행; 유형 이름을 사용하지 않고 레코드 설명도 가능합니다. 예를 들면 다음과 같습니다. var str: 레코드 FIO: 문자열[20]; 전화: 문자열[7]; 끝; 레코드 전체를 참조하는 것은 할당 기호의 왼쪽과 오른쪽에 동일한 유형의 레코드 이름이 사용되는 할당문에서만 허용됩니다. 다른 모든 경우에는 별도의 기록 필드가 운영됩니다. 개별 레코드 구성 요소를 참조하려면 레코드 이름을 지정하고 점으로 구분하여 원하는 필드의 이름을 지정해야 합니다. 이러한 이름을 복합 이름이라고 합니다. 레코드 구성 요소는 레코드가 될 수도 있습니다. 이 경우 고유 이름에는 두 개가 아닌 더 많은 이름이 포함됩니다. with 추가 연산자를 사용하여 참조 레코드 구성 요소를 단순화할 수 있습니다. 이를 통해 각 필드를 특징짓는 복합 이름을 필드 이름으로 바꾸고 조인 문에서 레코드 이름을 정의할 수 있습니다. 때때로 개별 레코드의 내용은 해당 필드 중 하나의 값에 따라 다릅니다. Pascal 언어에서는 공통 부분과 변형 부분으로 구성된 레코드 설명이 허용됩니다. 변형 부분은 구조의 대소문자 P를 사용하여 지정됩니다. 여기서 P는 레코드의 공통 부분에 있는 필드 이름입니다. 이 필드에서 허용되는 가능한 값은 변형 문과 동일한 방식으로 나열됩니다. 그러나 변형 문에서와 같이 수행할 작업을 지정하는 대신 변형 필드가 괄호 안에 지정됩니다. 변형 부품에 대한 설명은 서비스 단어 end로 끝납니다. 필드 유형 P는 변형 부품의 제목에 지정할 수 있습니다. 레코드는 유형이 지정된 상수를 사용하여 초기화됩니다. 13. 세트 파스칼 언어에서 집합의 개념은 집합의 수학적 개념을 기반으로 합니다. 다른 요소의 제한된 모음입니다. 열거형 또는 간격 데이터 형식은 구체적인 집합 형식을 구성하는 데 사용됩니다. 집합을 구성하는 요소의 유형을 기본 유형이라고 합니다. 다중 유형은 기능 단어 세트를 사용하여 설명됩니다. 예를 들면 다음과 같습니다. 유형 M = B 세트; 여기서 M은 복수형이고 B는 기본 유형입니다. 복수형에 대한 변수의 소속은 변수 선언 섹션에서 직접 결정할 수 있습니다. 집합 유형 상수는 쉼표로 구분된 기본 유형의 요소 또는 범위의 대괄호 시퀀스로 작성됩니다. 대입(:=), 합집합(+), 교집합(*), 빼기(-) 연산은 집합 유형의 변수와 상수에 적용할 수 있습니다. 이러한 작업의 결과는 복수 유형의 값입니다. 1) ['A','B'] + ['A','D']는 ['A','B','D']를 줄 것입니다. 2) ['A'] * ['A','B','C']는 ['A']를 줄 것입니다. 3) ['A','B','C'] - ['A','B']는 ['C'] 다음 작업은 여러 값에 적용할 수 있습니다. 동일성(=), 비 동일성(<>), 포함(<=), 포함(>=). 이러한 작업의 결과에는 부울 유형이 있습니다. 1) ['A','B'] = ['A','C']는 FALSE를 제공합니다. 2) ['A','B'] <> ['A','C']는 TRUE를 제공합니다. 3) ['B'] <= ['B','C']는 TRUE를 제공합니다. 4) ['C','D'] >= ['A']는 FALSE를 제공합니다. 이러한 연산 외에도 집합 유형의 값으로 작업하기 위해 연산 기호 왼쪽에 있는 기본 유형의 요소가 연산 기호 오른쪽에 있는 집합에 속하는지 확인하는 in 연산이 사용됩니다. . 이 작업의 결과는 부울입니다. 여러 유형의 값은 I/O 목록의 요소가 될 수 없습니다. Pascal 언어에서 컴파일러를 구체적으로 구현할 때마다 집합이 빌드되는 기본 유형의 요소 수가 제한됩니다. 14. 파일. 파일 작업 파일 데이터 유형은 동일한 유형의 구성 요소에 대한 정렬된 컬렉션을 정의합니다. 파일 작업 시 I/O 작업이 수행됩니다. 입력 작업은 외부 장치에서 메모리로 데이터를 전송하는 것이고 출력 작업은 메모리에서 외부 장치로 데이터를 전송하는 것입니다. 텍스트 파일 이러한 파일을 설명하기 위해 Text 유형이 있습니다. var TF1, TF2: 텍스트; 구성 요소 파일 구성 요소 또는 유형이 지정된 파일은 해당 구성 요소의 유형이 선언된 파일입니다. 유형 M = T의 파일; 여기서 M은 파일 형식의 이름입니다. T - 구성 요소 유형. 작업은 절차를 사용하여 수행됩니다. 쓰기(f, X1,X2,...XK) 형식이 지정되지 않은 파일 형식이 지정되지 않은 파일을 사용하면 컴퓨터 메모리의 임의 섹션을 디스크에 쓰고 읽을 수 있습니다. var f: 파일; 1. 프로시저 할당(var F; 파일 이름: 문자열); 파일 이름을 변수에 매핑합니다. 2. 절차 닫기(varF); 파일 변수와 외부 디스크 파일 간의 연결을 끊고 파일을 닫습니다. 3. 함수 Eof(var F): 부울; {유형 또는 유형이 지정되지 않은 파일} 함수 Eof[(var F: Text)]: 부울; {텍스트 파일} 파일의 끝을 확인합니다. 4. 절차 지우기(var F); F와 연결된 외부 파일을 삭제합니다. 5. 함수 FileSize(var F): 정수; 파일 F의 크기를 바이트 단위로 반환합니다. 6. 함수 FilePos(varF): LongInt; 파일 내의 현재 위치를 반환합니다. 7. 프로시저 재설정(var F [: 파일; RecSize: Word]); 기존 파일을 엽니다. 8. 프로시저 Rewrite(var F: File [; Recsize: Word]); 새 파일을 만들고 엽니다. 9. 프로시저 Seek(var F; N: LongInt); 현재 파일 위치를 지정된 구성 요소로 이동합니다. 10. 프로시저 Append(var F: Text); 덧셈. 11. 함수 Eoln[(var F: Text)]: Boolean; 문자열의 끝을 확인합니다. 12. 절차 읽기(F, V1 [, V2..., Vn]); {유형이 지정된 파일과 유형이 지정되지 않은 파일} 프로시저 읽기([var F: Text;] V1 [, V2..., Vn]); {텍스트 파일} 파일 구성 요소를 변수로 읽습니다. 13. 절차 Readln([var F: Text;] V1 [, V2..., Vn]); 줄 끝 표시자를 포함하여 파일의 문자 줄을 읽고 다음 줄의 시작 부분으로 이동합니다. 14. 함수 SeekEof[(var F: Text)]: 부울; 파일 끝 기호를 반환합니다. 열린 텍스트 파일에만 사용됩니다. 15. 절차 Writeln([var F: Text;] [P1, P2..., Pn]); {텍스트 파일} 쓰기 작업을 수행한 다음 파일에 줄 끝 마커를 배치합니다. 15. 모듈. 모듈 유형 파스칼의 단위(UNIT)는 특별히 설계된 서브루틴 라이브러리입니다. 모듈은 프로그램과 달리 자체적으로 시작할 수 없으며 프로그램 및 기타 모듈 구축에만 참여할 수 있습니다. Pascal의 모듈은 별도로 저장되고 독립적으로 컴파일된 프로그램 단위입니다. 모듈의 모든 프로그램 요소는 두 부분으로 나눌 수 있습니다. 1) 다른 프로그램이나 모듈에서 사용하도록 의도된 프로그램 요소, 이러한 요소는 모듈 외부에서 볼 수 있다고 합니다. 2) 모듈 자체의 작동에만 필요한 소프트웨어 요소를 보이지 않는(또는 숨겨진)라고 합니다. 단위 <모듈 이름>; {모듈 제목} 인터페이스 {모듈의 보이는 프로그램 요소에 대한 설명} 이행 {모듈의 숨겨진 프로그래밍 요소에 대한 설명} 시작하다 {모듈 요소 초기화 문} 끝. 모듈에서 선언된 변수를 참조하려면 모듈 이름과 변수 이름으로 구성된 복합 이름을 점으로 구분하여 사용해야 합니다. 모듈을 재귀적으로 사용하는 것은 금지되어 있습니다. 모듈의 유형을 나열해 보겠습니다. 1. 시스템 모듈. SYSTEM 모듈은 I/O, 문자열 조작, 부동 소수점 연산 및 동적 메모리 할당과 같은 모든 내장 기능에 대한 하위 수준 지원 루틴을 구현합니다. 2. DOS 모듈. Dos 모듈은 GetTime, SetTime, DiskSize 등과 같이 가장 일반적으로 사용되는 DOS 호출에 해당하는 수많은 Pascal 루틴 및 기능을 구현합니다. 3. CRT 모듈. CRT 모듈은 화면 모드 제어, 확장된 키보드 코드, 색상, 창 및 소리와 같은 PC 기능에 대한 완전한 제어를 제공하는 여러 강력한 프로그램을 구현합니다. 4. 그래프 모듈. 이 모듈에 포함된 절차와 기능을 이용하여 화면에 다양한 그래픽을 생성할 수 있습니다. 5. 오버레이 모듈. OVERLAY 모듈을 사용하면 리얼 모드 DOS 프로그램의 메모리 요구 사항을 줄일 수 있습니다. 16. 참조 데이터 유형. 동적 메모리. 동적 변수. 동적 메모리 작업 정적 변수(정적으로 할당된)는 프로그램에서 명시적으로 선언된 변수이며 이름으로 참조됩니다. 정적 변수를 배치하기 위한 메모리의 위치는 프로그램이 컴파일될 때 결정됩니다. 이러한 정적 변수와 달리 Pascal 프로그램은 동적 변수를 생성할 수 있습니다. 동적 변수의 주요 속성은 프로그램 실행 중에 생성되고 메모리가 할당된다는 것입니다. 동적 변수는 동적 메모리 영역(힙 영역)에 배치됩니다. 동적 변수는 변수 선언에 명시적으로 지정되지 않으며 이름으로 참조할 수 없습니다. 이러한 변수는 포인터와 참조를 사용하여 액세스됩니다. 참조 유형(포인터)은 기본 유형이라고 하는 특정 유형의 동적 변수를 가리키는 값 집합을 정의합니다. 참조 유형 변수는 메모리에 있는 동적 변수의 주소를 포함합니다. 기본 유형이 선언되지 않은 식별자인 경우 포인터 유형과 동일한 유형 선언 부분에서 선언해야 합니다. 예약어 nil은 아무 것도 가리키지 않는 포인터 값을 가진 상수를 나타냅니다. 동적 변수에 대한 설명의 예를 들어 보겠습니다. var p1, p2: ^실제; p3, p4: ^정수; ... 동적 메모리 프로시저 및 함수 1. 새 절차{var p: 포인터). 동적 변수 p"를 수용하기 위해 동적 메모리 영역에 공간을 할당하고 해당 주소를 포인터 p에 할당합니다. 2. 프로시저 Dispose(var p: 포인터). New 프로시저에 의해 동적 변수 할당을 위해 할당된 메모리를 해제하고 포인터 p의 값은 정의되지 않습니다. 3. 프로시저 GetMem(var p: 포인터, 크기: 워드). 힙 영역에 메모리 섹션을 할당하고 시작 주소를 p 포인터에 할당하며 섹션 크기(바이트)는 size 매개변수에 의해 지정됩니다. 4. 프로시저 FreeMem(varp: 포인터, 크기: 워드). 시작 주소가 p 포인터로 지정되고 크기가 size 매개변수로 지정되는 메모리 영역을 해제합니다. 포인터 값 p는 정의되지 않습니다. 5. Mark{var p: Pointer) 프로시저는 호출 시 사용 가능한 동적 메모리 섹션의 시작 주소를 포인터 p에 씁니다. 6. Release(var p: Pointer) 프로시저는 Mark 프로시저에 의해 포인터 p에 기록된 주소에서 시작하여 동적 메모리 섹션을 해제합니다. 즉, Mark 프로시저를 호출한 후 점유되었던 동적 메모리를 지웁니다. 7. 함수 MaxAvail: Longint는 동적 메모리의 가장 긴 여유 공간의 길이를 바이트 단위로 반환합니다. 8. 함수 MemAvail: Longint는 사용 가능한 동적 메모리의 총량을 바이트 단위로 반환합니다. 9. SizeOf(X):Word 도우미 함수는 X가 차지하는 크기(바이트)를 반환합니다. 여기서 X는 모든 유형의 변수 이름 또는 유형 이름일 수 있습니다. 17. 추상 데이터 구조 배열, 집합 및 레코드와 같은 구조화된 데이터 유형은 프로그램이 전체 실행되는 동안 크기가 변경되지 않기 때문에 정적 구조입니다. 데이터 구조는 문제를 해결하는 과정에서 크기를 변경해야 하는 경우가 많습니다. 이러한 데이터 구조를 동적이라고 합니다. 여기에는 스택, 대기열, 목록, 트리 등이 포함됩니다. 배열, 레코드 및 파일을 사용한 동적 구조의 설명은 컴퓨터 메모리의 낭비를 초래하고 문제 해결 시간을 증가시킵니다. 모든 동적 구조의 각 구성 요소는 "포인터" 유형의 필드 하나와 데이터 배치용 필드 등 최소 두 개의 필드를 포함하는 레코드입니다. 일반적으로 레코드에는 하나가 아니라 여러 포인터와 여러 데이터 필드가 포함될 수 있습니다. 데이터 필드는 변수, 배열, 집합 또는 레코드일 수 있습니다. 포인팅 부분에 목록의 한 요소 주소가 포함되어 있으면 목록을 단방향(또는 단일 연결)이라고 합니다. 두 개의 구성 요소가 포함되어 있으면 이중으로 연결됩니다. 목록에서 다음과 같은 다양한 작업을 수행할 수 있습니다. 1) 목록에 요소 추가 2) 주어진 키를 사용하여 목록에서 요소를 제거합니다. 3) 키 필드의 주어진 값으로 요소를 검색합니다. 4) 목록의 요소를 정렬합니다. 5) 목록을 둘 이상의 목록으로 나누는 것 6) 둘 이상의 목록을 하나로 결합하는 것; 7) 기타 작업. 그러나 일반적으로 다양한 문제를 해결하기 위한 모든 작업의 필요성은 발생하지 않습니다. 따라서 적용해야 하는 기본 작업에 따라 다양한 유형의 목록이 있습니다. 이들 중 가장 인기 있는 것은 스택과 큐입니다. 18. 스택 스택은 스택의 맨 위라고 하는 한쪽 끝에서 구성 요소를 추가하고 제거하는 동적 데이터 구조입니다. 스택은 LIFO(후입선출) - "후입선출"의 원칙에 따라 작동합니다. 일반적으로 스택에는 세 가지 작업이 수행됩니다. 1) 스택의 초기 형성(첫 번째 구성 요소의 기록); 2) 스택에 컴포넌트를 추가하는 단계; 3) 구성 요소 선택(삭제). 스택을 형성하고 작업하려면 "포인터" 유형의 두 변수가 있어야 합니다. 첫 번째 변수는 스택의 맨 위를 결정하고 두 번째 변수는 보조입니다. 예시. 스택을 형성하고 임의의 수의 구성 요소를 추가한 다음 모든 구성 요소를 읽는 프로그램을 작성하십시오. 프로그램 스택; Crt를 사용합니다. 유형 알파 = 문자열[10]; PComp = ^Comp; Comp = 레코드 SD: 알파; pNext: 피컴 끝; 였다 pTop:PComp; sc: 알파; 프로시저 스택 생성(var pTop: PComp; var sC: Alfa); 시작하다 신규(pTop); pTop^.pNext:= 없음; pTop^.sD:= sC; 끝; 추가 ProcedureComp(var pTop: PComp; var sC: Alfa); var pAux: PComp; 시작하다 신규(보조); pAux^.pNext:= pTop; pTop:=pAux; pTop^.sD:= sC; 끝; 절차 DelComp(var pTop: PComp; var sC: ALFA); 시작하다 sC:= pTop^.sD; pTop:= pTop^.pNext; 끝; 시작하다 Clrscr; writeln( 문자열 입력 ); readln(sC); CreateStack(pTop, sc); 반복 writeln( 문자열 입력 ); readln(sC); AddComp(pTop, sc); sC = '종료'까지; 19. 대기열 큐는 한 쪽 끝에서 구성 요소가 추가되고 다른 쪽 끝에서 검색되는 동적 데이터 구조입니다. 대기열은 FIFO(선입선출) - "선입선출" 원칙에 따라 작동합니다. 예시. 큐를 구성하고 임의의 수의 구성 요소를 추가한 다음 모든 구성 요소를 읽는 프로그램을 작성하십시오. 프로그램 대기열; Crt를 사용합니다. 유형 알파 = 문자열[10]; PComp = ^Comp; Comp = 레코드 SD: 알파; p다음:PComp; 끝; 였다 pBegin, pEnd: PComp; sc: 알파; Create ProcedureQueue(var pBegin,pEnd: PComp; var sc: 알파); 시작하다 신규(pBegin); pBegin^.pNext:= NIL; pBegin^.sD:= sC; pEnd:=p시작; 끝; 프로시저 AddQueue(var pEnd: PComp; var sC: 알파); var pAux: PComp; 시작하다 신규(pAux); pAux^.p다음:= NIL; pEnd^.pNext:= pAux; pEnd:= pAux; pEnd^.sD:= sC; 끝; 프로시저 DelQueue(var pBegin: PComp; var sC: 알파); 시작하다 sC:=p시작^.sD; pBegin:= pBegin^.pNext; 끝; 시작하다 Clrscr; writeln( 문자열 입력 ); readln(sC); CreateQueue(pBegin, pEnd, sc); 반복 writeln( 문자열 입력 ); readln(sC); AddQueue(pEnd, sc); sC = '종료'까지; 20. 트리 데이터 구조 트리와 같은 데이터 구조는 소스와 생성된 사이의 연결인 관계가 있는 유한한 요소 노드 집합입니다. N. Wirth가 제안한 재귀적 정의를 사용하면 기본 유형이 t인 트리 데이터 구조는 빈 구조이거나 하위 트리라고 하는 기본 유형이 t인 트리 구조의 유한 집합이 있는 유형 t의 노드입니다. 관련된. 다음으로 트리 구조로 작업할 때 사용되는 정의를 제공합니다. 노드 y가 노드 x 바로 아래에 위치하면 노드 y는 노드 x의 직계 후손이라고 하며 x는 노드 y의 직계 조상입니다. 즉, 노드 x가 i 번째 수준에 있으면 노드 y는 그에 따라 (i + 1 ) - 번째 수준에 위치합니다. 트리 노드의 최대 레벨을 트리의 높이 또는 깊이라고 합니다. 조상에는 트리의 노드가 하나만 있는 것이 아닙니다. 바로 루트입니다. 자식이 없는 트리 노드를 리프 노드(또는 트리의 리프)라고 합니다. 다른 모든 노드를 내부 노드라고 합니다. 노드의 직계 자식 수는 해당 노드의 정도를 결정하고 주어진 트리에서 노드의 가능한 최대 차수는 트리의 정도를 결정합니다. 조상과 후손은 서로 바꿀 수 없습니다. 즉, 원본과 생성된 것 사이의 연결은 한 방향으로만 작용합니다. 트리의 루트에서 특정 노드로 이동하면 이 경우에 통과할 트리의 분기 수를 이 노드의 경로 길이라고 합니다. 트리의 모든 가지(노드)가 정렬되면 트리를 정렬이라고 합니다. 이진 트리는 트리 구조의 특별한 경우입니다. 이들은 각 자식이 왼쪽 및 오른쪽 하위 트리라고 하는 최대 두 개의 자식을 갖는 트리입니다. 따라서 이진 트리는 차수가 XNUMX인 트리 구조입니다. 이진 트리의 순서는 다음 규칙에 따라 결정됩니다. 각 노드에는 고유한 키 필드가 있으며 각 노드에 대해 키 값은 왼쪽 하위 트리의 모든 키보다 크고 오른쪽 하위 트리의 모든 키보다 작습니다. 차수가 XNUMX보다 큰 나무를 강한 가지라고 합니다. 21. 나무에 대한 작업 또한 이진 트리와 관련된 모든 작업을 고려할 것입니다. I. 나무 만들기. 정렬된 트리를 구성하는 알고리즘을 제시합니다. 1. 트리가 비어 있으면 데이터가 트리의 루트로 전송됩니다. 트리가 비어 있지 않으면 트리의 순서가 위반되지 않는 방식으로 분기 중 하나가 내려갑니다. 결과적으로 새 노드는 트리의 다음 리프가 됩니다. 2. 이미 존재하는 트리에 노드를 추가하려면 위의 알고리즘을 사용할 수 있습니다. 3. 트리에서 노드를 삭제할 때 주의해야 합니다. 제거할 노드가 리프이거나 자식이 하나만 있는 경우 작업은 간단합니다. 삭제할 노드에 두 개의 자손이 있는 경우 해당 노드를 해당 위치에 넣을 수 있는 노드를 자손 중에서 찾아야 합니다. 이것은 트리를 주문해야 하기 때문에 필요합니다. 다음과 같이 할 수 있습니다. 제거할 노드를 왼쪽 하위 트리에서 가장 큰 키 값을 가진 노드 또는 오른쪽 하위 트리에서 가장 작은 키 값을 가진 노드로 교체한 다음 원하는 노드를 리프로 삭제합니다. Ⅱ. 주어진 키 필드 값으로 노드를 검색합니다. 이 작업을 수행할 때 트리를 횡단해야 합니다. 접두사, 중위사, 접미사 등 다양한 트리 작성 형식을 고려해야 합니다. 문제가 발생합니다. 가장 편리하게 작업할 수 있도록 트리의 노드를 표현하는 방법은 무엇입니까? 배열을 사용하여 트리를 표현하는 것이 가능하며, 각 노드는 문자 유형 정보 필드와 두 개의 참조 유형 필드가 있는 결합된 유형 값으로 설명됩니다. 그러나 이것은 트리가 미리 결정되지 않은 많은 수의 노드를 가지고 있기 때문에 그리 편리하지 않습니다. 따라서 트리를 설명할 때는 동적 변수를 사용하는 것이 가장 좋습니다. 그런 다음 각 노드는 주어진 수의 정보 필드에 대한 설명을 포함하는 동일한 유형의 값으로 표시되며 해당 필드의 수는 트리의 차수와 같아야 합니다. 참조 nil로 자손의 부재를 정의하는 것은 논리적입니다. 그런 다음 Pascal에서 이진 트리에 대한 설명은 다음과 같을 수 있습니다. 유형 TreeLink = ^트리; 나무 = 기록; 정보: <데이터 유형>; 왼쪽, 오른쪽: TreeLink; 끝. 22. 작업 구현의 예 1. 최소 높이의 XNUMX개 노드로 구성된 트리 또는 완벽하게 균형 잡힌 트리를 구성합니다(이러한 트리의 왼쪽 및 오른쪽 하위 트리의 노드 수는 XNUMX개 이하이어야 함). 재귀 생성 알고리즘: 1) 첫 번째 노드는 트리의 루트로 간주됩니다. 2) nl 노드의 왼쪽 하위 트리가 같은 방식으로 구축됩니다. 3) nr개 노드의 오른쪽 하위 트리가 같은 방식으로 구축됩니다. nr = n - nl - 1 정보 필드로 키보드에서 입력한 노드 번호를 가져옵니다. 이 구성을 구현하는 재귀 함수는 다음과 같습니다. 함수 트리(n: 바이트): TreeLink; 바트: TreeLink; nl,nr,x: 바이트; 시작 n = 0이면 Tree:= nil 다른 시작 nl:= n div 2; nr = n - nl - 1; writeln('꼭짓점 번호를 입력하세요); readln(x); 영원); t^.inf:= x; t^.left:= 나무(nl); t^.right:= 나무(nr); 트리:=t; 끝; {나무} 끝. 2. 이진 순서 트리에서 키 필드의 주어진 값을 가진 노드를 찾습니다. 트리에 그러한 요소가 없으면 트리에 추가하십시오. 검색 절차(x: 바이트; var t: TreeLink); 시작 t = nil이면 시작 영원); t^inf:= x; t^.left:= nil; t^.right:= 없음; 종료 그렇지 않으면 x < t^.inf이면 검색(x, t^.left) 그렇지 않으면 x > t^.inf이면 검색(x, t^.right) 다른 시작 {프로세스 발견 요소} ... 끝; 끝. 23. 그래프의 개념. 그래프를 나타내는 방법 그래프는 G = (V,E) 쌍입니다. 여기서 V는 정점이라고 하는 임의의 속성을 가진 개체 집합이고 E는 가장자리라고 하는 쌍 ei = (vil, vi2), vijoV 쌍의 집합입니다. 일반적으로 집합 V 및 (또는) 가족 E는 무한한 수의 요소를 포함할 수 있지만 유한 그래프, 즉 V와 E가 모두 유한한 그래프만 고려할 것입니다. ei에 포함된 요소의 순서가 중요하면 그래프를 방향성, 축약형 - 쌍곡선, 그렇지 않으면 무방향성이라고 합니다. 쌍곡선의 모서리를 호라고 합니다. 전자 = , 정점 v와 u를 가장자리의 끝이라고 합니다. 여기서 우리는 모서리 e가 각 정점 v와 u에 인접(입사)한다고 말합니다. 꼭짓점 v 및 및 및 인접(사고)이라고도 합니다. 일반적인 경우 e = ; 이러한 모서리를 루프라고 합니다. 그래프 정점의 차수는 주어진 정점에 입사하는 모서리의 수이며 루프는 두 번 계산됩니다. 노드의 가중치는 주어진 노드에 할당된 숫자(실수, 정수 또는 유리수)입니다(비용, 처리량 등으로 해석됨). 그래프의 경로(또는 이중 그래프의 경로)는 v0, (v0,v1), v1,..., (vn -1, vn), vn. 숫자 n을 경로 길이라고 합니다. 반복되는 가장자리가 없는 경로를 체인이라고 하며, 반복되는 정점이 없는 경로를 단순 체인이라고 합니다. 반복되는 가장자리가 없는 닫힌 경로를 순환(또는 이중 그래프의 등고선); 정점을 반복하지 않고(첫 번째와 마지막을 제외하고) - 단순 주기. 그래프는 두 정점 사이에 경로가 있으면 연결되어 있고 그렇지 않으면 연결이 해제되어 있습니다. 그래프를 표현하는 방법은 다양합니다. 1. 인시던트 매트릭스. 이것은 n x m 직사각형 행렬입니다. 여기서 n은 꼭짓점의 수이고 m은 모서리의 수입니다. 2. 인접 행렬. 이것은 n × n 차원의 정방 행렬이며, 여기서 n은 꼭짓점의 수입니다. 3. 인접 항목(사건) 목록. 하는 데이터 구조를 나타냅니다. 그래프의 각 정점에 대해 인접한 정점 목록을 저장합니다. 목록은 포인터의 배열이며, i 번째 요소에는 i 번째 정점에 인접한 정점 목록에 대한 포인터가 포함되어 있습니다. 4. 목록 목록. 하나의 분기가 각각에 인접한 정점 목록을 포함하는 트리와 같은 데이터 구조입니다. 24. 다양한 그래프 표현 그래프를 발생 목록으로 구현하려면 다음 유형을 사용할 수 있습니다. 유형 목록 = ^S; S=기록; inf: 바이트; 다음: 목록; 끝; 그러면 그래프는 다음과 같이 정의됩니다. Vargr: 목록의 배열[1..n]; 이제 그래프 순회 절차를 살펴보겠습니다. 이것은 그래프의 모든 정점을 보고 모든 정보 필드를 분석할 수 있는 보조 알고리즘입니다. 그래프 순회를 심층적으로 고려하면 재귀 및 비재귀의 두 가지 유형의 알고리즘이 있습니다. Pascal에서 깊이 우선 탐색 절차는 다음과 같습니다. 절차 Obhod(gr: 그래프; k: 바이트); Varg: 그래프; l:목록; 시작 XNUMX월[k]:= 거짓; g:=gr; 동안 g^.inf <> k g:= g^.다음; l:= g^.smeg; l <> nil 시작하는 동안 nov[l^.inf]이면 Obhod(gr, l^.inf); l:= l^.다음; 끝; 끝; 그래프를 목록 목록으로 표현하기 그래프는 다음과 같이 목록 목록을 사용하여 정의할 수 있습니다. 유형 목록 = ^Tlist; tlist=기록 inf: 바이트; 다음: 목록; 끝; 그래프 = ^TGpaph; TGpaph = 기록 inf: 바이트; 스메그: 목록; 다음: 그래프; 끝; 폭으로 그래프를 탐색할 때 임의의 정점을 선택하고 인접한 모든 정점을 한 번에 살펴봅니다. 다음은 의사 코드에서 너비의 그래프를 탐색하는 절차입니다. 절차 Obhod2(v); 시작 대기열 = O; 큐 <= v; nov[v] = 거짓; 동안 큐 <> O 할 시작 p <= 큐; 당신을 위해 spisok(p) 새[u]인 경우 시작 nov[u]:= 거짓; 큐 <= 유; 끝; 끝; 끝; 25. 파스칼의 객체 유형. 대상의 개념, 설명 및 사용 객체 지향 프로그래밍 언어는 세 가지 주요 속성이 특징입니다. 1) 캡슐화. 이러한 레코드의 필드를 조작하는 프로시저 및 기능과 레코드를 결합하면 새로운 데이터 유형인 객체가 형성됩니다. 2) 상속. 개체 정의 및 계층 구조와 관련된 각 하위 개체가 모든 상위 개체의 코드 및 데이터에 액세스할 수 있는 기능을 사용하여 하위 개체의 계층 구조를 구축하는 데 사용합니다. 3) 다형성. 작업에 단일 이름을 부여한 다음 개체의 계층 구조 위아래로 공유되며 계층 구조의 각 개체가 적절한 방식으로 해당 작업을 수행합니다. 객체에 대해 말하자면, 우리는 새로운 데이터 유형인 객체를 소개합니다. 개체 유형은 고정된 수의 구성 요소로 구성된 구조입니다. 각 구성 요소는 엄격하게 정의된 유형의 데이터를 포함하는 필드이거나 개체에 대해 작업을 수행하는 메서드입니다. 개체 유형은 다른 개체 유형의 구성 요소를 상속할 수 있습니다. 유형 T2가 유형 T1에서 상속되는 경우 유형 T2는 유형 G의 자식이고 유형 G 자체는 유형 G2의 상위입니다. 다음 소스 코드는 개체 유형 선언의 예를 제공합니다. 유형 점 = 물체 X, Y: 정수; 끝; 사각형 = 객체 A, B: T포인트; 절차 Init(XA, YA, XB, YB: 정수); 절차 복사(var R: TRectangle); 절차 이동(DX, DY: 정수); 절차 Grow(DX, DY: 정수); 프로시저 Intersect(var R: TRectangle); 절차 Union(var R: TRectangle); 함수 포함(P: 포인트): 부울; 끝; 다른 유형과 달리 개체 유형은 프로그램 또는 모듈 범위의 가장 바깥쪽 수준에 있는 유형 선언 섹션에서만 선언할 수 있습니다. 따라서 객체 유형은 변수 선언 섹션이나 프로시저, 함수 또는 메서드 블록 내부에서 선언할 수 없습니다. 파일 유형 구성 요소 유형은 객체 유형 또는 객체 유형 구성 요소를 포함하는 구조 유형을 가질 수 없습니다. 26. 상속 상속은 기존 부모 유형에서 새 자식 유형을 생성하는 프로세스이고 자식은 부모로부터 모든 필드와 메서드를 수신(상속)합니다. 이 경우 자손 유형을 상속인 또는 자식 유형이라고 합니다. 그리고 자식 타입이 상속받은 타입을 부모 타입이라고 합니다. 상속된 필드 및 메서드는 변경되지 않거나 재정의(수정)되어 사용할 수 있습니다. N. Wirth는 그의 언어 Pascal에서 최대한 단순함을 추구했기 때문에 상속 관계를 도입하여 복잡하게 만들지 않았습니다. 따라서 Pascal의 유형은 상속할 수 없습니다. 그러나 Turbo Pascal 7.0은 이 언어를 확장하여 상속을 지원합니다. 그러한 확장 중 하나는 레코드와 관련된 새로운 데이터 구조 범주이지만 훨씬 더 강력합니다. 이 새 범주의 데이터 유형은 새 예약어 Object를 사용하여 정의됩니다. 구문은 레코드 정의 구문과 매우 유사합니다. 타입 <유형 이름> = 개체 [(<상위 유형 이름>)] ([<범위>] <필드 및 방법 설명>)+ 끝; 괄호 안에 있는 구문 구조 뒤의 "+" 기호는 이 구조가 이 설명에서 한 번 이상 발생해야 함을 의미합니다. 범위는 다음 키워드 중 하나입니다. ▪ 비공개; ▪ 보호됨; ▪ 공개. 범위는 이 범위의 이름을 지정하는 키워드 다음에 설명이 포함된 구성 요소를 사용할 수 있는 프로그램 부분을 나타냅니다. 구성 요소 범위에 대한 자세한 내용은 질문 #28을 참조하세요. 상속은 프로그램 개발에 사용되는 강력한 도구입니다. 계층 구조를 형성하는 유형의 개체 간의 관계를 표현하는 언어를 사용하여 문제의 개체 지향 분해를 실제로 구현할 수 있으며 프로그램 코드의 재사용을 촉진합니다. 27. 객체 인스턴스화 개체 인스턴스는 개체 유형의 변수 또는 상수를 선언하거나 "개체 유형에 대한 포인터" 유형의 변수에 표준 절차 New를 적용하여 생성됩니다. 결과 개체를 개체 유형의 인스턴스라고 합니다. 객체 유형에 가상 메서드가 포함된 경우 해당 객체 유형의 인스턴스는 가상 메서드를 호출하기 전에 생성자를 호출하여 초기화해야 합니다. 개체 유형의 인스턴스를 할당한다고 해서 인스턴스가 초기화되는 것은 아닙니다. 개체는 생성자의 호출과 실행이 실제로 생성자의 코드 블록에서 첫 번째 문에 도달하는 지점 사이에서 실행되는 컴파일러 생성 코드에 의해 초기화됩니다. 개체 인스턴스가 초기화되지 않고 범위 검사가 활성화된 경우({$R+} 지시문에 의해) 개체 인스턴스의 가상 메서드에 대한 첫 번째 호출은 런타임 오류를 제공합니다. 범위 검사가 {$R-} 지시문에 의해 해제된 경우 초기화되지 않은 개체의 가상 메서드에 대한 첫 번째 호출은 예측할 수 없는 동작으로 이어질 수 있습니다. 필수 초기화 규칙은 구조체 유형의 구성 요소인 인스턴스에도 적용됩니다. 예를 들어: 였다 주석: TStrField의 배열 [1..5]; 나: 정수 시작하다 I:= 1에서 5까지 주석 [I].Init (1, I + 10, 40, '이름'); . . . I:= 1 ~ 5에 대해 주석 [I].Done; 끝; 동적 인스턴스의 경우 일반적으로 초기화는 배치이고 정리는 폐기이며, 이는 New 및 Dispose 표준 절차의 확장된 구문을 통해 수행됩니다. 예를 들어: 였다 SP: StrFieldPtr; 시작하다 New(SP, Init(1, 1, 25, '이름'); SP^.Put('블라디미르'); SP^.디스플레이; . . . 폐기(SP, 완료); 끝. 개체 유형에 대한 포인터는 모든 상위 개체 유형에 대한 포인터와 할당이 호환되므로 런타임에 개체 유형에 대한 포인터는 해당 유형의 인스턴스 또는 모든 하위 유형의 인스턴스를 가리킬 수 있습니다. 28. 구성 및 범위 빈 식별자의 범위는 객체 유형을 넘어 확장됩니다. 게다가, 빈 식별자의 범위는 객체 유형과 그 자손의 메소드를 구현하는 프로시저, 함수, 생성자 및 소멸자의 블록을 통해 확장됩니다. 이러한 고려 사항을 기반으로 구성 요소 식별자는 개체 유형 내에서, 모든 하위 항목 및 모든 메서드 내에서 고유해야 합니다. 객체 유형 선언에서 메서드 헤더는 설명이 아직 완료되지 않은 경우에도 설명되는 객체 유형의 매개변수를 지정할 수 있습니다. 모든 유효한 범위의 구성 요소를 포함하는 형식 선언에 대해 다음 스키마를 고려하십시오. 타입 <유형 이름> = 개체 [(<상위 유형 이름>)] 프라이빗 투어 <필드 및 메서드에 대한 비공개 설명> 보호 <보호된 필드 및 메서드 설명> 공공 영역 <필드 및 메서드에 대한 공개 설명> 끝; Private 섹션에 설명된 필드와 메서드는 선언이 포함된 모듈 내에서만 사용할 수 있으며 다른 곳에서는 사용할 수 없습니다. Protected 필드 및 메서드, 즉 Protected 섹션에 설명된 항목은 형식이 정의된 모듈과 해당 형식의 하위 항목에서 볼 수 있습니다. Public 섹션의 필드와 메서드는 사용에 제한이 없으며 이 유형의 개체에 액세스할 수 있는 프로그램의 모든 위치에서 사용할 수 있습니다. 형식 선언의 private 부분에 설명된 구성 요소 식별자의 범위는 개체 형식 선언을 포함하는 모듈(프로그램)로 제한됩니다. 즉, 개인 식별자 빈은 객체 유형 선언을 포함하는 모듈 내에서 일반 공용 식별자처럼 작동하며 모듈 외부에서 모든 개인 빈 및 식별자는 알 수 없고 액세스할 수 없습니다. 관련된 객체 유형을 동일한 모듈에 넣으면 이러한 객체가 서로의 개인 구성 요소에 액세스하도록 할 수 있으며 이러한 개인 구성 요소는 다른 모듈에 알려지지 않습니다. 29. 방법 개체 유형 내부의 메서드 선언은 정방향 메서드 선언(forward)에 해당합니다. 따라서 개체 유형 선언 후 어딘가에 개체 유형 선언의 범위와 동일한 범위 내에서 해당 선언을 정의하여 메서드를 구현해야 합니다. 절차적 및 기능적 메서드의 경우 정의 선언은 일반 프로시저 또는 함수 선언의 형식을 취하지만 이 경우 프로시저 또는 함수 식별자가 메서드 식별자로 취급된다는 점은 예외입니다. 메서드의 정의 설명에는 항상 개체 유형의 형식 변수 매개 변수에 해당하는 식별자 Self가 있는 암시적 매개 변수가 포함됩니다. 메서드 블록 내에서 Self는 메서드를 호출하기 위해 메서드 구성 요소가 지정된 인스턴스를 나타냅니다. 따라서 Self 필드의 값에 대한 모든 변경 사항은 인스턴스에 반영됩니다. 가상 방법 메서드는 기본적으로 정적이지만 생성자를 제외하고 가상일 수 있습니다(메서드 선언에 가상 지시문을 포함하여). 컴파일러는 컴파일 프로세스 중에 정적 메서드 호출에 대한 참조를 확인하는 반면 가상 메서드에 대한 호출은 런타임에 확인됩니다. 이것을 후기 바인딩이라고도 합니다. 정적 메서드 재정의는 메서드 헤더 변경과 무관합니다. 대조적으로 가상 메서드 재정의는 순서, 매개변수 유형 및 이름, 함수 결과 유형(있는 경우)을 유지해야 합니다. 또한 재정의에는 가상 지시문이 다시 포함되어야 합니다. 동적 방법 Borland Pascal은 동적 메서드라고 하는 추가 후기 바인딩 메서드를 지원합니다. 동적 메서드는 런타임에 전달되는 방식에서만 가상 메서드와 다릅니다. 다른 모든 측면에서 동적 메서드는 가상 메서드와 동일한 것으로 간주됩니다. 동적 메서드 선언은 가상 메서드 선언과 동일하지만 동적 메서드 선언에는 virtual 키워드 바로 뒤에 지정되는 동적 메서드 인덱스가 포함되어야 합니다. 동적 메서드의 인덱스는 1에서 656535 사이의 정수 상수여야 하며 개체 유형 또는 해당 상위 항목에 포함된 다른 동적 메서드의 인덱스 간에 고유해야 합니다. 예를 들어: 프로시저 FileOpen(var Msg: TMessage); 가상 100; 동적 메소드의 재정의는 매개변수의 순서, 유형 및 이름과 일치해야 하고 상위 메소드 함수의 결과 유형과 정확히 일치해야 합니다. 재정의에는 상위 개체 유형에 지정된 것과 동일한 동적 메서드 인덱스가 뒤에 오는 가상 지시문도 포함되어야 합니다. 30. 생성자와 소멸자 생성자와 소멸자는 메서드의 특수한 형태입니다. New 및 Dispose 표준 프로시저의 확장된 구문과 관련하여 사용되는 생성자와 소멸자는 동적 개체를 배치하고 제거할 수 있습니다. 또한 생성자는 가상 메서드가 포함된 개체의 필수 초기화를 수행할 수 있습니다. 모든 메서드와 마찬가지로 생성자와 소멸자는 상속될 수 있으며 개체에는 원하는 수의 생성자와 소멸자가 포함될 수 있습니다. 생성자는 새로 생성된 객체를 초기화하는 데 사용됩니다. 일반적으로 초기화는 생성자에 매개변수로 전달된 값을 기반으로 합니다. 가상 메서드의 디스패치 메커니즘은 객체를 먼저 초기화한 생성자에 의존하기 때문에 생성자는 가상이 될 수 없습니다. 다음은 생성자의 몇 가지 예입니다. 생성자 Field.Copy(var F: 필드); 시작하다 본인:=F; 끝; 파생된(자식) 형식의 생성자의 주요 작업은 거의 항상 직계 부모의 적절한 생성자를 호출하여 개체의 상속된 필드를 초기화하는 것입니다. 이 절차를 수행한 후 생성자는 파생된 형식에만 속하는 개체의 필드를 초기화합니다. 소멸자는 생성자의 반대이며 사용된 객체를 정리하는 데 사용됩니다. 일반적으로 정리는 개체의 모든 포인터 필드를 제거하는 것으로 구성됩니다. 주의 소멸자는 가상일 수 있으며 종종 그렇습니다. 소멸자에는 매개변수가 거의 없습니다. 다음은 소멸자의 몇 가지 예입니다. 소멸자 필드 완료; 시작하다 FreeMem(이름, 길이(이름^) + 1); 끝; 소멸자 StrField.Done; 시작하다 FreeMem(값, 렌); 필드 완료; 끝; 위의 TStrField와 같은 자식 유형의 소멸자입니다. 완료, 일반적으로 먼저 파생된 형식에 도입된 포인터 필드를 제거한 다음 마지막 단계로 직계 부모의 적절한 수집기 소멸자를 호출하여 개체의 상속된 포인터 필드를 제거합니다. 31. 소멸자 Borland Pascal은 동적으로 할당된 객체를 정리하고 삭제하기 위해 가비지 수집기(또는 소멸자)라고 하는 특별한 유형의 메서드를 제공합니다. 소멸자는 개체를 삭제하는 단계를 해당 개체 유형에 필요한 다른 작업이나 작업과 결합합니다. 단일 객체 유형에 대해 여러 소멸자를 정의할 수 있습니다. 소멸자는 상속될 수 있으며 정적 또는 가상일 수 있습니다. 다른 종료자는 다른 유형의 객체를 요구하는 경향이 있기 때문에 일반적으로 각 객체 유형에 대해 올바른 소멸자가 실행되도록 소멸자를 항상 가상 상태로 유지하는 것이 좋습니다. 객체의 유형 정의에 가상 메소드가 포함된 경우에도 모든 정리 메소드에 예약어 소멸자를 지정할 필요는 없습니다. 소멸자는 실제로 동적으로 할당된 개체에서만 작동합니다. 동적으로 할당된 객체가 정리될 때 소멸자는 특별한 기능을 수행합니다. 즉, 동적으로 할당된 메모리 영역에서 항상 올바른 수의 바이트가 해제되도록 합니다. 정적으로 할당된 개체와 함께 소멸자를 사용하는 것에 대해 걱정할 필요가 없습니다. 사실, 객체의 유형을 소멸자에 전달하지 않음으로써 프로그래머는 해당 유형의 객체에서 Borland Pascal의 동적 메모리 관리의 모든 이점을 박탈합니다. 소멸자는 실제로 다형성 개체를 지워야 하고 해당 개체가 차지하는 메모리를 할당 해제해야 할 때 자신이 됩니다. 다형성 객체는 볼랜드 파스칼의 확장된 유형 호환성 규칙으로 인해 부모 유형에 할당된 객체입니다. "다형성"이라는 용어는 컴파일 타임에 개체를 처리하는 코드가 최종적으로 처리해야 하는 개체 유형을 정확히 "모르는" 것이기 때문에 적절합니다. 유일한 것은 이 개체가 지정된 개체 유형의 하위 항목인 개체 계층에 속한다는 것뿐입니다. 소멸자 메서드 자체는 비어 있을 수 있으며 다음 기능만 수행할 수 있습니다. 소멸자AnObject.Done; 시작하다 끝; 이 소멸자에서 유용한 것은 본체의 속성이 아니지만 컴파일러는 소멸자 예약어에 대한 응답으로 에필로그 코드를 생성합니다. 아무것도 내보내지 않는 모듈과 같지만 프로그램을 시작하기 전에 초기화 섹션을 실행하여 보이지 않는 작업을 수행합니다. 모든 작업은 무대 뒤에서 이루어집니다. 32. 가상 방법 메서드는 객체 유형 선언 다음에 새로운 예약어 virtual이 오면 가상이 됩니다. 부모 형식의 메서드가 가상으로 선언된 경우 자식 형식에서 같은 이름을 가진 모든 메서드도 가상으로 선언해야 컴파일러 오류를 방지할 수 있습니다. 다음은 제대로 가상화된 급여 예의 개체입니다. 유형 PEmployee = ^TEmployee; 직원 = 개체 이름, 제목: 문자열[25]; 비율: 실제; 생성자 초기화(AName, ATitle: 문자열, ARate: Real); 함수 GetPayAmount: 실제; 가상; 함수 GetName: 문자열; 함수 GetTitle: 문자열; 함수 GetRate: 실제; 절차 쇼; 가상; 끝; 매시간 = ^시간마다; Tourly = 개체(TEmployee); 시간: 정수; 생성자 초기화(AName, ATitle: 문자열, ARate: 실수, 시간: 정수); 함수 GetPayAmount: 실제; 가상; 함수 GetTime: 정수; 끝; PSalaried = ^TSSalared; TSalared = 개체(TEmployee); 함수 GetPayAmount: 실제; 가상; 끝; P커미션 = ^T 커미션됨; TCommissioned = 개체(급여); 커미션: 실제; 판매 금액: 실제; 생성자 초기화(AName, ATitle: 문자열; ARate, ACommission, ASalesAmount: Real); 함수 GetPayAmount: 실제; 가상; 끝; 생성자는 가상 메서드 메커니즘에 대한 일부 설정 작업을 수행하는 특수한 유형의 프로시저입니다. 또한 가상 메서드가 호출되기 전에 생성자를 호출해야 합니다. 생성자를 먼저 호출하지 않고 가상 메서드를 호출하면 시스템이 차단될 수 있으며 컴파일러는 메서드가 호출되는 순서를 확인할 방법이 없습니다. 가상 메서드가 있는 모든 개체 유형에는 생성자가 있어야 합니다. 생성자는 다른 가상 메서드가 호출되기 전에 호출되어야 합니다. 생성자에 대한 이전 호출 없이 가상 메서드를 호출하면 시스템 잠금이 발생할 수 있으며 컴파일러는 메서드가 호출되는 순서를 확인할 수 없습니다. 33. 개체 데이터 필드 및 형식 메서드 매개변수 메서드와 해당 개체가 공통 범위를 공유한다는 사실의 의미는 메서드의 형식 매개 변수가 개체의 데이터 필드와 동일할 수 없다는 것입니다. 이것은 객체 지향 프로그래밍에 의해 부과된 몇 가지 새로운 제한 사항이 아니라 Pascal이 항상 가지고 있던 동일한 이전 범위 규칙입니다. 이는 프로시저의 형식 매개변수가 프로시저의 로컬 변수와 동일하지 않도록 하는 것과 같습니다. 프로시저에 대한 이 오류를 설명하는 예를 고려하십시오. 절차 CrunchIt(Crunchee: MyDataRec, Crunchby, 오류 코드: 정수); 였다 A, B: 문자; 오류 코드: 정수; 시작하다 . . . 끝; 지역 변수 ErrorCode의 선언이 포함된 행에서 오류가 발생합니다. 이는 형식 매개 변수와 지역 변수의 식별자가 동일하기 때문입니다. 프로시저의 지역 변수와 형식 매개변수는 공통 범위를 공유하므로 동일할 수 없습니다. 이와 같은 것을 컴파일하려고 하면 "오류 4: 중복 식별자" 메시지가 나타납니다. 이 메서드가 속한 개체의 필드 이름에 형식 메서드 매개 변수를 할당하려고 할 때도 동일한 오류가 발생합니다. 데이터 구조 내부에 서브루틴 헤더를 넣는 것은 Turbo Pascal의 혁신에 대한 경의이지만 Pascal 범위의 기본 원칙은 변경되지 않았기 때문에 상황은 다소 다릅니다. 변수 및 매개변수 식별자를 선택할 때는 여전히 특정 문화권을 존중해야 합니다. 일부 프로그래밍 스타일은 중복 식별자의 위험을 줄이기 위해 유형 필드의 이름을 지정하는 방법을 제공합니다. 예를 들어 헝가리어 표기법은 필드 이름이 "m" 접두사로 시작하도록 제안합니다. 34. 캡슐화 객체의 코드와 데이터의 조합을 캡슐화라고 합니다. 원칙적으로 개체의 사용자가 개체의 필드에 직접 액세스하지 않도록 충분한 메서드를 제공하는 것이 가능합니다. Smalltalk와 같은 일부 다른 객체 지향 언어는 필수 캡슐화를 요구하지만 Borland Pascal에는 선택권이 있습니다. 예를 들어, TEmployee 및 THourly 개체는 내부 데이터 필드에 직접 액세스할 필요가 전혀 없는 방식으로 작성되었습니다. 유형 직원 = 개체 이름, 제목: 문자열[25]; 비율: 실제; 프로시저 Init(AName, ATitle: 문자열, ARate: Real); 함수 GetName: 문자열; 함수 GetTitle: 문자열; 함수 GetRate: 실제; 함수 GetPayAmount: 실제; 끝; Tourly = 개체(TEmployee) 시간: 정수; 프로시저 초기화(AName, ATitle: 문자열; ARate: 실수, Atime: 정수); 함수 GetPayAmount: 실제; 끝; 여기에는 Name, Title, Rate 및 Time의 네 가지 데이터 필드만 있습니다. GetName 및 GetTitle 메서드는 각각 작업자의 성 및 위치를 표시합니다. GetPayAmount 메서드는 Rate를 사용하고, 근무하는 경우 THourly 및 Time을 사용하여 근무에 대한 지불 금액을 계산합니다. 더 이상 이러한 데이터 필드를 직접 참조할 필요가 없습니다. THourly 유형의 AnHourly 인스턴스가 있다고 가정하면 다음과 같이 AnHourly의 데이터 필드를 조작하는 메서드 집합을 사용할 수 있습니다. 시간당 할 일 시작하다 Init(Aleksandr Petrov, 지게차 운전자' 12.95, 62); {성, 직위, 금액을 표시합니다. 지불} 쇼; 끝; 개체의 필드에 대한 액세스는 이 개체의 메서드를 통해서만 수행된다는 점에 유의해야 합니다. 35. 개체 확장 파생 형식이 정의되면 부모 형식의 메서드가 상속되지만 원하는 경우 재정의할 수 있습니다. 상속된 메서드를 재정의하려면 상속된 메서드와 이름이 같지만 본문과 (필요한 경우) 매개 변수 집합이 다른 새 메서드를 선언하면 됩니다. 다음 예에서 시급을 받는 직원을 나타내는 TEmployee의 자식 유형을 정의해 보겠습니다. const를 급여 기간 = 26; { 지불 기간 } 초과 근무 임계값 = 80; { 지불 기간 동안 } 초과 근무 계수 = 1.5; { 시간당 요금 } 유형 Tourly = 개체(TEmployee) 시간: 정수; 프로시저 초기화(AName, ATitle: 문자열; ARate: 실수, Atime: 정수); 함수 GetPayAmount: 실제; 끝; 절차 THourly.Init(AName, ATitle: 문자열; ARate: 실수, Atime: 정수); 시작하다 TEmployee.Init(AName, ATitle, ARate); 시간:= A시간; 끝; 함수 THourly.GetPayAmount: 실제; 였다 초과 근무: 정수; 시작하다 초과 근무:= 시간 - 초과 근무 임계값; 초과 근무 > 0이면 GetPayAmount:= RoundPay(OvertimeThreshold * 비율 + RateOverTime * OvertimeFactor *비율) 그렇지 않으면 GetPayAmount:= RoundPay(시간 * 요금) 끝; 재정의된 메서드를 호출할 때 파생된 개체 형식에 부모의 기능이 포함되어 있는지 확인해야 합니다. 또한 부모 메서드를 변경하면 모든 자식 메서드에 자동으로 영향을 줍니다. 중요 참고 사항: 메서드는 재정의할 수 있지만 데이터 필드는 재정의할 수 없습니다. 데이터 필드가 개체 계층 구조에서 정의되면 정확히 동일한 이름을 가진 데이터 필드를 정의할 수 있는 하위 유형이 없습니다. 36. 객체 유형의 호환성 상속은 Borland Pascal의 유형 호환성 규칙을 어느 정도 수정합니다. 자손은 모든 조상의 형식 호환성을 상속합니다. 이 확장된 유형 호환성은 세 가지 형식을 취합니다. 1) 객체의 구현 사이; 2) 객체 구현에 대한 포인터 사이; 3) 형식 매개변수와 실제 매개변수 사이. 유형 호환성은 자식에서 부모로만 확장됩니다. 예를 들어 TSalaried는 TEmployee의 자식이고 TCommissioned는 TSalaried의 자식입니다. 다음 설명을 고려하십시오. 였다 직원: TEmployee; A샐러리드: TS샐러리드; P커미션: T커미션; TEmployeePtr: ^TEmployee; TSalariedPtr: ^TSalried; TCommissionedPtr: ^TCommissioned; 이러한 설명에서 다음 할당 연산자가 유효합니다. 직원:=A급여; A샐러리드:= A커미션; TCommissionedPtr:= ACommissioned; 일반적으로 형식 호환성 규칙은 다음과 같이 공식화됩니다. 소스는 수신기를 완전히 채울 수 있어야 합니다. 파생 유형에는 상속 속성으로 인해 상위 유형에 포함된 모든 것이 포함됩니다. 따라서 파생된 형식의 크기는 부모 크기보다 작지 않습니다. 부모 개체를 자식 개체에 할당하면 부모 개체의 일부 필드가 정의되지 않은 상태로 남게 되어 위험하므로 불법입니다. 대입문에서 두 유형에 공통적인 필드만 소스에서 대상으로 복사됩니다. 할당 연산자에서: 직원:= 위임됨; ACommissioned의 Name, Title 및 Rate 필드만 AnEmployee에 복사됩니다. 이러한 필드는 TCommissioned와 TEmployee 간에 공유되는 유일한 필드이기 때문입니다. 유형 호환성은 객체 유형에 대한 포인터 간에도 작동하며 객체 구현과 동일한 일반 규칙을 따릅니다. 자식에 대한 포인터는 부모에 대한 포인터에 할당될 수 있습니다. 이전 정의가 주어지면 다음 포인터 할당이 유효합니다. TSalariedPtr:= TCommissionedPtr; TEmployeePtr:= TSalariedPtr; TEmployeePtr:= PCommissionedPtr; 주어진 객체 유형의 형식 매개변수(값 또는 변수 매개변수)는 자체 유형의 객체 또는 모든 자식 유형의 객체를 실제 매개변수로 사용할 수 있습니다. 다음과 같이 프로시저 헤더를 정의하는 경우: 절차 CalcFedTax(피해자: TSalaried); 실제 매개변수 유형은 TSalared 또는 TCommissioned일 수 있지만 TEmployee는 아닙니다. 피해자도 변수가 될 수 있습니다. 이 경우 동일한 호환성 규칙을 따릅니다. 값 매개변수는 매개변수로 전달되는 실제 개체에 대한 포인터이고 변수 매개변수는 실제 매개변수의 복사본입니다. 이 사본에는 형식 값 매개변수 유형의 일부인 필드만 포함됩니다. 즉, 실제 매개변수가 형식 매개변수의 유형으로 변환됩니다. 37. 어셈블러 정보 옛날 옛적에 어셈블러는 컴퓨터가 유용한 일을 하도록 만드는 것이 불가능하다는 것을 모르는 언어였습니다. 점차 상황이 바뀌었습니다. 컴퓨터와 더 편리한 통신 수단이 등장했습니다. 그러나 다른 언어와 달리 어셈블러는 죽지 않았고, 또한 원칙적으로 그렇게 할 수 없었습니다. 왜요? 답을 찾기 위해 일반적으로 어셈블리 언어가 무엇인지 이해하려고 노력할 것입니다. 요컨대, 어셈블리 언어는 기계어의 상징적 표현입니다. 가장 낮은 하드웨어 수준에서 기계의 모든 프로세스는 기계어의 명령(명령)에 의해서만 구동됩니다. 이를 통해 일반적인 이름에도 불구하고 컴퓨터 유형마다 어셈블리 언어가 다르다는 것이 분명합니다. 이것은 어셈블러로 작성된 프로그램의 모양과 이 언어가 반영하는 아이디어에도 적용됩니다. 하드웨어 관련 문제(또는 프로그램 속도 향상과 같은 하드웨어 관련 문제)를 실제로 해결하는 것은 어셈블러에 대한 지식 없이는 불가능합니다. 프로그래머나 다른 사용자는 가상 세계를 구축하기 위한 프로그램에 이르기까지 모든 고급 도구를 사용할 수 있으며 아마도 컴퓨터가 실제로 프로그램이 작성된 언어의 명령이 아니라 변환된 표현을 실행하고 있다고 의심조차 할 수 없습니다. 완전히 다른 언어인 기계어의 지루하고 지루한 시퀀스 명령의 형태로. 이제 그러한 사용자에게 비표준 문제가 있다고 상상해보십시오. 예를 들어 그의 프로그램은 비정상적인 장치와 함께 작동하거나 컴퓨터 하드웨어의 원리에 대한 지식이 필요한 다른 작업을 수행해야 합니다. 프로그래머가 자신의 프로그램을 작성한 언어가 아무리 훌륭해도 어셈블러를 모르면 할 수 없습니다. 그리고 고급 언어의 거의 모든 컴파일러가 어셈블러의 모듈과 모듈을 연결하는 수단을 포함하거나 어셈블러 프로그래밍 수준에 대한 액세스를 지원하는 것은 우연이 아닙니다. 컴퓨터는 각각 시스템 장치라고 하는 단일 장치에 연결된 여러 물리적 장치로 구성됩니다. 38. 마이크로프로세서의 소프트웨어 모델 오늘날의 컴퓨터 시장에는 매우 다양한 유형의 컴퓨터가 있습니다. 따라서 소비자가 컴퓨터의 특정 유형(또는 모델)의 기능과 다른 유형(모델)의 컴퓨터와 구별되는 기능을 평가하는 방법에 대한 질문이 있다고 가정하는 것이 가능합니다. 컴퓨터의 블록 다이어그램만 고려하는 것만으로는 충분하지 않습니다. 컴퓨터마다 근본적으로 차이가 거의 없기 때문입니다. 모든 컴퓨터에는 RAM, 프로세서 및 외부 장치가 있습니다. 컴퓨터가 단일 메커니즘으로 작동하는 데 사용되는 방법, 수단 및 리소스가 다릅니다. 기능적 프로그램 제어 속성 측면에서 컴퓨터를 특징짓는 모든 개념을 통합하기 위해 컴퓨터 아키텍처라는 특별한 용어가 있습니다. 처음으로 컴퓨터 아키텍처의 개념은 비교 평가를 위한 3세대 기계의 출현과 함께 언급되기 시작했습니다. 컴퓨터의 어떤 부분이 이 언어로 프로그래밍할 수 있고 액세스할 수 있는지 확인한 후에만 컴퓨터의 어셈블리 언어 학습을 시작하는 것이 좋습니다. 이것은 소위 컴퓨터 프로그램 모델이며, 그 일부는 프로그래머가 사용할 수 있는 32개의 레지스터를 포함하는 마이크로프로세서 프로그램 모델입니다. 이러한 레지스터는 두 개의 큰 그룹으로 나눌 수 있습니다. 1) 사용자 등록 16개; 2) 16개의 시스템 레지스터. 어셈블리 언어 프로그램은 레지스터를 매우 많이 사용합니다. 대부분의 레지스터에는 특정 기능적 목적이 있습니다. 위에 나열된 레지스터 외에도 프로세서 개발자는 특정 클래스의 계산을 최적화하도록 설계된 소프트웨어 모델에 추가 레지스터를 도입합니다. 그래서 Intel Corporation의 Pentium Pro(MMX) 프로세서 제품군에는 Intel의 MMX 확장이 도입되었습니다. 여기에는 8(MM0-MM7) 64비트 레지스터가 포함되어 있으며 몇 가지 새로운 데이터 유형 쌍에 대해 정수 연산을 수행할 수 있습니다. 1) XNUMX개의 패킹된 바이트; 2) XNUMX개의 포장된 단어; 3) 두 개의 이중 단어; 4) 쿼드러플 워드; 다시 말해서, 예를 들어 프로그래머는 하나의 MMX 확장 명령어로 두 개의 이중 단어를 함께 추가할 수 있습니다. 물리적으로 새로운 레지스터가 추가되지 않았습니다. MM0-MM7은 64비트 FPU(부동 소수점 단위 - 보조 프로세서) 레지스터 스택의 가수(하위 80비트)입니다. 또한 현재 프로그래밍 모델의 다음과 같은 확장이 있습니다 - 3DNOW! AMD에서; SSE, SSE2, SSE3, SSE4. 마지막 4개의 확장은 AMD 및 Intel 프로세서에서 모두 지원됩니다. 39. 사용자 등록 이름에서 알 수 있듯이 사용자 레지스터는 프로그래머가 프로그램을 작성할 때 사용할 수 있기 때문에 호출됩니다. 이러한 레지스터에는 다음이 포함됩니다. 1) 프로그래머가 데이터와 주소를 저장하는 데 사용할 수 있는 32개의 XNUMX비트 레지스터(범용 레지스터(RON)라고도 함): ▪ eax/ax/ah/al; ▪ ebx/bx/bh/bl; ▪ edx/dx/dh/dl; ▪ ecx/cx/ch/cl; ▪ ebp/bp; ▪ esi/si; ▪ 에디/디; ▪ 특히/sp. 2) XNUMX개의 세그먼트 레지스터: ▪ CS; ▪ ds; ▪ SS; ▪ es; ▪fs; ▪gs; 3) 상태 및 제어 레지스터: ▪ 플래그는 eflags/flags를 등록합니다. ▪ 명령 포인터 레지스터 eip/ip. 다음 그림은 마이크로프로세서의 주요 레지스터를 보여줍니다. 범용 레지스터
40. 일반 레지스터 이 그룹의 모든 레지스터를 사용하면 "하단" 부분에 액세스할 수 있습니다. 이러한 레지스터의 하위 16비트 및 8비트 부분만 자체 주소 지정에 사용할 수 있습니다. 이러한 레지스터의 상위 16비트는 독립 개체로 사용할 수 없습니다. 범용 레지스터 그룹에 속하는 레지스터를 나열해 보겠습니다. 이러한 레지스터는 ALU(산술 논리 장치) 내부의 마이크로프로세서에 물리적으로 위치하므로 ALU 레지스터라고도 합니다. 1) eax/ax/ah/al (누산기 레지스터) - 배터리. 중간 데이터를 저장하는 데 사용됩니다. 일부 명령에서는 이 레지스터를 사용해야 합니다. 2) ebx/bx/bh/bl (기본 레지스터) - 기본 레지스터. 메모리에 일부 개체의 기본 주소를 저장하는 데 사용됩니다. 3) ecx/cx/ch/cl (카운트 레지스터) - 카운터 레지스터. 일부 반복 작업을 수행하는 명령에 사용됩니다. 그것의 사용은 종종 암시적이며 해당 명령의 알고리즘에 숨겨져 있습니다. 예를 들어, 루프 구성 명령은 특정 주소에 있는 명령으로 제어를 전달하는 것 외에도 ecx/cx 레지스터의 값을 분석하고 XNUMX만큼 감소시킵니다. 4) edx/dx/dh/dl (데이터 레지스터) - 데이터 레지스터. eax/ax/ah/al 레지스터와 마찬가지로 중간 데이터를 저장합니다. 일부 명령은 사용이 필요합니다. 일부 명령의 경우 이것은 암시적으로 발생합니다. 다음 두 레지스터는 소위 체인 작업, 즉 각각 32, 16 또는 8비트 길이가 될 수 있는 요소 체인을 순차적으로 처리하는 작업을 지원하는 데 사용됩니다. 1) esi/si(소스 인덱스 레지스터) - 소스 인덱스. 체인 작업의 이 레지스터에는 소스 체인에 있는 요소의 현재 주소가 포함됩니다. 2) edi/di(목적지 색인 레지스터) - 수신자(수신자)의 색인. 체인 작업의 이 레지스터에는 대상 체인의 현재 주소가 포함됩니다. 하드웨어 및 소프트웨어 수준의 마이크로 프로세서 아키텍처에서는 스택과 같은 데이터 구조가 지원됩니다. 마이크로 프로세서 명령 시스템의 스택으로 작업하기 위해 특수 명령이 있으며 마이크로 프로세서 소프트웨어 모델에는 이에 대한 특수 레지스터가 있습니다. 1) esp/sp (스택 포인터 레지스터) - 스택 포인터 레지스터. 현재 스택 세그먼트의 스택 상단에 대한 포인터를 포함합니다. 2) ebp/bp(기본 포인터 레지스터) - 스택 프레임 기본 포인터 레지스터. 스택 내부의 데이터에 대한 임의 액세스를 구성하도록 설계되었습니다. 일부 명령어에 대한 레지스터의 고정 고정을 사용하면 기계 표현을 보다 간결하게 인코딩할 수 있습니다. 이러한 기능을 알면 필요한 경우 프로그램 코드가 차지하는 메모리의 최소 몇 바이트를 절약할 수 있습니다. 41. 세그먼트 레지스터 마이크로프로세서 소프트웨어 모델에는 XNUMX개의 세그먼트 레지스터가 있습니다: cs, ss, ds, es, gs, fs. 그들의 존재는 조직의 특성과 Intel 마이크로 프로세서의 RAM 사용으로 인한 것입니다. 마이크로프로세서 하드웨어가 세그먼트라고 하는 세 부분의 형태로 프로그램의 구조적 구성을 지원한다는 사실에 있습니다. 따라서 이러한 메모리 구성을 세그먼트라고합니다. 특정 시점에 프로그램이 액세스할 수 있는 세그먼트를 나타내기 위해 세그먼트 레지스터가 사용됩니다. 사실(약간 수정) 이 레지스터에는 해당 세그먼트가 시작되는 메모리 주소가 포함되어 있습니다. 기계 명령을 처리하는 논리는 잘 정의된 세그먼트 레지스터의 주소가 명령을 가져오거나 프로그램 데이터에 액세스하거나 스택에 액세스할 때 암시적으로 사용되는 방식으로 구성됩니다. 마이크로프로세서는 다음 유형의 세그먼트를 지원합니다. 1. 코드 세그먼트. 프로그램 명령을 포함합니다. 이 세그먼트에 액세스하려면 cs 레지스터(코드 세그먼트 레지스터)인 세그먼트 코드 레지스터가 사용됩니다. 여기에는 마이크로프로세서가 액세스할 수 있는 기계 명령어 세그먼트의 주소가 포함됩니다(즉, 이러한 명령어는 마이크로프로세서 파이프라인에 로드됨). 2. 데이터 세그먼트. 프로그램에서 처리한 데이터를 포함합니다. 이 세그먼트에 액세스하기 위해 ds(데이터 세그먼트 레지스터) 레지스터가 사용됩니다. 이 레지스터는 현재 프로그램의 데이터 세그먼트 주소를 저장하는 세그먼트 데이터 레지스터입니다. 3. 스택 세그먼트. 이 세그먼트는 스택이라고 하는 메모리 영역입니다. 마이크로프로세서는 다음 원칙에 따라 스택 작업을 구성합니다. 이 영역에 기록된 마지막 요소가 먼저 선택됩니다. 이 세그먼트에 액세스하기 위해 ss 레지스터(스택 세그먼트 레지스터)가 사용됩니다. 스택 세그먼트의 주소를 포함하는 스택 세그먼트 레지스터입니다. 4. 추가 데이터 세그먼트. 암시적으로 대부분의 기계 명령어를 실행하기 위한 알고리즘은 처리하는 데이터가 데이터 세그먼트에 있고 주소가 ds 세그먼트 레지스터에 있다고 가정합니다. 프로그램에 하나의 데이터 세그먼트가 충분하지 않은 경우 세 개의 추가 데이터 세그먼트를 사용할 수 있습니다. 그러나 주소가 ds 세그먼트 레지스터에 포함된 주 데이터 세그먼트와 달리 추가 데이터 세그먼트를 사용할 때 해당 주소는 명령에서 특수 세그먼트 재정의 접두사를 사용하여 명시적으로 지정되어야 합니다. 추가 데이터 세그먼트의 주소는 레지스터 es, gs, fs(확장 데이터 세그먼트 레지스터)에 포함되어야 합니다. 42. 상태 및 제어 레지스터 마이크로프로세서에는 마이크로프로세서 자체와 현재 파이프라인에 명령이 로드된 프로그램 모두의 상태에 대한 정보를 지속적으로 포함하는 여러 레지스터가 있습니다. 이러한 레지스터에는 다음이 포함됩니다. 1) 플래그 레지스터 플래그/플래그; 2) eip/ip 명령 포인터 레지스터. 이 레지스터를 사용하여 명령 실행 결과에 대한 정보를 얻고 마이크로프로세서 자체의 상태에 영향을 줄 수 있습니다. 이러한 레지스터의 목적과 내용을 더 자세히 살펴보겠습니다. 1. 플래그/플래그(플래그 레지스터) - 플래그 레지스터. 플래그/플래그의 비트 깊이는 32/16비트입니다. 이 레지스터의 개별 비트는 특정 기능적 목적을 가지며 플래그라고 합니다. 이 레지스터의 아래쪽 부분은 i8086의 플래그 레지스터와 완전히 유사합니다. 플래그/플래그 레지스터의 플래그는 사용 방법에 따라 세 그룹으로 나눌 수 있습니다. 1) XNUMX개의 상태 플래그. 이러한 플래그는 기계 명령어가 실행된 후에 변경될 수 있습니다. eflags 레지스터의 상태 플래그는 산술 또는 논리 연산 실행 결과의 세부 사항을 반영합니다. 이를 통해 계산 프로세스의 상태를 분석하고 조건부 점프 명령 및 서브루틴 호출을 사용하여 이에 응답할 수 있습니다. 2) 하나의 제어 플래그. df(디렉토리 플래그)로 표시됩니다. 플래그 레지스터의 비트 10에 위치하며 연결된 명령에 사용됩니다. df 플래그의 값은 다음 작업에서 요소별 처리 방향을 결정합니다. 문자열의 시작에서 끝까지(df = 0) 또는 그 반대로, 문자열의 끝에서 시작(df = 1). df 플래그로 작업하려면 cld(df 플래그 제거) 및 std(df 플래그 설정)와 같은 특수 명령이 있습니다. 이러한 명령을 사용하면 알고리즘에 따라 df 플래그를 조정하고 문자열에 대한 작업을 수행할 때 카운터가 자동으로 증가하거나 감소하도록 할 수 있습니다. 3) XNUMX개의 시스템 플래그. I/O, 마스크 가능한 인터럽트, 디버깅, 작업 전환 및 8086 가상 모드를 제어합니다. 응용 프로그램이 이러한 플래그를 불필요하게 수정하는 것은 대부분의 경우 프로그램을 종료하게 하므로 권장하지 않습니다. 2. eip/ip(Instraction Pointer register) - 명령어 포인터 레지스터. eip/ip 레지스터의 너비는 32/16비트이며 현재 명령 세그먼트에 있는 cs 세그먼트 레지스터의 내용과 관련하여 실행할 다음 명령의 오프셋을 포함합니다. 이 레지스터는 프로그래머가 직접 액세스할 수 없지만 조건부 및 무조건 점프, 프로시저 호출 및 프로시저에서 반환에 대한 명령을 포함하는 다양한 제어 명령에 의해 값이 로드되고 변경됩니다. 인터럽트가 발생하면 eip/ip 레지스터도 수정됩니다. 43. 마이크로프로세서 시스템 레지스터 이러한 레지스터의 이름은 시스템에서 특정 기능을 수행함을 나타냅니다. 시스템 레지스터의 사용은 엄격하게 규제됩니다. 보호 모드를 제공하는 것은 바로 그들입니다. 그들은 또한 자격을 갖춘 시스템 프로그래머가 가장 낮은 수준의 작업을 수행할 수 있도록 의도적으로 보이게 남겨둔 마이크로프로세서 아키텍처의 일부로 생각할 수 있습니다. 시스템 레지스터는 세 그룹으로 나눌 수 있습니다. 1) XNUMX개의 제어 레지스터; 제어 레지스터 그룹에는 4개의 레지스터가 포함됩니다. ▪ cr0; ▪ cr1; ▪ cr2; ▪ cr3; 2) XNUMX개의 시스템 주소 레지스터(메모리 관리 레지스터라고도 함); 시스템 주소 레지스터에는 다음 레지스터가 포함됩니다. ▪ 전역 설명자 테이블 레지스터 gdtr; ▪ 로컬 설명자 테이블 레지스터 Idtr; ▪ 인터럽트 설명자 테이블 레지스터 idtr; ▪ 16비트 작업 레지스터 tr; 3) XNUMX개의 디버그 레지스터. 여기에는 다음이 포함됩니다. ▪ dr0; ▪ dr1; ▪ dr2; ▪ dr3; ▪ dr4; ▪ dr5; ▪ dr6; ▪ dr7. 시스템 레지스터에 대한 지식은 어셈블리에서 프로그램을 작성하는 데 필요하지 않습니다. 이는 주로 가장 낮은 수준의 작업을 구현하는 데 사용되기 때문입니다. 그러나 소프트웨어 개발의 현재 경향(특히 인간 코드보다 효율성이 월등한 코드를 종종 생성하는 고급 언어의 최신 컴파일러의 최적화 기능이 크게 향상됨을 감안할 때)은 가장 낮은 수준의 문제를 해결하는 것으로 어셈블러의 범위를 좁힙니다. 위의 레지스터에 대한 지식이 매우 유용할 수 있는 레벨 문제. 44. 제어 레지스터 제어 레지스터 그룹에는 0개의 레지스터(cr1, cr2, cr3, cr0)가 포함됩니다. 이 레지스터는 일반적인 시스템 제어를 위한 것입니다. 제어 레지스터는 권한 수준이 XNUMX인 프로그램에서만 사용할 수 있습니다. 마이크로프로세서에는 1개의 제어 레지스터가 있지만 그 중 XNUMX개만 사용할 수 있습니다. crXNUMX은 제외되고 기능은 아직 정의되지 않았습니다(나중에 사용하기 위해 예약됨). cr0 레지스터에는 마이크로프로세서의 작동 모드를 제어하고 수행 중인 특정 작업에 관계없이 해당 상태를 전역적으로 반영하는 시스템 플래그가 포함되어 있습니다. 시스템 플래그의 목적: 1) pe(보호 활성화), 비트 0 - 보호 모드 활성화. 이 플래그의 상태는 두 가지 모드(실제(pe = 0) 또는 보호됨(pe = 1)) 중 어느 모드에서 마이크로프로세서가 주어진 시간에 작동하는지 나타냅니다. 2) mp(Math Present), 비트 1 - 보조 프로세서의 존재. 항상 1; 3) ts(작업 전환), 비트 3 - 작업 전환. 프로세서는 다른 작업으로 전환할 때 이 비트를 자동으로 설정합니다. 4) am(정렬 마스크), 비트 18 - 정렬 마스크. 이 비트는 정렬 제어를 활성화(am = 1)하거나 비활성화(am = 0)합니다. 5) cd(캐시 비활성화), 비트 30 - 캐시 메모리 비활성화. 이 비트를 사용하여 내부 캐시(첫 번째 수준 캐시)의 사용을 비활성화(cd = 1)하거나 활성화(cd = 0)할 수 있습니다. 6) pg(PaGing), 비트 31 - 페이징을 활성화(pg = 1)하거나 비활성화(pg = 0)합니다. 플래그는 메모리 구성의 페이징 모델에서 사용됩니다. cr2 레지스터는 현재 명령어가 현재 메모리에 없는 메모리 페이지에 포함된 주소에 액세스했을 때 상황을 등록하기 위해 RAM 페이징에서 사용됩니다. 이러한 상황에서 예외 번호 14가 마이크로 프로세서에서 발생하고 이 예외를 일으킨 명령어의 선형 32비트 주소가 레지스터 cr2에 기록됩니다. 이 정보를 사용하여 예외 핸들러(14)는 원하는 페이지를 결정하고 이를 메모리로 교체하고 프로그램의 정상 작동을 재개합니다. cr3 레지스터는 페이징 메모리에도 사용됩니다. 이것은 소위 20단계 페이지 디렉토리 레지스터입니다. 여기에는 현재 작업 페이지 디렉터리의 1024비트 물리적 기본 주소가 포함됩니다. 이 디렉토리에는 32개의 1024비트 디스크립터가 포함되어 있으며 각 디스크립터에는 두 번째 레벨 페이지 테이블의 주소가 포함되어 있습니다. 차례로, 두 번째 레벨 페이지 테이블 각각은 메모리의 페이지 프레임을 지정하는 32개의 4비트 설명자를 포함합니다. 페이지 프레임 크기는 XNUMXKB입니다. 45. 시스템 주소 레지스터 이러한 레지스터를 메모리 관리 레지스터라고도 합니다. 마이크로프로세서의 멀티태스킹 모드에서 프로그램과 데이터를 보호하도록 설계되었습니다. 마이크로프로세서 보호 모드에서 작동할 때 주소 공간은 다음과 같이 나뉩니다. 1) 전역 - 모든 작업에 공통입니다. 2) 로컬 - 각 작업에 대해 분리됩니다. 이 분리는 마이크로프로세서 아키텍처에서 다음 시스템 레지스터의 존재를 설명합니다. 1) 48비트 크기를 갖고 GDT 글로벌 디스크립터 테이블의 32비트(비트 16-47) 기본 주소와 16비트(비트)를 포함하는 글로벌 디스크립터 테이블 gdtr(글로벌 디스크립터 테이블 레지스터)의 레지스터 0-15) GDT 테이블의 바이트 크기인 한계값; 2) 16비트 크기를 갖고 로컬 디스크립터 테이블 LDT의 소위 디스크립터 선택기를 포함하는 로컬 디스크립터 테이블 레지스터 ldtr(로컬 디스크립터 테이블 레지스터). 이 선택자는 로컬 디스크립터 테이블 LDT를 포함하는 세그먼트를 설명하는 GDT에 대한 포인터입니다. 3) 인터럽트 디스크립터 테이블 idtr(인터럽트 디스크립터 테이블 레지스터)의 레지스터, 크기가 48비트이고 IDT 인터럽트 디스크립터 테이블의 32비트(비트 16-47) 기본 주소와 16비트(비트)를 포함합니다. 0-15) IDT 테이블의 바이트 크기인 한계값; 4) 16비트 작업 레지스터 tr(작업 레지스터)은 ldtr 레지스터와 마찬가지로 선택기, 즉 GDT 테이블의 설명자에 대한 포인터를 포함합니다. 이 설명자는 현재 TSS(Task Segment Status)를 설명합니다. 이 세그먼트는 시스템의 각 작업에 대해 생성되고 엄격하게 규제되는 구조를 가지며 작업의 컨텍스트(현재 상태)를 포함합니다. TSS 세그먼트의 주요 목적은 다른 작업으로 전환하는 순간 작업의 현재 상태를 저장하는 것입니다. 46. 디버그 레지스터 이것은 하드웨어 디버깅을 위한 매우 흥미로운 레지스터 그룹입니다. 하드웨어 디버깅 도구는 i486 마이크로프로세서에 처음 등장했습니다. 하드웨어에서 마이크로프로세서에는 XNUMX개의 디버그 레지스터가 포함되어 있지만 실제로는 그 중 XNUMX개만 사용됩니다. dr0, dr1, dr2, dr3 레지스터는 32비트 너비를 가지며 0개 중단점의 선형 주소를 설정하도록 설계되었습니다. 이 경우에 사용되는 메커니즘은 다음과 같습니다. 현재 프로그램에 의해 생성된 모든 주소는 레지스터 dr3...dr1의 주소와 비교되고, 일치하는 경우 번호 XNUMX의 디버깅 예외가 생성됩니다. 레지스터 dr6을 디버그 상태 레지스터라고 합니다. 이 레지스터의 비트는 마지막 예외 번호 1이 발생한 이유에 따라 설정됩니다. 우리는 이러한 비트와 그 목적을 나열합니다. 1) b0 - 이 비트가 1로 설정되면 레지스터 dr0에 정의된 체크포인트에 도달한 결과로 마지막 예외(인터럽트)가 발생했습니다. 2) b1 - b0과 유사하지만 레지스터 dr1의 체크포인트용입니다. 3) b2 - b0과 유사하지만 레지스터 dr2의 체크포인트용입니다. 4) b3 - b0과 유사하지만 레지스터 dr3의 체크포인트용입니다. 5) bd(비트 13) - 디버그 레지스터를 보호하는 역할을 합니다. 6) bs(비트 14) - 예외 1이 플래그 레지스터의 플래그 tf = 1 상태로 인해 발생한 경우 1로 설정됩니다. 7) TSS t = 15로 설정된 트랩 비트를 사용하여 작업으로 전환하여 예외 1이 발생한 경우 bt(비트 1)는 1로 설정됩니다. 이 레지스터의 다른 모든 비트는 1으로 채워집니다. 예외 처리기 6은 drXNUMX의 내용을 기반으로 예외가 발생한 이유를 확인하고 필요한 조치를 취해야 합니다. 레지스터 dr7을 디버그 제어 레지스터라고 합니다. 여기에는 인터럽트가 생성되어야 하는 다음 조건을 지정할 수 있는 XNUMX개의 디버그 중단점 레지스터 각각에 대한 필드가 포함되어 있습니다. 1) 체크포인트 등록 위치 - 현재 작업 또는 모든 작업에서만. 이 비트는 레지스터 dr8의 하위 7비트(각각 레지스터 dr2, drl, dr0, dr2에 의해 설정된 각 중단점(실제로는 중단점)에 대해 3비트)를 차지합니다. 각 쌍의 첫 번째 비트는 소위 로컬 해상도입니다. 이를 설정하면 현재 작업의 주소 공간 내에 있는 경우 중단점이 적용되도록 지시합니다. 각 쌍의 두 번째 비트는 지정된 중단점이 시스템의 모든 작업 주소 공간 내에서 유효함을 나타내는 전역 권한을 지정합니다. 2) 인터럽트가 시작되는 액세스 유형: 명령을 가져올 때, 쓸 때 또는 데이터를 쓰거나 읽을 때만. 인터럽트 발생의 이러한 특성을 결정하는 비트는 이 레지스터의 상단에 있습니다. 대부분의 시스템 레지스터는 프로그래밍 방식으로 액세스할 수 있습니다. 47. 어셈블러의 프로그램 구조 어셈블리 언어 프로그램은 메모리 세그먼트라고 하는 메모리 블록 모음입니다. 프로그램은 이러한 블록 세그먼트 중 하나 이상으로 구성될 수 있습니다. 각 세그먼트에는 언어 문장 모음이 포함되어 있으며 각 문장은 별도의 프로그램 코드 행을 차지합니다. 어셈블리 문에는 네 가지 유형이 있습니다. 기계 명령어의 상징적인 대응물인 명령어 또는 명령어. 번역 과정에서 어셈블리 명령어는 마이크로프로세서 명령어 세트의 해당 명령어로 변환됩니다. 일반적으로 하나의 어셈블러 명령어는 하나의 마이크로프로세서 명령어에 해당하며 일반적으로 저수준 언어에 일반적입니다. 다음은 eax 레지스터에 저장된 이진수를 XNUMX씩 증가시키는 명령어의 예입니다. Inc eax ▪ 매크로 명령 - 특정 방식으로 형식이 지정된 프로그램 텍스트 문장으로, 방송 중에 다른 문장으로 대체됩니다. 매크로의 예는 다음과 같은 프로그램 종료 매크로입니다. 매크로 종료 movax,4c00h int 21h 엔드엠 ▪ 특정 작업을 수행하도록 어셈블러 변환기에 지시하는 지시문. 지시문에는 기계 표현에 대응하는 것이 없습니다. 예를 들어 다음은 목록 파일의 제목을 설정하는 TITLE 지시문입니다. %TITLE "Listing 1" ▪ 러시아어 알파벳 문자를 포함한 모든 문자를 포함하는 주석 라인. 번역자는 댓글을 무시합니다. 예: ; 이 줄은 주석입니다 48. 어셈블리 구문 프로그램을 구성하는 문장은 명령, 매크로, 지시문 또는 주석에 해당하는 구문 구조일 수 있습니다. 어셈블러 번역기가 이를 인식하려면 특정 구문 규칙에 따라 구성되어야 합니다. 이렇게 하려면 문법 규칙과 같이 언어 구문에 대한 형식적인 설명을 사용하는 것이 가장 좋습니다. 이러한 방식으로 프로그래밍 언어를 설명하는 가장 일반적인 방법은 구문 다이어그램과 확장된 Backus-Naur 형식입니다. 구문 다이어그램으로 작업할 때 화살표로 표시된 순회 방향에 주의하십시오. 구문 다이어그램은 프로그램의 입력 문장을 구문 분석할 때 번역기의 논리를 반영합니다. 유효한 문자: 1) 모든 라틴 문자: A - Z, a - z; 2) 0에서 9까지의 숫자; 3) 징후? @, $, &; 4) 분리기. 토큰은 다음과 같습니다. 1. 식별자 - 작업 코드, 변수 이름 및 레이블 이름을 지정하는 데 사용되는 유효한 문자 시퀀스입니다. 식별자는 숫자로 시작할 수 없습니다. 2. 일련의 문자 - 작은따옴표 또는 큰따옴표로 묶인 일련의 문자입니다. 3. 정수. 가능한 유형의 어셈블러 명령문. 1. 산술 연산자. 여기에는 다음이 포함됩니다. 1) 단항 "+" 및 "-"; 2) 이진 "+" 및 "-"; 3) 곱셈 "*"; 4) 정수 나누기 "/"; 5) "mod" 분할의 나머지 부분을 얻습니다. 2. 시프트 연산자는 지정된 비트 수만큼 표현식을 이동합니다. 3. 비교 연산자("true" 또는 "false" 반환)는 논리식을 형성하도록 설계되었습니다. 4. 논리 연산자는 표현식에 대해 비트 연산을 수행합니다. 5. 인덱스 연산자 []. 6. ptr 유형 재정의 연산자는 표현식에 의해 정의된 레이블 또는 변수의 유형을 재정의하거나 한정하는 데 사용됩니다. 7. 세그먼트 재정의 연산자 ":"(콜론)는 지정된 세그먼트 구성 요소에 대해 상대적으로 물리적 주소가 계산되도록 합니다. 8. 구조 유형 명명 연산자 "." (점)은 또한 표현식에서 발생하는 경우 컴파일러가 특정 계산을 수행하도록 합니다. 9. 표현식 seg 주소의 세그먼트 구성요소를 얻기 위한 연산자는 레이블, 변수, 세그먼트 이름, 그룹 이름 또는 일부 기호 이름이 될 수 있는 표현식에 대한 세그먼트의 물리적 주소를 반환합니다. 10. 표현식 오프셋의 오프셋을 얻기 위한 연산자를 사용하면 표현식이 정의된 세그먼트의 시작 부분을 기준으로 표현식 오프셋 값을 바이트 단위로 가져올 수 있습니다. 49. 분할 지시문 분할은 모듈식 프로그래밍 개념과 관련된 보다 일반적인 메커니즘의 일부입니다. 여기에는 다른 프로그래밍 언어의 모듈을 포함하여 컴파일러에서 만든 개체 모듈의 디자인 통합이 포함됩니다. 이를 통해 다른 언어로 작성된 프로그램을 결합할 수 있습니다. SEGMENT 지시문의 피연산자가 의도된 것은 이러한 공용체에 대한 다양한 옵션의 구현을 위한 것입니다. 그들을 더 자세히 고려하십시오. 1. 세그먼트 정렬 속성(정렬 유형)은 링커에게 세그먼트의 시작이 지정된 경계에 놓이도록 지시합니다. 1) BYTE - 정렬이 수행되지 않습니다. 2) WORD - 세그먼트는 0의 배수인 주소에서 시작합니다. 즉, 물리적 주소의 마지막(최하위) 비트는 XNUMX(단어 경계에 맞춰 정렬됨)입니다. 3) DWORD - 세그먼트는 XNUMX의 배수인 주소에서 시작합니다. 4) PARA - 세그먼트가 16의 배수인 주소에서 시작합니다. 5) PAGE - 세그먼트는 256의 배수인 주소에서 시작합니다. 6) MEMPAGE - 세그먼트는 4KB의 배수인 주소에서 시작합니다. 2. 결합 세그먼트 속성(결합 유형)은 링커에 동일한 이름을 가진 서로 다른 모듈의 세그먼트를 결합하는 방법을 알려줍니다. 1) PRIVATE - 세그먼트는 이 모듈 외부의 동일한 이름을 가진 다른 세그먼트와 병합되지 않습니다. 2) PUBLIC - 링커가 동일한 이름을 가진 모든 세그먼트를 연결하도록 합니다. 3) COMMON - 같은 주소에 같은 이름을 가진 모든 세그먼트가 있습니다. 4) AT xxxx - 단락의 절대 주소에서 세그먼트를 찾습니다. 5) STACK - 스택 세그먼트의 정의. 3. 세그먼트 클래스 속성(클래스 유형)은 여러 모듈 세그먼트에서 프로그램을 조합할 때 링커가 적절한 세그먼트 순서를 결정하는 데 도움이 되는 따옴표 붙은 문자열입니다. 4. 세그먼트 크기 속성: 1) USE16 - 세그먼트가 16비트 주소 지정을 허용함을 의미합니다. 2) USE32 - 세그먼트는 32비트입니다. 불가능을 보완할 방법이 필요합니다. 세그먼트의 배치 및 조합을 직접 제어합니다. 이를 위해 MODEL 메모리 모델을 지정하는 지시문을 사용하기 시작했습니다. 이 지시문은 단순화된 분할 지시어를 사용하는 경우 미리 정의된 이름을 가진 세그먼트를 세그먼트 레지스터와 함께 바인딩합니다(단, ds를 명시적으로 초기화해야 함). MODEL 지시문의 필수 매개변수는 메모리 모델입니다. 이 매개변수는 POU에 대한 메모리 분할 모델을 정의합니다. 프로그램 모듈은 앞에서 언급한 단순화된 세그먼트 설명 지시문에 의해 정의된 특정 유형의 세그먼트만 가질 수 있다고 가정합니다. 50. 기계 명령어 구조 기계 명령은 특정 규칙에 따라 인코딩된 마이크로프로세서에 대한 명령으로 일부 작업이나 작업을 수행합니다. 각 명령에는 다음을 정의하는 요소가 포함되어 있습니다. 1) 무엇을 할 것인가? 2) 무언가를 수행해야 하는 객체(이 요소를 피연산자라고 함) 3) 어떻게 할까? 기계 명령어의 최대 길이는 15바이트입니다. 1. 접두사. 각각 1바이트이거나 생략될 수 있는 선택적 기계 명령 요소입니다. 메모리에서 접두사는 명령보다 우선합니다. 접두사의 목적은 명령이 수행하는 작업을 수정하는 것입니다. 애플리케이션은 다음 유형의 접두사를 사용할 수 있습니다. 1) 세그먼트 대체 접두사; 2) 주소 비트 길이 접두사는 주소 비트 길이(32비트 또는 16비트)를 지정합니다. 3) 피연산자 비트 너비 접두사는 주소 비트 너비 접두사와 유사하지만 명령이 작동하는 피연산자 비트 길이(32비트 또는 16비트)를 나타냅니다. 4) 반복 접두사는 연결된 명령과 함께 사용됩니다. 2. 작업 코드. 명령에 의해 수행되는 작업을 설명하는 필수 요소입니다. 3. 주소 지정 모드 바이트 modr/m. 이 바이트의 값은 사용되는 피연산자 주소 형식을 결정합니다. 피연산자는 하나 또는 두 개의 레지스터에 있는 메모리에 있을 수 있습니다. 피연산자가 메모리에 있는 경우 modr/m 바이트는 구성 요소(오프셋, 기본 및 인덱스 레지스터)를 지정합니다. 유효 주소를 계산하는 데 사용됩니다. modr/m 바이트는 세 개의 필드로 구성됩니다. 1) mod 필드는 피연산자의 주소가 명령어에서 차지하는 바이트 수를 결정합니다. 2) reg/cop 필드는 첫 번째 피연산자 대신 명령에 위치한 레지스터 또는 opcode의 가능한 확장을 결정합니다. 3) r/m 필드는 mod 필드와 함께 사용되며 첫 번째 피연산자(mod = 11인 경우) 위치의 명령에 있는 레지스터 또는 유효 주소를 계산하는 데 사용되는 기본 및 인덱스 레지스터를 결정합니다. (명령의 오프셋 필드와 함께). 4. 바이트 스케일 - 인덱스 - 기본(바이트 sib). 피연산자 주소 지정 가능성을 확장하는 데 사용됩니다. sib 바이트는 세 개의 필드로 구성됩니다. 1) 스케일 필드 ss. 이 필드는 sib 바이트의 다음 3비트를 차지하는 인덱스 구성 요소 인덱스에 대한 배율 인수를 포함합니다. 2) 인덱스 필드. 피연산자의 유효 주소를 계산하는 데 사용되는 인덱스 레지스터 번호를 저장하는 데 사용됩니다. 3) 기본 필드. 피연산자의 유효 주소를 계산하는 데에도 사용되는 기본 레지스터 번호를 저장하는 데 사용됩니다. 5. 명령의 오프셋 필드. 피연산자의 유효 주소 값을 전체적으로 또는 부분적으로(위 고려 사항에 따름) 나타내는 8, 16 또는 32비트 부호 있는 정수입니다. 6. 직접 피연산자의 필드. 8-을 나타내는 선택적 필드, 16비트 또는 32비트 직접 피연산자. 물론 이 필드의 존재는 modr/m 바이트의 값에 반영됩니다. 51. 명령어 피연산자를 지정하는 방법 피연산자는 펌웨어 수준에서 암시적으로 설정됩니다. 이 경우 명령어에는 피연산자가 명시적으로 포함되어 있지 않습니다. 명령 실행 알고리즘은 일부 기본 개체(레지스터, 플래그의 플래그 등)를 사용합니다. 피연산자는 명령어 자체에 지정됩니다(즉시 피연산자). 피연산자는 명령어 코드에 있습니다. 즉, 피연산자는 그것의 일부입니다. 이러한 피연산자를 저장하기 위해 최대 32비트 길이의 필드가 명령어에 할당됩니다. 직접 피연산자는 두 번째(소스) 피연산자만 될 수 있습니다. 대상 피연산자는 메모리 또는 레지스터에 있을 수 있습니다. 피연산자는 레지스터 중 하나에 있습니다. 레지스터 피연산자는 레지스터 이름으로 지정됩니다. 레지스터는 다음과 같이 사용할 수 있습니다. 1) 32비트 레지스터 EAX, EBX, ECX, EDX, ESI, EDI, ESP, EBP 2) 16비트 레지스터 AX, BX, CX, DX, SI, DI, SP, BP; 3) 8비트 레지스터 AH, AL, BH, BL, CH, CL, DH, D.L.; 4) 세그먼트 레지스터 CS, DS, SS, ES, FS, GS. 예를 들어 add ax,bx 명령은 레지스터 ax 및 bx의 내용을 추가하고 결과를 bx에 씁니다. dec si 명령은 si의 내용을 1만큼 감소시킵니다. 피연산자가 메모리에 있음 이것은 피연산자를 지정하는 가장 복잡하고 동시에 가장 유연한 방법입니다. 직접 및 간접의 두 가지 주요 주소 지정 유형을 구현할 수 있습니다. 차례로 간접 주소 지정에는 다음과 같은 종류가 있습니다. 1) 간접 기본 주소 지정 다른 이름은 레지스터 간접 주소 지정입니다. 2) 오프셋을 사용한 간접 기본 주소 지정 3) 오프셋을 사용한 간접 인덱스 주소 지정 4) 간접 기본 인덱스 주소 지정; 5) 오프셋을 사용한 간접 기본 인덱스 주소 지정. 피연산자는 I/O 포트입니다. RAM 주소 공간 외에도 마이크로프로세서는 I/O 장치에 액세스하는 데 사용되는 I/O 주소 공간을 유지 관리합니다. I/O 주소 공간은 64KB입니다. 주소는 이 공간의 모든 컴퓨터 장치에 할당됩니다. 이 공간 내의 특정 주소 값을 I/O 포트라고 합니다. 물리적으로 I/O 포트는 하드웨어 레지스터(마이크로프로세서 레지스터와 혼동하지 말 것)에 해당하며 특수 어셈블러 명령어를 사용하여 액세스합니다. 피연산자는 스택에 있습니다. 명령어에는 피연산자가 전혀 없을 수도 있고, 하나 또는 두 개의 피연산자가 있을 수도 있습니다. 대부분의 명령어에는 두 개의 피연산자가 필요하며 그 중 하나는 소스 피연산자이고 다른 하나는 대상 피연산자입니다. 하나의 피연산자는 레지스터나 메모리에 위치할 수 있고 두 번째 피연산자는 레지스터에 있거나 명령어에 직접 있어야 한다는 것이 중요합니다. 직접 피연산자는 소스 피연산자만 될 수 있습니다. 두 개의 피연산자 기계 명령어에서 다음과 같은 피연산자의 조합이 가능합니다. 1) 등록 - 등록; 2) 레지스터 - 메모리; 3) 메모리 - 레지스터; 4) 즉각적인 피연산자 - 레지스터 5) 즉각적인 피연산자 - 메모리. 52. 주소 지정 방법 직접 주소 지정 이것은 유효 주소가 명령어 자체에 포함되어 있고 이를 구성하는 데 추가 소스나 레지스터가 사용되지 않기 때문에 메모리에서 피연산자 주소를 지정하는 가장 간단한 형태입니다. 유효 주소는 8, 16, 32비트일 수 있는 기계 명령어 오프셋 필드에서 직접 가져옵니다. 이 값은 데이터 세그먼트에 있는 바이트, 워드 또는 더블 워드를 고유하게 식별합니다. 직접 주소 지정에는 두 가지 유형이 있습니다. 상대 직접 주소 지정 상대 점프 주소를 나타내는 조건부 점프 명령에 사용됩니다. 이러한 전환의 상대성은 기계 명령어의 오프셋 필드에 8비트, 16비트 또는 32비트 값이 포함되어 있다는 사실에 있습니다. ip/eip 명령어 포인터 레지스터 이 추가의 결과로 전환이 수행되는 주소가 얻어집니다. 절대 직접 주소 지정 이 경우 유효 주소는 기계 명령어의 일부이지만 이 주소는 명령어의 오프셋 필드 값으로만 구성됩니다. 메모리에서 피연산자의 물리적 주소를 형성하기 위해 마이크로프로세서는 4비트만큼 이동된 세그먼트 레지스터 값과 함께 이 필드를 추가합니다. 이 주소 지정의 여러 형식을 어셈블러 명령어에서 사용할 수 있습니다. 간접 기본(레지스터) 주소 지정 이 주소 지정을 사용하면 피연산자의 유효 주소가 sp / esp 및 bp / ebp를 제외한 모든 범용 레지스터에 있을 수 있습니다(이들은 스택 세그먼트 작업을 위한 특정 레지스터임). 명령에서 구문적으로 이 주소 지정 모드는 레지스터 이름을 대괄호 []로 묶어서 표현됩니다. 오프셋을 사용한 간접 기본(레지스터) 주소 지정 이 유형의 주소 지정은 이전 주소 지정에 추가된 것으로 일부 기본 주소에 대해 알려진 오프셋이 있는 데이터에 액세스하도록 설계되었습니다. 이러한 유형의 주소 지정은 프로그램 개발 단계에서 요소의 오프셋을 미리 알고 구조의 기본(시작) 주소를 동적으로 계산해야 하는 경우 데이터 구조의 요소에 액세스하는 데 사용하기에 편리합니다. 프로그램 실행 단계. 오프셋을 사용한 간접 인덱스 주소 지정 이러한 종류의 주소 지정은 오프셋을 사용한 간접 기본 주소 지정과 매우 유사합니다. 여기에서도 범용 레지스터 중 하나가 유효 주소를 형성하는 데 사용됩니다. 그러나 인덱스 주소 지정에는 배열 작업에 매우 편리한 한 가지 흥미로운 기능이 있습니다. 이는 인덱스 레지스터의 내용을 스케일링할 수 있는 가능성과 관련이 있습니다. 간접 기본 인덱스 주소 지정 이러한 유형의 주소 지정을 통해 유효 주소는 기본 및 색인이라는 두 개의 범용 레지스터 내용의 합으로 구성됩니다. 이러한 레지스터는 모든 범용 레지스터가 될 수 있으며 인덱스 레지스터 내용의 크기 조정이 자주 사용됩니다. 오프셋을 사용한 간접 기본 인덱스 주소 지정 이러한 종류의 주소 지정은 간접 인덱싱된 주소 지정의 보완입니다. 유효 주소는 기본 레지스터의 내용, 인덱스 레지스터의 내용, 명령의 오프셋 필드 값의 세 가지 구성 요소의 합으로 구성됩니다. 53. 데이터 전송 명령 일반 데이터 전송 명령 이 그룹에는 다음 명령이 포함됩니다. 1) mov는 주요 데이터 전송 명령입니다. 2) xchg - 양방향 데이터 전송에 사용됩니다. 포트 I/O 명령 기본적으로 포트를 통해 직접 장치를 관리하는 것은 쉽습니다. 1) 누산기에서 포트 번호 - 포트 번호가 있는 포트에서 누산기로 입력합니다. 2) 출력 포트, 어큐뮬레이터 - 어큐뮬레이터의 내용을 포트 번호가 있는 포트로 출력합니다. 데이터 변환 명령 많은 마이크로프로세서 명령어가 이 그룹에 속할 수 있지만 대부분은 다른 기능 그룹에 속해야 하는 특정 기능이 있습니다. 스택 명령 이 그룹은 스택을 사용하여 유연하고 효율적인 작업을 구성하는 데 중점을 둔 일련의 특수 명령입니다. 스택은 프로그램 데이터의 임시 저장을 위해 특별히 할당된 메모리 영역입니다. 스택에는 세 개의 레지스터가 있습니다. 1) ss - 스택 세그먼트 레지스터 2) sp/esp - 스택 포인터 레지스터; 3) bp/ebp - 스택 프레임 기본 포인터 레지스터. 스택 작업을 구성하기 위해 쓰기 및 읽기를 위한 특수 명령이 있습니다. 1. 소스 푸시 - 소스 값을 스택 상단에 씁니다. 2. 팝 할당 - 스택의 맨 위에서 대상 피연산자가 지정한 위치에 값을 씁니다. 따라서 값은 스택의 맨 위에서 "제거"됩니다. 3. pusha - 스택에 대한 그룹 쓰기 명령. 4. pushaw는 pusha 명령과 거의 동의어입니다. bitness 속성은 use16 또는 use32일 수 있습니다. 아르 자형 5. pushad - pusha 명령과 유사하게 수행되지만 몇 가지 특성이 있습니다. 다음 세 가지 명령은 위 명령의 역순으로 수행됩니다. 1) 포파; 2) 포포; 3) 팝. 아래에 설명된 명령어 그룹을 사용하면 스택에 플래그 레지스터를 저장하고 스택에 워드 또는 더블 워드를 쓸 수 있습니다. 1. pushf - 플래그의 레지스터를 스택에 저장합니다. 2. pushfw - 워드 크기의 플래그 레지스터를 스택에 저장합니다. 항상 use16 속성을 사용하여 pushf처럼 작동합니다. 3. pushfd - 세그먼트의 비트 너비 속성(즉, pushf와 동일)에 따라 스택에 플래그 또는 플래그 플래그 레지스터를 저장합니다. 마찬가지로 다음 세 가지 명령은 위에서 설명한 작업의 역순으로 수행합니다. 1) 팝프; 2) popfw; 3) 팝. 54. 산술 명령어 이러한 명령은 두 가지 유형에서 작동합니다. 1) 정수 이진수, 즉 이진수 시스템으로 인코딩된 숫자를 사용합니다. XNUMX진수는 XNUMX비트 그룹으로 숫자의 각 XNUMX진수를 인코딩하는 원리를 기반으로 하는 숫자 정보 표현의 특수한 유형입니다. 마이크로프로세서는 이진수 추가 규칙에 따라 피연산자의 추가를 수행합니다. 마이크로프로세서 명령어 세트에는 세 가지 이진 덧셈 명령어가 있습니다. 1) inc 피연산자 - 피연산자의 값을 늘립니다. 2) 피연산자1, 피연산자2 추가 - 더하기 3) adc 피연산자1, 피연산자2 - 캐리 플래그를 고려한 추가 cf. 부호 없는 이진수 빼기 빼기가 빼기보다 크면 그 차이는 양수입니다. 빼기가 빼기보다 작으면 문제가 있습니다. 결과는 0보다 작고 이것은 이미 부호 있는 숫자입니다. 부호 없는 숫자를 뺀 후 CF 플래그의 상태를 분석해야 합니다. 1로 설정되면 최상위 비트가 차용되고 결과가 XNUMX의 보수 코드에 있습니다. 부호가 있는 이진수 빼기 그러나 추가 코드에서 부호가 있는 숫자를 더하는 방식으로 빼기의 경우 두 피연산자(피연산자와 감수)를 모두 나타내는 것이 필요합니다. 결과는 XNUMX의 보수 값으로도 처리되어야 합니다. 그러나 여기서 어려움이 발생합니다. 먼저 피연산자의 최상위 비트를 부호 비트로 간주한다는 사실과 관련이 있습니다. 오버플로 플래그의 내용에 따르면. 1로 설정하면 결과가 이 크기의 피연산자에 대한 부호 있는 숫자 범위를 벗어났으며(즉, 최상위 비트가 변경됨) 프로그래머가 결과를 수정하기 위한 조치를 취해야 합니다. 피연산자의 표준 비트 그리드를 초과하는 표현 범위를 가진 숫자를 빼는 원리는 더하기와 동일합니다. 즉, 캐리 플래그 cf가 사용됩니다. 열에서 빼는 과정을 상상하고 마이크로프로세서 명령어를 sbb 명령어와 올바르게 결합하면 됩니다. 부호 없는 숫자를 곱하는 명령은 다음과 같습니다. 멀티 팩터_1 숫자에 부호를 곱하는 명령은 다음과 같습니다. [이멀 피연산자_1, 피연산자_2, 피연산자_3] div 제수 명령은 부호 없는 숫자를 나누는 명령입니다. idiv 제수 명령은 부호 있는 숫자를 나누는 명령입니다. 55. 논리 명령 이론에 따르면 다음과 같은 논리 연산이 명령문(비트에서)에 대해 수행될 수 있습니다. 1. 부정(논리적 NOT) - 한 피연산자에 대한 논리적 연산으로, 그 결과는 원래 피연산자 값의 역수입니다. 2. 논리적 덧셈(논리적 포함 OR) - 두 피연산자에 대한 논리적 연산으로, 하나 또는 두 피연산자가 모두 참(1)이면 결과가 "참"(1)이고 두 피연산자가 모두 참이면 "거짓"(0)입니다. 거짓(0). 3. 논리적 곱셈(논리 AND) - 두 피연산자에 대한 논리적 연산으로, 두 피연산자가 모두 참(1)인 경우에만 결과가 참(1)입니다. 다른 모든 경우에 연산 값은 "거짓"(0)입니다. 4. 논리적 배타적 덧셈(논리적 배타적 OR) - 두 피연산자 중 하나만 참(1)인 경우 결과가 "참"(1)이고 거짓(0)인 경우 두 피연산자에 대한 논리적 연산 두 피연산자는 모두 거짓(0) 또는 참(1)입니다. 4. 논리적 배타적 덧셈(논리적 배타적 OR) - 두 피연산자 중 하나만 참(1)인 경우 결과가 "참"(1)이고 거짓(0)인 경우 두 피연산자에 대한 논리적 연산 두 피연산자는 모두 거짓(0) 또는 참(1)입니다. 논리적 데이터 작업을 지원하는 다음 명령 세트: 1) 및 operand_1, operand_2 - 논리 곱셈 연산; 2) 또는 operand_1, operand_2 - 논리적 덧셈 연산; 3) xor operand_1, operand_2 - 논리적 배타적 덧셈 연산; 4) 피연산자_1 테스트, 피연산자_2 - "테스트" 연산(논리적 곱셈에 의한) 5) 피연산자가 아님 - 논리적 부정의 연산. a) 특정 숫자(비트)를 1로 설정하려면 명령 또는 operand_1, operand_2가 사용됩니다. b) 특정 숫자(비트)를 0으로 재설정하려면 명령과 operand_1, operand_2가 사용됩니다. c) 명령 xor operand_1, operand_2가 적용됩니다. ▪ Operand_1과 Operand_2의 어떤 비트가 다른지 확인합니다. ▪ 지정된 비트의 상태를 Operand_1로 반전합니다. 명령 test operand_1, operand_2(check operand_1)는 지정된 비트의 상태를 확인하는 데 사용됩니다. 명령의 결과는 XNUMX 플래그 zf의 값을 설정하는 것입니다. 1) zf = 0이면 논리 곱의 결과로 1 결과가 얻어졌습니다. 즉, 피연산자 XNUMX의 해당 단위 비트와 일치하지 않는 마스크의 한 단위 비트 2) zf = 1이면 논리 곱셈의 결과는 1이 아닙니다. 즉, 마스크의 최소 하나의 단위 비트가 OperandXNUMX의 해당 XNUMX비트와 일치합니다. 모든 시프트 명령어는 opcode에 따라 피연산자 필드의 비트를 왼쪽이나 오른쪽으로 이동합니다. 모든 시프트 명령어는 동일한 구조(cop 피연산자, 시프트 카운터)를 갖습니다. 56. 제어 전송 명령 다음에 어떤 프로그램 명령을 실행해야 하는지, 마이크로프로세서는 cs의 내용에서 학습합니다. (e) ip 레지스터 쌍: 1) cs - 현재 코드 세그먼트의 물리적 주소를 포함하는 코드 세그먼트 레지스터 2) eip/ip - 명령어 포인터 레지스터, 다음에 실행될 명령어의 메모리에 있는 오프셋 값을 포함합니다. 무조건 점프 수정해야 할 사항은 다음에 따라 다릅니다. 1) 무조건 분기 명령의 피연산자 유형(근거리 또는 원거리) 2) 전환 주소 이전에 수정자를 지정하는 것; 이 경우 점프 주소 자체는 명령어(직접 점프) 또는 메모리 레지스터(간접 점프)에 직접 있을 수 있습니다. 수정자 값: 1) ptr 근처 - 레이블로 직접 전환; 2) far ptr - 다른 코드 세그먼트의 레이블로 직접 전환 3) 단어 ptr - 레이블로의 간접 전환; 4) dword ptr - 다른 코드 세그먼트의 레이블로의 간접 전환. jmp 무조건 점프 명령 jmp [수정자] jump_address 프로시저 또는 서브루틴은 일부 작업 분해의 기본 기능 단위입니다. 프로시저는 명령 그룹입니다. 조건부 점프 마이크로프로세서에는 18개의 조건부 점프 명령이 있습니다. 이러한 명령을 통해 다음을 확인할 수 있습니다. 1) 부호 있는 피연산자 간의 관계("더 많을수록 적음") 2) 부호 없는 피연산자 간의 관계 ("더 높게 더 낮게"); 3) 산술 플래그 ZF, SF, CF, OF, PF(그러나 AF는 아님)의 상태. 조건부 점프 명령어의 구문은 다음과 같습니다. jcc jump label cmp compare 명령에는 흥미로운 작동 방식이 있습니다. 뺄셈 명령인 sub operand_1, operand_2와 정확히 동일합니다. cmp 명령은 하위 명령과 마찬가지로 피연산자를 빼고 플래그를 설정합니다. 하지 않는 유일한 것은 첫 번째 피연산자 대신 빼기 결과를 쓰는 것입니다. cmp 명령 구문 - cmp operand_1, operand_2(비교) - 두 피연산자를 비교하고 비교 결과에 따라 플래그를 설정합니다. 주기의 구성 예를 들어 제어 명령의 조건부 전송 또는 무조건 점프 명령 jmp를 사용하여 프로그램의 특정 섹션의 주기적 실행을 구성할 수 있습니다. 1) 루프 전환 레이블(Loop) - 루프를 반복합니다. 이 명령을 사용하면 루프 카운터의 자동 감소를 사용하여 고급 언어의 for 루프와 유사한 루프를 구성할 수 있습니다. 2) 루프/루프즈 점프 라벨 loope 및 loopz 명령은 절대 동의어입니다. 3) loopne/loopnz 점프 레이블 명령 loopne 및 loopnz도 절대 동의어입니다. loope/loopz 및 loopne/loopnz 명령은 상호 작용합니다. 저자: Tsvetkova A.V.
▪ XNUMX세기 러시아 문학을 간략히 소개합니다. 어린이 침대
세계 최고 높이 천문대 개관
04.05.2024 기류를 이용한 물체 제어
04.05.2024 순종 개는 순종 개보다 더 자주 아프지 않습니다.
03.05.2024
▪ 깃털 플라스틱
▪ 기사 군사 교육 기관에 대한 준비 및 입학 순서. 안전한 생활의 기본 ▪ 기사 너무 마른 톱 모델의 근무를 금지하는 나라는? 자세한 답변 ▪ 스피커 디자인 기사. 무선 전자 및 전기 공학 백과사전 ▪ 기사 엘리베이터의 전기 장비. 운전실에 전기 배선 및 전원 공급. 무선 전자 및 전기 공학 백과사전
홈페이지 | 도서관 | 조항 | 사이트 맵 | 사이트 리뷰
www.diagram.com.ua |



 다른 기사 보기 섹션
다른 기사 보기 섹션 